THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
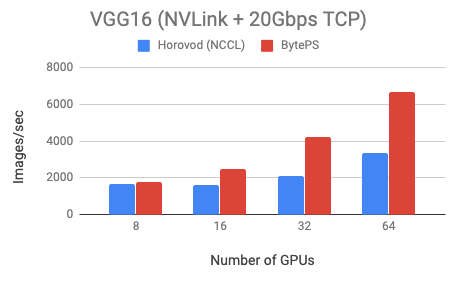
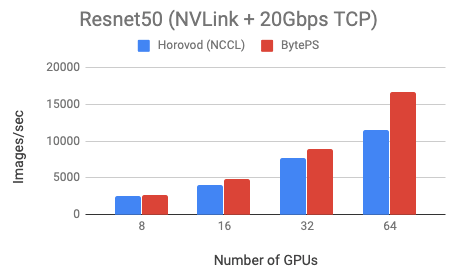
BytePS outperforms Horovod (NCCL) by 44% for Resnet50, and 100% for VGG16.


RDMA Network Benchmark
...
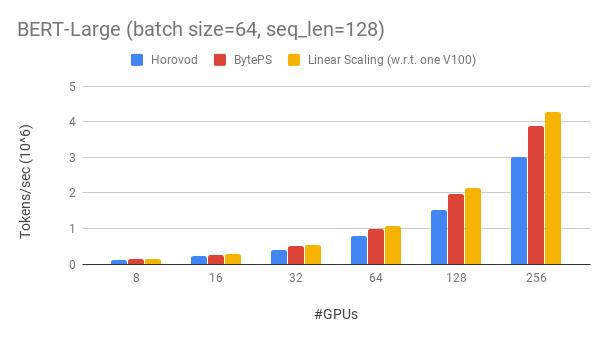
We use Tesla V100 32GB GPUs and set batch size equal to 64 per GPU. Each machine has 8 V100 GPUs with NVLink-enabled. Machines are inter-connected with 100 Gbps RoCEv2 network.
BytePS outperforms Horovod (carefully tuned) by 16% in this case, both with RDMA enabled.
achieves ~90% scaling efficiency for BERT-large with 256 GPUs. As a comparison, Horovod+NCCL has only ~70% scaling efficiency even after expert parameter tunning.

Limitation
BytePS currently has the following limitations:
...
- You only use one GPU. There is no communication for single GPU training, so BytePS does not give you any benefit.
- Your distributed training already achieves (near-)linear scaling. That means your task is not bottlenecked by communication (but by computation instead). BytePS only optimizes the communication.
The rationale of BytePS
This page explains why BytePS outperforms Horovod (and other existing Allreduce or PS based frameworks) in details: https://github.com/bytedance/byteps/blob/master/docs/rationale.md
Contact
For the above, "we" stand for the BytePS team. The primary developers of BytePS team now are Yibo Zhu, Yimin Jiang and Chang Lan. They can be reached via the following email address. We also thank other developers as well.
...