THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
We argue that the root of the problem is that transaction coordinators have no knowledge of consumer group semantics. They simply do not understand that partitions can be moved between processes. Currently transaction coordinator uses the initTransactions API currently in order to fence producers using the same transactional Id and to ensure that previous transactions have been completed. We propose to switch this guarantee on group coordinator instead.Let Let's take a look at a sample exactly-once use case, which is quoted from KIP-98:
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
public class KafkaTransactionsExample {
public static void main(String args[]) {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerConfig);
// Note that the ‘transactional.id’ configuration _must_ be specified in the
// producer config in order to use transactions.
KafkaProducer<String, String> producer = new KafkaProducer<>(producerConfig);
// We need to initialize transactions once per producer instance. To use transactions,
// it is assumed that the application id is specified in the config with the key
// transactional.id.
//
// This method will recover or abort transactions initiated by previous instances of a
// producer with the same app id. Any other transactional messages will report an error
// if initialization was not performed.
//
// The response indicates success or failure. Some failures are irrecoverable and will
// require a new producer instance. See the documentation for TransactionMetadata for a
// list of error codes.
producer.initTransactions();
while(true) {
ConsumerRecords<String, String> records = consumer.poll(CONSUMER_POLL_TIMEOUT);
if (!records.isEmpty()) {
// Start a new transaction. This will begin the process of batching the consumed
// records as well
// as an records produced as a result of processing the input records.
//
// We need to check the response to make sure that this producer is able to initiate
// a new transaction.
producer.beginTransaction();
// Process the input records and send them to the output topic(s).
List<ProducerRecord<String, String>> outputRecords = processRecords(records);
for (ProducerRecord<String, String> outputRecord : outputRecords) {
producer.send(outputRecord);
}
// To ensure that the consumed and produced messages are batched, we need to commit
// the offsets through
// the producer and not the consumer.
//
// If this returns an error, we should abort the transaction.
sendOffsetsResult = producer.sendOffsetsToTransaction(getUncommittedOffsets());
// Now that we have consumed, processed, and produced a batch of messages, let's
// commit the results.
// If this does not report success, then the transaction will be rolled back.
producer.endTransaction();
}
}
}
} |
...
KafkaProducer<String, String> producer = new KafkaProducer<>(producerConfig);
producer.initTransactions();
while(true) {
ConsumerRecords<String, String> records = consumer.poll(CONSUMER_POLL_TIMEOUT);
if (!records.isEmpty()) {
producer.beginTransaction();
List<ProducerRecord<String, String>> outputRecords = processRecords(records);
for (ProducerRecord<String, String> outputRecord : outputRecords) {
producer.send(outputRecord);
}
sendOffsetsResult = producer.sendOffsetsToTransaction(getUncommittedOffsets());
producer.endTransaction();
}
}
}
} |
Currently transaction coordinator uses the initTransactions API currently in order to fence producers using the same transactional Id and to ensure that previous transactions have been completed. We propose to switch this guarantee on group coordinator instead.
In the above template, we call consumer.poll() to get data, but internally for the very first time we start doing so, we need to know the input topic offset. This is done by a FetchOffset call to group coordinator. With transactional processing, there could be offsets that are "pending", I.E they are part of some ongoing transaction. Upon receiving FetchOffset request, broker will export offset position to the "latest stable offset" (LSO), which is the largest offset that has already been committed. Since we rely on unique transactional.id to revoke stale transaction, we believe any pending transaction will be aborted when producer calls initTransaction again. During normal use case such as Kafka Streams, we will also explicitly close producer to send out a EndTransaction request to make sure we start from clean state.
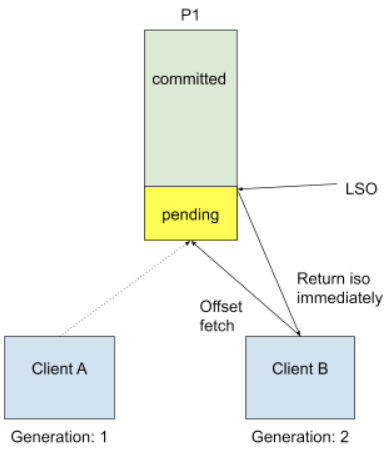
It is no longer safe to do so when we allow topic partitions to move around transactional producers, since transactional coordinator doesn't know about partition assignment and producer won't call initTransaction again during its lifecycle. The proposed solution is to reject FetchOffset request by sending out PendingTransactionException to new client when there is pending transactional offset commits, so that old transaction will eventually expire due to transaction.timeout, and txn coordinator will take care of writing abort markers and failure records, etc. Since it would be an unknown exception for old consumers, we will choose to send a COORDINATOR_LOAD_IN_PROGRESS exception to let it retry. When client receives PendingTransactionException, it will back-off and retry getting input offset until all the pending transaction offsets are cleared. This is a trade-off between availability and correctness, and in this case the worst case for availability is just waiting transaction timeout.
Below is the new approach we introduce here.
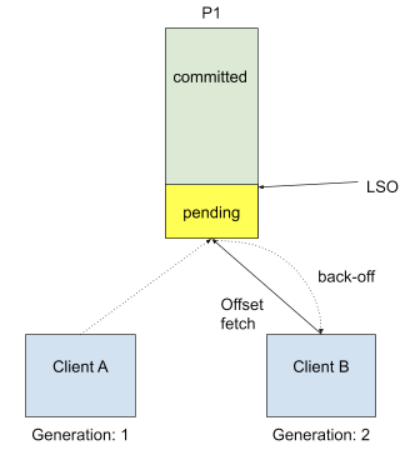
Note that the current default transaction.timeout is set to one minute, which is too long for Kafka Streams EOS use cases. It is because the default commit interval was set to 100 ms, and we would first hit exception if we don't actively commit offsets during that tight window. So we suggest to shrink the transaction timeout to be the same default value as session timeout, to reduce the potential performance loss for offset fetch delay.
...
The case will be changed in the new fetch offset design.
Public Interfaces
...