THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
We propose to extend the fetch protocol to allow consumer fetching from any replica. Just as when fetching from the leader, the replication protocol will guarantee that only committed data is returned to the consumer. This relies on propagation of the high watermark through the leader's fetch response. Due to this propagation delay, follower fetching may have higher latency. Additionally, follower fetching introduces the possibility of spurious out of range errors if a fetch is received by an out-of-sync replica. The diagram below will help to make this clearerillustrates the different cases that are possible.
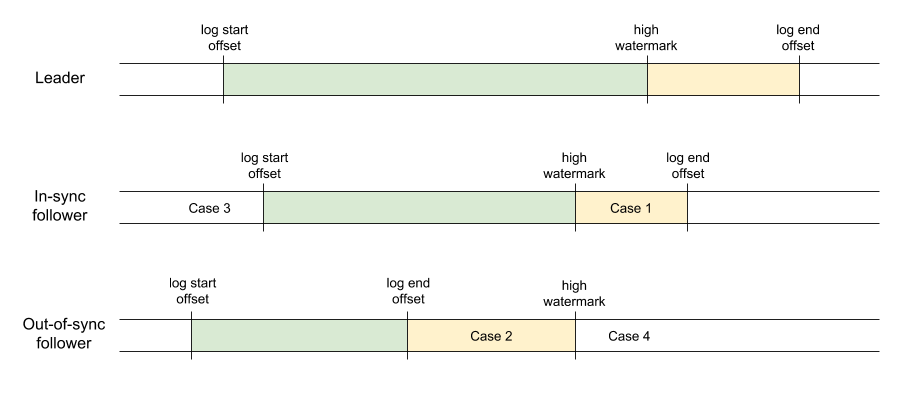
In this diagram, the green portion of the log represents the records that are both available locally on the replica and known to be committed. These records can be safely returned to consumers at any time. The yellow portion represents the records which are either not available locally or not known to be committed (i.e. it has they have not been successfully replicated to all members of the ISR). These records cannot be returned until the high watermark is known to have advanced.
The leader always sees high watermark updates before any of the replicas. An in-sync replica may therefore have some committed data which is not yet available for consumption. In the case of an out-of-sync replica, the high watermark is typically above its log end offset, so there may be some committed data which is not yet locally available.
Note that the log start offsets are not consistently maintained between the leader and followers (even those in the ISR). This is caused by due to the fact that retention is enforced independently by each replica. We will discuss this point in more detail below.
...
We propose to change the fetch satisfaction logic to take high watermark updates into account. The leader will respond to a fetch immediately if the follower has a stale high watermark. In particular, the first request in a fetch session will not block on the leader in order to ensure that the follower has the latest high watermark for requested partitions. A side benefit of this change is that it reduces the window following a leader election in which the high watermark can be observed to go backwards must be withheld from clients in order to preserve its monotonicity (see KIP-207).
Out of range handling
The main challenge for follower fetching is that a consumer may observe a committed offset on the leader before it is available on a follower. We need to define the expected behavior if the consumer attempts to fetch a valid offset from a follower which is relying on stale log metadata.
...
Case 1 (uncommitted offset): The offset is available locally on the replica receiving the fetch, but is not known to be committed. In fact, the broker already has logic to handle this case. When a replica is elected leader, it does not know what the true value of the high watermark should be until it receives fetches from the current ISR. If a consumer fetches at an offset between the last updated high watermark value and the log end offset, then the broker currently returns an empty record set. This ensures that no records are returned until they are known to be committed.
...
Finding the preferred follower
The consumer needs to have some logic to determine which replicas in the ISR should be preferred for fetching. It is difficult to make this logic general for all use cases because there could be many factors at play. For example, a user may wish to take into account the dollar cost of the link, the available bandwidth, the proximity to the consumer, load balancing, etc. We therefore propose to make this logic pluggable through the ReplicaSelector interface. This will be exposed to the consumer with the replica.selector.class configuration. If no selector is provided (the default), then the consumer will follow the current model of fetching only from the leader.
The ReplicaSelector will get invoked on every metadata update, whether or not there are any changes. Users can tune `metadata.max.age.ms` in order to ensure that the consumer does not stay stuck to an out-of-sync replica for too long.
Public Interfaces
Protocol Changes
The FetchRequest schema has field for the replica id. Consumers typically use the sentinel -1, which indicates that fetching is only allowed from the leader. A lesser known sentinel is -2, which was originally intended to be used for debugging and allows fetching from followers. We propose to let the consumer use this to indicate the intent to allow fetching from a follower. Similarly, when we need to send a ListOffsets request to a follower in order to find the log start offset, we will use the same sentinel for the replica id field.
It is still necessary, however, to bump the version of the Fetch request because of the use of the OFFSET_NOT_AVAILABLE error code mentioned above. The request and response schemas will not change. We will also modify the behavior of all fetch versions so that the current log start offset and high watermark are returned if the fetch offset is out of range. This allows the broker
One point that was missed in KIP-320 is the fact that the OffsetsForLeaderEpoch API exposes the log end offset. For consumers, the log end offset should be the high watermark, so we need a way for this protocol to distinguish replica and consumer requests. We propose here to add the same `replica_id` field that is used in the Fetch and ListOffsets APIs. The new schema is provided below:
| Code Block |
|---|
OffsetsForLeaderEpochRequest => [Topic]
ReplicaId => INT32 // New (-1 means consumer)
Topic => TopicName [Partition]
TopicName => STRING
Partition => PartitionId CurrentLeaderEpoch LeaderEpoch
PartitionId => INT32
CurrentLeaderEpoch => INT32
LeaderEpoch => INT32 |
When an OffsetsForLeaderEpoch request is received from a consumer, the returned offset will be limited to the high watermark. As with the Fetch API, when a leader has just been elected, the true high watermark is not known for a short time. If an OffsetsForLeaderEpoch request is received with the latest epoch during this window, the leader will respond with the OFFSET_NOT_AVAILABLE error code. This will cause the consumer to retry. Note as well that only leaders are allowed to handle OffsetsForLeaderEpoch queries.
Consumer Changes
We will expose a new plugin interface that allows the user to provide custom logic to determine the preferred replica to fetch from.
| Code Block |
|---|
interface ReplicaSelector extends Configurable, Closeable {
/**
* Select the replica to use for fetching the given partition.
* This method is invoked whenever a change to the ISR of that
* partition is observed.
*
* Note that this is only a recommendation. If the broker does
* not support follower fetching, then the consumer will fetch
* from the leader.
*/
Node select(PartitionInfo partitionInfo);
/**
* Optional custom configuration
*/
default void configure(Map<String, ?> configs) {}
/**
* Optional shutdown hook
*/
default void close() {}
} |
This will be controlled through the replica.selector.class consumer configuration. By default, the consumer will retain the current behavior of fetching only from the leader. We will have a simple LeaderSelector implementation to enable this.
...
problem for a consumer is figuring out which replica is preferred. The two options are to either let the consumer find the preferred replica itself using metadata from the brokers (i.e. rackId, host information), or to let the broker decide the preferred replica based on information from the client. We propose here to do the latter.
The benefit of letting the broker decide which replica is preferred for a client is that it can take load into account. For example, the broker can round robin between nearby replicas in order to spread the load. There are many such considerations that are possible, so we we propose to allow users to provide a ReplicaSelector plugin to the broker in order to handle the logic. This will be exposed to the broker with the replica.selector.class configuration. In order to make use of this plugin, we will extend the Metadata API so that clients can provide their own location information. In the response, the broker will indicate a preferred replica to fetch from.
Public Interfaces
Consumer API
We use of the "rack.id" configuration to identify the location of the broker, so we will add the same configuration to the consumer. This will be used in Metadata requests as documented below.
Fetching from a non-leader replica is an opt-in feature. We propose to add a second configuration "replica.selection.policy" to indicate whether the "
| Configuration Name | Valid Values | Default Value |
|---|---|---|
| rack.id | <nullable string> | null |
| replica.selection.policy | leader, preferred | leader |
Broker API
We will expose a new plugin interface configured through the "replica.selector.class" configuration that allows users to provide custom logic to determine the preferred replica to fetch from.
| Configuration Name | Valid Values | Default Value |
|---|---|---|
| replica.selector.class | class name of ReplicaSelector implementation | null |
The ReplicaSelector interface is provided below:
| Code Block |
|---|
interface ReplicaSelector extends Configurable, Closeable {
/**
* Select the replica to use for fetching the given partition.
* This method is invoked whenever a change to the ISR of that
* partition is observed.
*
* Note that this is only a recommendation. If the broker does
* not support follower fetching, then the consumer will fetch
* from the leader.
*/
Node select(String rackId, PartitionInfo partitionInfo);
/**
* Optional custom configuration
*/
default void configure(Map<String, ?> configs) {}
/**
* Optional shutdown hook
*/
default void close() {}
} |
By default, we will provide a simple implementation which uses the rackId provided by the clients and implements exact matching on the rackId from replicas.
| Code Block |
|---|
class RackAwareReplicaSelector implements ReplicaSelector {
Node select(String rackId, PartitionInfo partitionInfo) {
// if rackId is not null, iterate through the online replicas
// if one or more exists, choose a replica randomly from them
// otherwise return the current leader
}
} |
Protocol Changes
We will extend the Metadata API in order to enable selection of the preferred replica. We use of the "rack.id" configuration to identify the location of the broker, so we will add a similar configuration to the consumer.
| Code Block |
|---|
MetadataRequest => [TopicName] AllowAutoTopicCreation RackId
TopicName => STRING
AllowAutoTopicCreation => BOOLEAN
RackId => STRING // This is new |
The metadata response will indicate the preferred replica.
| Code Block |
|---|
MetadataResponse => ThrottleTimeMs Brokers ClusterId ControllerId [TopicMetadata]
ThrottleTimeMs => INT32
Brokers => [MetadataBroker]
ClusterId => NULLABLE_STRING
ControllerId => INT32
TopicMetadata => ErrorCode TopicName IsInternal [PartitionMetadata]
ErrorCode => INT16
TopicName => STRING
IsInternal => BOOLEAN
PartitionMetadata => ErrorCode PartitionId Leader LeaderEpoch Replicas ISR OfflineReplicas
ErrorCode => INT16
PartitionId => INT32
Leader => INT32
LeaderEpoch => INT32
PreferredReplica => INT32 // This is new
Replicas => [INT32]
ISR => [INT32]
OfflineReplicas => [INT32] |
The FetchRequest schema has field for the replica id. Consumers typically use the sentinel -1, which indicates that fetching is only allowed from the leader. A lesser known sentinel is -2, which was originally intended to be used for debugging and allows fetching from followers. We propose to let the consumer use this to indicate the intent to allow fetching from a follower. Similarly, when we need to send a ListOffsets request to a follower in order to find the log start offset, we will use the same sentinel for the replica id field.
It is still necessary, however, to bump the version of the Fetch request because of the use of the OFFSET_NOT_AVAILABLE error code mentioned above. The request and response schemas will not change. We will also modify the behavior of all fetch versions so that the current log start offset and high watermark are returned if the fetch offset is out of range. This allows the broker
One point that was missed in KIP-320 is the fact that the OffsetsForLeaderEpoch API exposes the log end offset. For consumers, the log end offset should be the high watermark, so we need a way for this protocol to distinguish replica and consumer requests. We propose here to add the same `replica_id` field that is used in the Fetch and ListOffsets APIs. The new schema is provided below:
| Code Block |
|---|
OffsetsForLeaderEpochRequest => [Topic]
ReplicaId => INT32 // New (-1 means consumer)
Topic => TopicName [Partition]
TopicName => STRING
Partition => PartitionId CurrentLeaderEpoch LeaderEpoch
PartitionId => INT32
CurrentLeaderEpoch => INT32
LeaderEpoch => INT32 |
When an OffsetsForLeaderEpoch request is received from a consumer, the returned offset will be limited to the high watermark. As with the Fetch API, when a leader has just been elected, the true high watermark is not known for a short time. If an OffsetsForLeaderEpoch request is received with the latest epoch during this window, the leader will respond with the OFFSET_NOT_AVAILABLE error code. This will cause the consumer to retry. Note as well that only leaders are allowed to handle OffsetsForLeaderEpoch queries.
Compatibility, Deprecation, and Migration Plan
This change is backwards compatible with previous versions. If the broker does not support follower fetching, we the consumer will revert to the old behavior of fetching from the leader.
...