THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
Gliffy Diagram name JohnWorkflow pagePin 811
- One optimization possibility is to materialize the data provided to the original node at Step 6. This would allow for changes to an event in This KTable which does not change the foreign key to shortcut sending an event to the Other node. The tradeoff is the need to maintain a materialized state store.
...
Implementing a CombinedKeySerde depends on the specific framework with json. A full key would look like this "{ "a" :{ "key":"a1" }, "b": {"key":"b5" } }" to generate a true prefix one had to generate "{ "a" :{ "key":"a1"", which is not valid json. This invalid Json will not leave the jvm but it might be more or less tricky to implement a serializer generating it. Maybe we could provide users with a utility method to make sure their serde statisfies our invariants.
Proposed Changes
Goal
With the two relations A,B and there is one A for each B and there may be many B's for each A. A is represented by the KTable the method described above gets invoked on, while B is represented by that methods first argument. We want to implement a Set of processors that allows a user to create a new KTable where A and B are joined based on the reference to A in B. A and B are represented as KTable B being partitioned by B's key and A being partitioned by A's key.
Algorithm
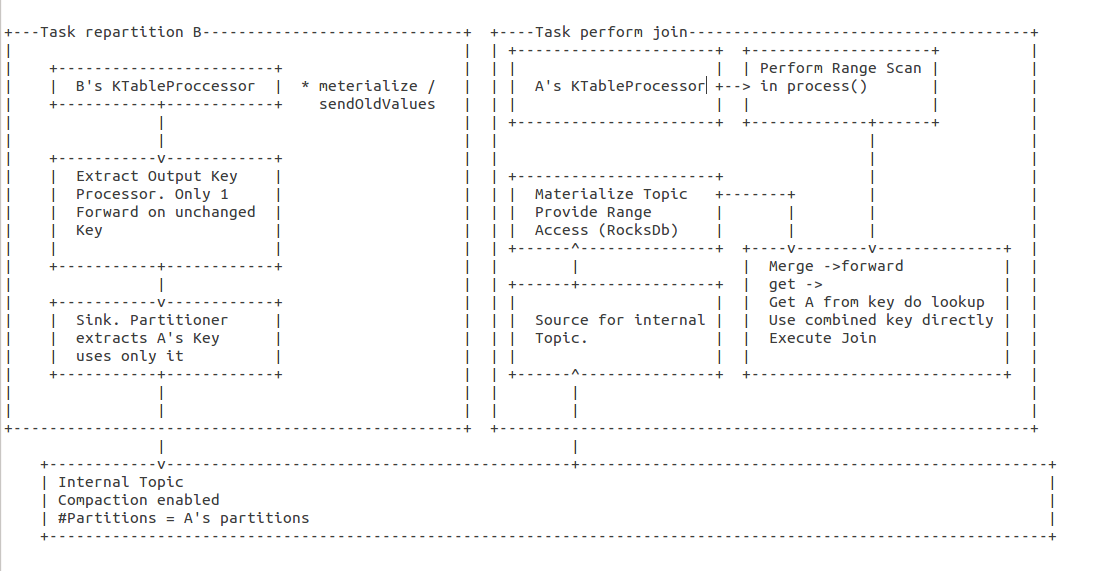
- Call enable sendOldValues() on sources with "*"
- Register a child of B
- extract A's key and B's key as key and B as value.
- forward(key, null) for old
- forward(key, b) for new
- skip old if A's key didn't change (ends up in same partition)
- extract A's key and B's key as key and B as value.
- Register sink for internal repartition topic (number of partitions equal to A, if a is internal prefer B over A for deciding number of partitions)
- in the sink, only use A's key to determine partition
- Register source for intermediate topic
- co-partition with A's sources
- materialize
- serde for rocks needs to serialize A before B. ideally we use the same serde also for the topic
- Register processor after above source.
- On event extract A's key from the key
- look up A by it's key
- perform the join (as usual)
- Register processor after A's processor
- On event uses A's key to perform a Range scan on B's materialization
- For every row retrieved perform join as usual
- Register merger
- Forward join Results
- On lookup use full key to lookup B and extract A's key from the key and lookup A. Then perform join.
- Merger wrapped into KTable and returned to the user.
...
| TOPOLOGY INPUT A | TOPOLOGY INPUT B | STATE A MATERIALZED | STATE B MATERIALIZE | INTERMEDIATE RECORDS PRODUCED | STATE B OTHER TASK | Output A Source / Input Range Proccesor | OUTPUT RANGE PROCESSOR | OUTPUT LOOKUP PROCESSOR | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| key: A0 value: [A0 ...] | key: A0 value: [A0 ...] | Change<null,[A0 ...]> | invoked but nothing found. Nothing forwarded | ||||||||||
| key: A1 value: [A1 ...] | key: A0 value: [A0 ...] key: A1 value: [A1 ...] | Change<null,[A1 ...]> | invoked but nothing found. Nothing forwarded | ||||||||||
| key: B0 : value [A2,B0 ...] | key: A0 value: [A0 ...] key: A1 value: [A1 ...] | key: B0 : value [A2,B0 ...] | partition key: A2 key: A2B0 value: [A2,B0 ...] | key: A2B0 : value [A2,B0 ...] | invoked but nothing found Nothing forwarded | ||||||||
| key: B1 : value [A2,B1 ...] | key: A0 value: [A0 ...] key: A1 value: [A1 ...] | key: B0 : value [A2,B0 ...] key: B1 : value [A2,B1 ...] | partition key: A2 key: A2B1 value [A2,B1 ...] | key: A2B0 : value [A2,B0 ...] key: A2B1 : value [A2,B1 ...] | invoked but nothing found Nothing forwarded | ||||||||
| key: A2 value: [A2 ...] | key: A0 value: [A0 ...] key: A1 value: [A1 ...] key: A2 value: [A2 ...] | key: B0 : value [A2,B0 ...] key: B1 : value [A2,B1 ...] | key: A2B0 : value [A2,B0 ...] key: A2B1 : value [A2,B1 ...] | Change<null,[A2 ...]> | key A2B0 value: Change<null,join([A2 ...],[A2,B0 ...]) key A2B1 value: Change<null,join([A2 ...],[A2,B1...]) | ||||||||
| key: B1 : value null | key: B0 : value [A2,B0 ...] | partition key: A2 key: A2B1 value:null | key: A2B0 : value [A2,B0 ...] | key A2B1 value: Change<join([A2 ...],[A2,B1...],null) | |||||||||
| key: B3 : value [A0,B3 ...] | key: B0 : value [A2,B0 ...] key: B3 : value [A0,B3 ...] | partition key: A0 key: A0B3 value:[A0,B3 ...] | key: A2B0 : value [A2,B0 ...] key: A0B3 : value [A0,B3 ...] | key A0B3 value: Change<join(null,[A0 ...],[A0,B3...]) | |||||||||
| key: A2 value: null | key: A0 value: [A0 ...] key: A1 value: [A1 ...] | key: B0 : value [A2,B0 ...] key: B3 : value [A0,B3 ...] | key: A2B0 : value [A2,B0 ...] key: A0B3 : value [A0,B3 ...] | Change<[A2 ...],null> | key A2B0 value: Change<join([A2 ...],[A2,B0 ...],null) |
...
Range lookup
It is pretty straight forward to completely flush all changes that happened before the range lookup into rocksb and let it handle a the range scan. Merging rocksdb's result iterator with current in-heap caches might be not in scope of this initial KIP. Currently we at trivago can not identify the rocksDb flushes to be a performance problem. Usually the amount of emitted records is the harder problem to deal with in the first place.
...