THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
| Table of Contents |
|---|
Status
Current state: Under discussion
...
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
Exactly once semantics (EOS) provides transactional message processing guarantees. Producers can write to multiple partitions atomically so that either all writes succeed or all writes fail. This can be used in the context of stream processing frameworks, such as Kafka Streams, to ensure exactly once processing between topics.
...
This architecture does not scale well as the number of input partitions increases. Every producer come with separate memory buffers, a separate thread, separate network connections. This limits the performance of the producer since we cannot effectively use the output of multiple tasks to improve batching. It also causes unneeded load on brokers since there are more concurrent transactions and more redundant metadata management.
Proposed Changes
We argue that the root of the problem is that transaction coordinators have no knowledge of consumer group semantics. They simply do not understand that partitions can be moved between processes. Currently transaction coordinator uses the initTransactions API currently in order to fence producers using the same transactional Id and to ensure that previous transactions have been completed. We propose to switch this guarantee on to group coordinator .instead.
Notice that
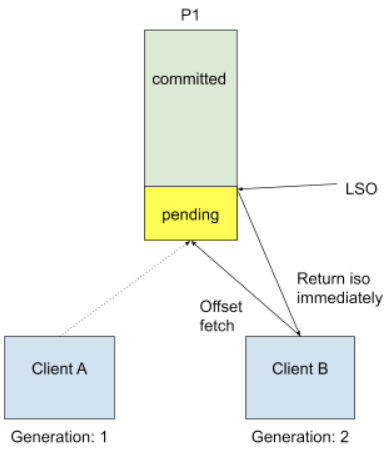
The case will be changed in the new fetch offset design.
 Essentially the problem we are trying to solve is making the coordinator aware of the dependencies between processes that come as a result of partition reassignment. When handling the InitProducerId request, the coordinator will use the previous partition assignment of the consumer group to check which transactions need to be completed before it is safe to begin processing. The coordinator will then ensure that only one producer for each assigned partition is allowed to make progress at any time.
Essentially the problem we are trying to solve is making the coordinator aware of the dependencies between processes that come as a result of partition reassignment. When handling the InitProducerId request, the coordinator will use the previous partition assignment of the consumer group to check which transactions need to be completed before it is safe to begin processing. The coordinator will then ensure that only one producer for each assigned partition is allowed to make progress at any time.
Public Interfaces
The main addition of this KIP is a new variant of the current initTransactions API which gives us access to the consumer group states, such as member.id and generation.id.
...
The new InitProducerId API accepts either a user-configured transactional Id or a consumer group Id and a generation id. When a consumer group is provided, the transaction coordinator will honor consumer group id and allocate a new producer.id every time initTransaction is called.
Fencing zombie
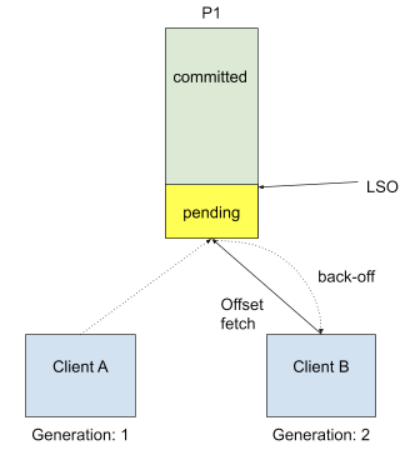
A zombie process may invoke InitProducerId after falling out of the consumer group. In order to distinguish zombie requests, we include the consumer group generation. Once the coordinator observes a generation bump for a group, it will refuse to handle requests from the previous generation. The only thing other group members can do is call InitProducerId themselves. This in fact would be the common case since transactions will usually be completed before a consumer joins a rebalance.
...
When set to true and exactly-once is turned on, Kafka Streams application will choose to use single producer per thread.
Fencing for upgrades
And to avoid concurrent processing due to upgrade, we also want to introduce an exception to let consumer back off:
...
Will discuss in more details in Compatibility section.
Example
Below we provide an example of a simple read-process-write loop with consumer group-aware EOS processing.
...
- Consumer group id becomes a config value on producer.
- Generation.id will be used for group coordinator fencing.
- We no longer need to close the producer after a rebalance.
Compatibility, Deprecation, and Migration Plan
This is a server-client integrated change, and it's required to upgrade the broker first with `inter.broker.protocol.version` to the latest. Any produce request with higher version will automatically get fenced because of no support. If this is the case on a Kafka Streams application, you will be recommended to unset `CONSUMER_GROUP_AWARE_TRANSACTION` config as necessary to just upgrade the client without using new thread producer.
We need to ensure 100% correctness during upgrade. This means no input data should be processed twice, even though we couldn't distinguish the client by transactional id anymore. The solution is to reject consume offset request by sending out PendingTransactionException to new client when there is pending transactional offset commits, so that new client shall start from a clean state instead of relying on transactional id fencing. Since it would be an unknown exception for old consumers, we will choose to send a COORDINATOR_LOAD_IN_PROGRESS exception to let it retry. When client receives PendingTransactionException, it will back-off and retry getting input offset until all the pending transaction offsets are cleared. This is a trade-off between availability and correctness, and in this case the worst case for availability is just waiting transaction timeout for one minute which should be trivial one-time cost during upgrade only.
Rejected Alternatives
- Producer Pooling:
- Producer support multiple transactional ids:
- Tricky rebalance synchronization:
- We could use admin client to fetch the inter.broker.protocol on start to choose which type of producer they want to use. This approach however is harder than we expected, because brokers maybe on the different versions and if we need user to handle the tricky behavior during upgrade, it would actually be unfavorable. So a hard-coded config is a better option we have at hand.
- We have considered to leverage transaction coordinator to remember the assignment info for each transactional producer, however this means we are copying the state data into 2 separate locations and could go out of sync easily. We choose to still use group coordinator to do the generation and partition fencing in this case.
...