...
When same host and port is used for all gw receivers, pings are not handled correctly. We have observed different behaviorsFollowing examples shows the errors we have seen:
...
Example 1:
Cluster-2 gfsh>list gateways
GatewayReceiver Section
Member | Port | Sender Count | Senders Connected
--------------------------------- | ----- | ------------ | ------------------------------------------------------------------------------------------------------------
172.17.0.5(server-0:65)<v1>:41000 | 32000 | 6 | 172.17.0.4(server-0:65)<v1>:41000, 172.17.0.8(server-1:47)<v1>:41000, 172.17.0.8(server-1:47)<v1>:41000,
172.17.0.8(server-1:47)<v1>:41000, 172.17.0.8(server-1:47)<v1>:41000, 172.17.0.4(server-0:65)<v1>:41000 172.17.0.9(server-1:46)<v1>:41000 | 32000 | 8 | 172.17.0.8(server-1:47)<v1>:41000, 172.17.0.4(server-0:65)<v1>:41000, 172.17.0.4(server-0:65)<v1>:41000,
172.17.0.8(server-1:47)<v1>:41000, 172.17.0.4(server-0:65)<v1>:41000, 172.17.0.4(server-0:65)<v1>:41000, 172.17.0.4(server-0:65)<v1>:41000, 172.17.0.8(server-1:47)<v1>:41000 |
...
root@server-0:/# grep ClientHealthMonitor server-0/server-0.log
[info 2020/03/10 11:13:38.546 GMT <main> tid=0x1] ClientHealthMonitorThread maximum allowed time between pings: 60000
[warn 2020/03/10 11:20:12.203 GMT <ServerConnection on port 32000 Thread 3> tid=0x45] ClientHealthMonitor: Unregistering client with member id identity(172.17.0.8(server-1:47)<v1>:41000,connection=1 due to: The connection has been reset while reading the header
[warn 2020/03/10 11:22:22.336 GMT <ServerConnection on port 32000 Thread 6> tid=0x4c] ClientHealthMonitor: Unregistering client with member id identity(172.17.0.4(server-0:65)<v1>:41000,connection=1 due to: The connection has been reset while reading the header
root@server-1:/# grep ClientHealthMonitor server-1/server-1.log
[info 2020/03/10 11:13:38.700 GMT <main> tid=0x1] ClientHealthMonitorThread maximum allowed time between pings: 60000
[warn 2020/03/10 11:14:52.763 GMT <ClientHealthMonitor Thread> tid=0x39] ClientHealthMonitor: Unregistering client with member id identity(172.17.0.8(server-1:47)<v1>:41000,connection=1 due to: Unknown reason
[warn 2020/03/10 11:14:52.763 GMT <ClientHealthMonitor Thread> tid=0x39] Monitoring client with member id identity(172.17.0.8(server-1:47)<v1>:41000,connection=1. It had been 60595 ms since the latest heartbeat. Max interval is 60000. Terminated client.
[warn 2020/03/10 11:22:13.064 GMT <ClientHealthMonitor Thread> tid=0x39] ClientHealthMonitor: Unregistering client with member id identity(172.17.0.4(server-0:65)<v1>:41000,connection=1 due to: Unknown reason
[warn 2020/03/10 11:22:13.065 GMT <ClientHealthMonitor Thread> tid=0x39] Monitoring client with member id identity(172.17.0.4(server-0:65)<v1>:41000,connection=1. It had been 60747 ms since the latest heartbeat. Max interval is 60000. Terminated client.
|
...
Example 2:
Cluster-1 gfsh>list members
Member Count : 3
Name | Id
--------- | ------------------------------------------------------------
server-0 | 172.17.0.4(server-0:69)<v1>:41000
locator-0 | 172.17.0.6(locator-0:26:locator)<ec><v0>:41000 [Coordinator]
server-1 | 172.17.0.8(server-1:46)<v1>:41000
Cluster-1 gfsh>list gateways
GatewaySender Section
GatewaySender Id | Member | Remote Cluster Id | Type | Status | Queued Events | Receiver Location
---------------- | --------------------------------- | ----------------- | -------- | --------------------- | ------------- | --------------------------------------------------------------
sender-to-2 | 172.17.0.4(server-0:69)<v1>:41000 | 2 | Parallel | Running and Connected | 0 | receiver-site2-service.geode-cluster-2.svc.cluster.local:32000
sender-to-2 | 172.17.0.8(server-1:46)<v1>:41000 | 2 | Parallel | Running and Connected | 0 | receiver-site2-service.geode-cluster-2.svc.cluster.local:32000
Cluster-2 gfsh>list members
Member Count : 3
Name | Id
--------- | ------------------------------------------------------------
server-0 | 172.17.0.5(server-0:65)<v1>:41000
locator-0 | 172.17.0.7(locator-0:24:locator)<ec><v0>:41000 [Coordinator]
server-1 | 172.17.0.9(server-1:51)<v1>:41000
Cluster-2 gfsh>list gateways
GatewayReceiver Section
Member | Port | Sender Count | Senders Connected
--------------------------------- | ----- | ------------ | -------------------------------------------------------------------------------------------------------------------------------------------------
172.17.0.5(server-0:65)<v1>:41000 | 32000 | 7 | 172.17.0.8(server-1:46)<v1>:41000, 172.17.0.8(server-1:46)<v1>:41000, 172.17.0.8(server-1:46)<v1>:41000, 172.17.0.4(server-0:69)<v1>:41000,
172.17.0.4(server-0:69)<v1>:41000, 172.17.0.8(server-1:46)<v1>:41000, 172.17.0.4(server-0:69)<v1>:41000 172.17.0.9(server-1:51)<v1>:41000 | 32000 | 7 | 172.17.0.4(server-0:69)<v1>:41000, 172.17.0.4(server-0:69)<v1>:41000, 172.17.0.8(server-1:46)<v1>:41000, 172.17.0.8(server-1:46)<v1>:41000,
172.17.0.4(server-0:69)<v1>:41000, 172.17.0.8(server-1:46)<v1>:41000, 172.17.0.4(server-0:69)<v1>:41000 |
...
Logs of the servers. In this test, both senders were considered down by one of the receivers:
root@server-0:/# grep ClientHealthMonitor server-0/server-0.log
[info 2020/03/10 14:02:34.130 GMT <main> tid=0x1] ClientHealthMonitorThread maximum allowed time between pings: 60000
[warn 2020/03/10 14:03:56.191 GMT <ClientHealthMonitor Thread> tid=0x37] ClientHealthMonitor: Unregistering client with member id identity(172.17.0.8(server-1:46)<v1>:41000,connection=1 due to: Unknown reason
[warn 2020/03/10 14:03:56.192 GMT <ClientHealthMonitor Thread> tid=0x37] Monitoring client with member id identity(172.17.0.8(server-1:46)<v1>:41000,connection=1. It had been 60507 ms since the latest heartbeat. Max interval is 60000. Terminated client.
[warn 2020/03/10 14:03:56.194 GMT <ClientHealthMonitor Thread> tid=0x37] ClientHealthMonitor: Unregistering client with member id identity(172.17.0.4(server-0:69)<v1>:41000,connection=1 due to: Unknown reason
[warn 2020/03/10 14:03:56.194 GMT <ClientHealthMonitor Thread> tid=0x37] Monitoring client with member id identity(172.17.0.4(server-0:69)<v1>:41000,connection=1. It had been 60444 ms since the latest heartbeat. Max interval is 60000. Terminated client.
root@server-1:/# grep ClientHealthMonitor server-1/server-1.log
[info 2020/03/10 14:02:34.275 GMT <main> tid=0x1] ClientHealthMonitorThread maximum allowed time between pings: 60000
|
And some minutes later:
Cluster-2 gfsh>list gateways
GatewayReceiver Section
Member | Port | Sender Count | Senders Connected
--------------------------------- | ----- | ------------ | -------------------------------------------------------------------------------------------------------
172.17.0.5(server-0:65)<v1>:41000 | 32000 | 0 |
172.17.0.9(server-1:51)<v1>:41000 | 32000 | 3 | 172.17.0.8(server-1:46)<v1>:41000, 172.17.0.8(server-1:46)<v1>:41000, 172.17.0.8(server-1:46)<v1>:41000
|
...
Solution
Gw sender failover
...
Gw sender pings not reaching gw receivers
We think the reason behind the issue of the pings is the way they are created. When a new server connection is established, a new PingTask is created and will be in charge of running the PingOp:
We have implemented a solution for this issue in the following commit: https://github.com/apache/geode/pull/4713/commits/f896f04df291246d420cab88b660fc9736fca49b
There is just one test failing (testExecuteOp from ConnectionPoolImplJUnitTest) that causes integration test and stress test tasks to fail. The tests works locally, only fails in concourse.
Solution consists on refactoring some maps on LocatorLoadSnapshot class. They use ServerLocation objects as key, this has to change due to it will not be unique for each server. We changed the maps to use InternalDistributedMember objects as key for the map entries. The ServerLocation information is not lost, as it is contained in the entry value for all the maps.
The same refactoring is done in EndPointManager, as it holds a map of endpoints that also uses ServerLocation objects as key.
Gw sender pings not reaching gw receivers
We think the reason behind the issue of the pings is the way they are created. When a new server connection is established, a new PingTask is created and will be in charge of running the PingOp:
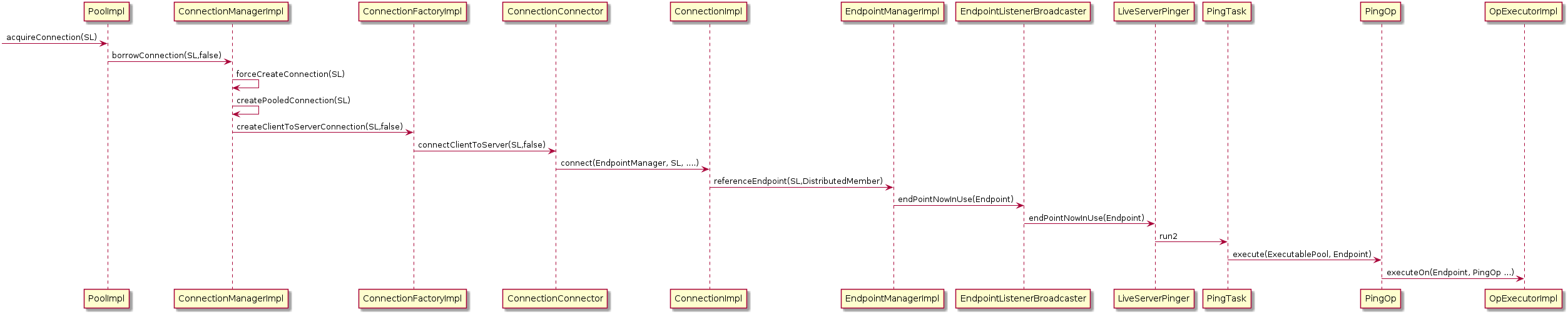 Image AddedImage Removed
Image AddedImage Removed
and
Changes and Additions to Public Interfaces
...
Is there a need for a deprecation process to provide an upgrade path to users who will need to adjust their applications?
Prior Art
What would be the alternatives to the proposed solution? What would happen if we don’t solve the problem? Why should this proposal be preferred?After checking with the dev mailing list, we received the suggestion to configure serverAffinity to solve the issue with the pings. We tried but
FAQ
Answers to questions you’ve commonly been asked after requesting comments for this proposal.
...