THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
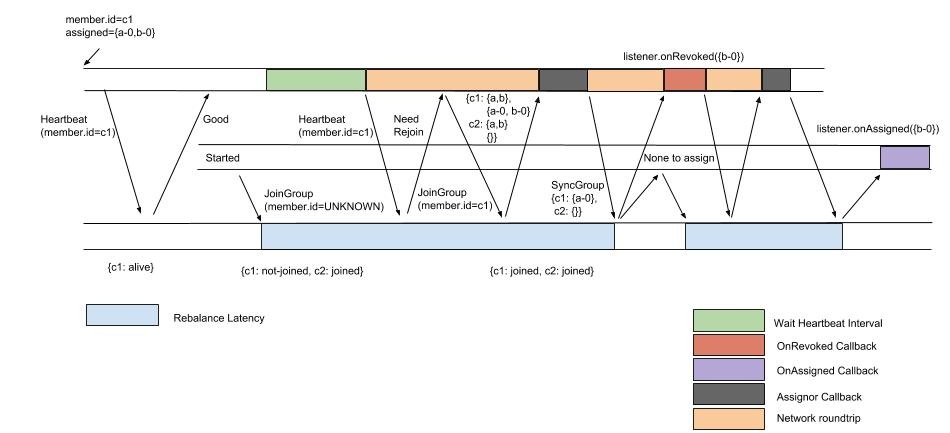
Now the new process for the same new-member-joining example becomes the following under the new protocol (note that on the existing member we will now only call revoke on b-0 once, and no longer revoking both a-0 and b-0 and then later assigning a-0 again:
Rebalance Callback Error Handling
Today, when a user customized rebalance listener callback throws an exception, as long as it is not WakeupException / InteruptException it will be swallowed and logged with an error. This has been complained by our users that it was not an efficient way for notifying them when it happened (
| Jira | ||||||
|---|---|---|---|---|---|---|
|
In this KIP, we propose to change this behavior as well: when the listener callback throws an exception, ConsumerCoordinator will log an error, and then rethrows this exception all the way up to KafkaConsumer.poll(); at the same time, the consumer coordinator's book-kept owned partitions will exclude this partition from its intended behavior, either for revocation / assignment / lost.
Upon capturing the error, users can do the following depend on their exception handling logic:
- Shutdown the consumer gracefully if the exception is considered a fatal error.
- Retry consumer.poll() if they believe the exception is re-triable, be aware that it will be treated as if no side-effects are taken at all from the exception-thrown callback: e.g. if your rebalance listener did some side-effect and then throws, it will still be considered as no-op if consumer.poll() is retried.
To give a concrete example, suppose your current assigned partitions are {1,2}, and the newly assigned partitions are {2,3}, the consumer will call onPartitionsAssigned(3) and onPartitionsRevoked(1). Suppose the former succeeds but the latter failed with an error and user captured it in consumer.poll and retry, we just let the consumer to proceed as assign with {1, 2, 3} since the 3 is added successfully but 1 is revoked unsuccessfully – i.e. we consider none of the effects take place in the exception-thrown onPartitionsRevoked(1).
Consumer StickyAssignor
Since we've already encoded the assigned partitions at the consumer protocol layer, for consumer's sticky partitioner we are effectively duplicating this data at both consumer protocol and assignor's user data. Similarly we have a StreamsPartitionAssignor which is sticky as well but relying on its own user data to do it. We can bump up their versions while simplifying the user-data and leverage on the Subscription#ownedPartitions instead (details about the upgrade compatibility below).
...
| Code Block | ||
|---|---|---|
| ||
public enum RebalanceStrategy {
EAGER((byte) 0), COOPERATIVE((byte) 1);
private final byte id;
RebalanceStrategy(byte id) {
this.id = id;
}
public byte id() {
return id;
}
public static RebalanceStrategy forId(byte id) {
switch (id) {
case 0:
return EAGER;
case 1:
return COOPERATIVE;
default:
throw new IllegalArgumentException("Unknown strategy id: " + id);
}
}
}
class PartitionAssignorProtocol {
String name; // same semantics as the deprecated PartitionAssingor#name();
RebalanceStrategy supportedStrategy;
}
interface PartitionAssignor {
// existing interfaces
short version(); // new API, the version of the assignor which indicate the user metadata / algorithmic difference.
@Deprecated; // use supportedProtocolPartitionAssignorProtocol#name instead
String name();
List<PartitionAssignorProtocol> supportedProtocols(); // new API, indicate the ConsumerCoordinator which rebalance strategy it would work with;
// and associate the protocol with a unique name of the assignor.
class Subscription {
public Short version(); // new API, and current version == 2
public List<String> topics();
public List<TopicPartition> ownedPartitions(); // new API, if version < 2 should always be empty
public ByteBuffer userData();
}
class Assignment {
public Short version(); // new API, same as above
public List<TopicPartition> partitions();
public ConsumerProtocol.Errors error(); // new API, if version < 2 should always be NONE
public ByteBuffer userData();
}
} |
...
| Code Block | ||
|---|---|---|
| ||
"rebalance.protocolstrategy": type: Enum values: {eager, compatible, cooperative} default: eager |
When the config value is "eager", the consumer would still execute the old rebalance behavior (i.e. revoke everything before joining the group); if the config value is "cooperative", the consumer will then use the new protocol. However, it needs to make sure that the instantiated assignor can work with whatever the protocol it chose by calling PartitionAssignor#supportedProtocols and try to use the corresponding name (if it is supported) of the selected protocol. When the config value is "compatible", the the logic would be a bit complicated: 1) it will still use "eager" consumer coordinator behavior, but 2) it will try to encode two assignor protocols in the subscription if the assignor supports it (i.e. its supportedProtocols have both).
The user's upgrade behavior to leverage this cooperative rebalance from 2.2 and older to newer versions would be (assuming it was "range" before the upgrade):
...
The key point behind this two rolling bounce and the additional check is that, we want to avoid the situation where leader is on old byte-code and only recognize "eager", but due to compatibility would still be able to deserialize the new protocol data from newer versioned members, and hence just go ahead and do the assignment while new versioned members did not revoke their partitions before joining the group. Note the difference with KIP-415 here: since on consumer we do not have the luxury to leverage on list of built-in assignors since it is user-customizable and hence would be black box to the consumer coordinator, we'd need two rolling bounces instead of one rolling bounce to complete the upgrade, whereas Connect only need one rolling bounce (details below).
...