THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
Current state: Under Discussion
Discussion thread:
Previous discussion: https://www.mail-archive.com/dev@kafka.apache.org/msg88969.html
...
Many people using Kafka have a need to encrypt the data that Kafka persists to disk, especially when personal data of customers is involved. After the GDPR became effective in May 2018 discussions around data security have been ever-present, and while the GDPR does not require encryption it sure does recommend it. Looking at the financial sector there are a few even stricter regulations that move beyond a simple recommendation and request at-rest encryption "unless technically not feasible". Discussions around this with large corporate compliance departments can at time become quite heated and/or tedious.
...
- TLS encryption requires the broker to decrypt and encrypt every message which prohibits it from using zero-copy-transfer and causes a somewhat larger overhead
- Volume encryption works well as a safeguard against lost disks, but less so for people who already have access to the system (rogue admin problem)
- With volume encryption, it is not readily possible to encrypt only specific topics or encrypt topics with unique keys
I think it would be beneficial for Kafka to implement functionality providing end to end encryption of messages - without the broker being able to decrypt messages in the middle. This is similar in scope to HDFS's transparent data encryption feature which allows specifying directories as encryption zones, which causes HDFS clients to transparently encrypt on write and decrypt on read all access to those directories. For Kafka the equivalent idea would be to enable users to specify a topic as encrypted which would cause producers to encrypt all data written to and consumers to decrypt all data read from that topic.
Originally I intended this to be an all-encompassing KIP for the encryption functionality, however, I now think that this may have been too ambitious and would like to stagger the functionality a little bit.
Aside from the actual crypto-implementation, the main issue that will need to be solved for this is where to obtain keys, when to roll keys, and synchronization of configuration between client and brokers I think. Since there are a lot of possible ways to provide crypto keys the implementation will be designed to be pluggable , so that users have the option of implementing their own key retrieval processes to hook into an existing key infrastructure.
...
- Vault
- Consul
- Amazon KMS
- CloudHSM
- KeyWhiz
For the initial version I'll implement two mechanisms:
- the full blown transparent, KMS backed solution that I think should cover all corporate requirements
- a scaled down version that relies on keystores being distributed to the clients
These solutions are at the simple and complex end of the spectrum and should hopefully help drive out most potential design issues between them, as the proposal is discussed further.
Proposed Changes
Overview
The main focus of this KIP will be creating the necessary code to provide extension points that later allow creating actual implementations of encryption. As part of this KIP two implementations will be created as well.
Three new public interfaces will be created that allow for plugging implementations into Kafka:
KeyManager
The KeyManager runs on a broker and is mostly in charge of telling clients which keys to use for their requests. When a producer wants to send data to a topic it requests the current keys for that topic from the KeyManager. Depending on the actual KeyManager implementation it can either send actual key data The KeyManager thus is also in charge of rolling encryption keys in those scenarios where this is necessary.
The KeyManager implementation to be used can be configured at topic level, to allow for different mechanisms per topic if necessary.
The Controller will be in charge of assigning KeyManager instances to brokers. KeyManagers can be addressed by an identifier, which will allow configuring multiple KeyManagers of the same type, but with different configs.
KeyProvider
The KeyProvider is instantiated by the Kafka clients and used to retrieve the appropriate key to encrypt & decrypt messages. Key ids that were returned by the KeyManager for a topic will be passed into the KeyProvider who will then retrieve the appropriate key.
The value for this parameter can be defined in two places:
- If a KeyManager is defined for the topic, this value will be provided by the KeyManager implementation along with all relevant configuration for for the KeyProvider to perform its work. This allows for fully transparent configuration of encryption with no client side changes.
- Locally in the client config, if this option is chosen, the user has to take care of configuring the same values on consumer and producer to ensure encryption and decryption.
These two possibilities are mutually exclusive, if conflicting settings are provided on broker and client side the client code will throw an exception and exit.
EncryptionEngine
The EncryptionEngine does the actual encryption of data, after having been provided with keys from the KeyProvider object. I do not really expect there to be many implementations of this, but it seemed like something that we might as well make pluggable just in case.
Control Flow
...
Phase 1 (this KIP)
In this phase, I'll add the base functionality to encrypt messages on the producer side and decrypt them on the consumer. All necessary configuration will be added directly to the clients. Key management will be pluggable, but in this phase only a basic implementation using local Keystores will be provided. This means that it will be the duty of the end user to roll out synchronized keystores to the producers and consumers
Phase 2 (KIP not created yet)
This phase will concentrate on server-side configuration of encryption. Topic settings will be added that allow the specification of encryption settings that consumers and producers should use. Producers and Consumers will be enabled to fetch these settings and use them for encryption without the end-user having to configure anything in addition.
Brokers will be extended with pluggable Key Managers that will allow for automatic key rotation later on. A basic, keystore based implementation will be created.
Phase 3 (KIP not created yet)
Phase 3 will build on the foundations laid in the previous two phases and create a proper implementation of transparent end-to-end encryption with envelope encryption for keys
Proposed Changes
Producer Changes
Configuration
The following new configuration settings will be added to the Producer. This will seem like a very short list, as it is mostly just two classes.
Since the entire process is designed to be pluggable, all actual config is part of the actual implementations of these classes. Please see section xxx for details on the implementations that are part of this KIP.
encryption.keyprovider.class
Class implementing the KeyProvider interface that offers methods to retrieve an actual key by reference. This is a mandatory configuration if encryption is to be used.
encryption.keymanager.class
A class providing an implementation of the KeyManager interface. The purpose of this class is to determine which key should be used to encrypt a given record. A common scenario would be to use a key per topic or partition. But this could also be higher-level functions like using customer-specific keys depending on data inside the record.
It is not mandatory to provide this setting, if a KeyManager is not specified then records will not be encrypted, unless a key is explicitly specified.
encryption.algorithms
A whitelist of acceptable encryption algorithms to use.
encryption.encrypt.keys
Should the keys of records be encrypted?
Will default to true.
encryption.encrypt.headers
A pattern that will match header field names that should be encrypted. Will default to .* to encrypt all headers.
These configs allow for various scenarios of which data is encrypted within a record and which isn't, as shown in the figure below.
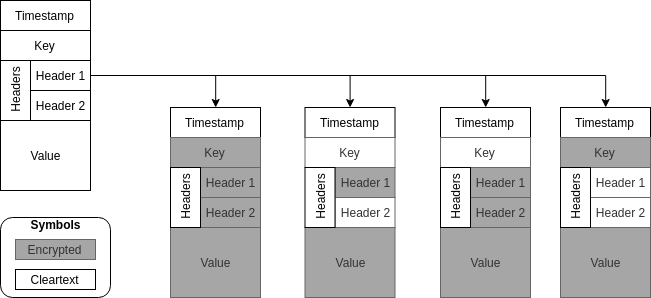
What this would not allow is to programmatically change between these different configurations. For example to explicitly specify that a header field is to be encrypted when adding this header, not sure if we need this functionality (see section on items under discussion).
Additionally, any setting prefixed with encryption.keyprovider. will be passed through to the instantiated KeyProvider for configuration. This will allow creating a more useful implementation that obtains keys from remote vaults like CloudHSM, Keyvault, etc.
The API will not provide any means for the users to actually obtain the key itself, but simply allow identifying a key that is to be used for encryption. This is however more security by obscurity than any actual security as it would be easy to grab the key from the clients JVM with a debugger or run changed code to return the key itself.
API Changes
Encrypting messages can be done in two different ways, either implicitly by configuring a KeyManager, or explicitly by referencing a key when creating the ProducerRecord.
To pass a KeyReference to a ProducerRecord, the current constructors will be extended. The downside of this is, that the number of available Constructors will significantly increase (double in fact).
An example might look as follows:
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
KeyReference encryptionKey = new DefaultKeyReference("key-2020");
ProducerRecord<String, String> data = new ProducerRecord("topic", "key", "value", encryptionKey); |

When using a KeyManager instance, the user code is unchanged, as encryption is handled transparently in the background. The data flow within the producer is shown in the following figure.
![]()
Implementation
The producer will encrypt records based on the settings explained after partitioner and all interceptors have run, right before the record is added to a batch for sending.
This will allow spreading encryption effort out a little over time, batch.size and linger.ms permitting when compared to encrypting an entire batch, for which we'd have to wait for the batch to be complete before starting encryption.
After encrypting the payload, the key reference for the key that was used and information on which fields were encrypted need to be added to the record.
Consumer Changes
The consumer will be extended to understand a subset of the configuration options that were explained in the producer section:
- encryption.keyprovider.class
When receiving an encrypted record, the consumer will retrieve the key reference from the record and use this to obtain a copy of the actual key from its configured KeyProvider.
New Interfaces
KeyProvider
The KeyProvider is instantiated by the Kafka clients and used to retrieve the appropriate key to encrypt & decrypt messages. Keys are referenced either by an object implementing KeyReference.
The value for this parameter can be defined in two places:
- If a KeyManager is defined for the topic, this value will be provided by the KeyManager implementation along with all relevant configuration for for the KeyProvider to perform its work. This allows for fully transparent configuration of encryption with no client-side changes.
- Locally in the client config, if this option is chosen, the user has to take care of configuring the same values on consumer and producer to ensure encryption and decryption.
KeyReference
A very simple interface, similar to KafkaPrincipal, which is used to refer to keys. The reference implementation will simply contain a String and a version, but this can be extended as necessary by users to accommodate proprietary key scenarios that exist for corporate customers.
Proposed Public Interface Change
Binary Protocol
I've left this section empty for now, as I would like to gather feedback on the general principle first, before hammering out the details.
Consumer & Producer Config
The consumer config will receive the following new properties:
| Option Name | Description |
|---|---|
| encryption.keyprovider-class | The class to use as KeyProvider. |
| encryption.keyprovider. | Prefix to symbolize KeyProvider config. Anything with this prefix will be passed through to the KeyProvider upon initialization. |
The producer config will receive the following new properties:
| Option Name | Description |
|---|---|
| encryption.keymanager-class | The class to use as KeyProvider. |
| encryption.keymanager. | Prefix to symbolize KeyProvider config. Anything with this prefix will be passed through to the KeyProvider upon initialization. |
| encryption.keyprovider-class | The class to use as KeyProvider. |
| encryption.keyprovider. | Prefix to symbolize KeyProvider config. Anything with this prefix will be passed through to the KeyProvider upon initialization. |
Initial KeyProvider & KeyManager implementations
As part of this KIP two implementations will be provided, one KeyManager and one KeyProvider. Both will be fairly simple, but fully usable.
Full details on these to follow.
KeyProvider
The Keyprovider will read keys from a local file (optionally encrypted) file.
KeyManager
The KeyManager will be based on topic names and allow configuring keys for patterns of topic names, a default key if no pattern matches and a pattern for unencrypted topics.
Discussion points
As mentioned in the introduction, please keep the discussion on the mailing list instead of the wiki, however, I felt that it would be beneficial to track points that are still in need of clarification here, as I suspect discussion might be somewhat extensive around this KIP.
Encryption mechanism
In order for this implementation to interfere with Kafka internals as little as possible, I have opted for the simplest possible way of going about this, which is to encrypt the individual fields of a record individually.
This gives a large degree of flexibility in what to encrypt, we could potentially even use different keys for header fields and record key and value, to allow intermediate jobs access to routing information, but not the message content.
It comes at the cost of performance and message size however, encrypting the entire message, or even an entire batch will most probably be a lot faster than encrypting individual fields. We'd need to generate a new IV for every field for starters ..
Plus, we will have to pad every field to the required block size for a chosen cipher.
For example a record with 5 headers of 10 bytes, a 100 byte key and a 300 byte value would incur the following overhead for a 16 byte block size (headers are counted double, 5 bytes for field name, 5 for content):
Headers: 10 * (16 - 10) = 60 bytes
Key: (16 * 7) - 100 = 12 bytes
Value: (16 * 19) - 300 = 4 bytes
Total overhead: 76 bytes
Total overhead when encrypting entire record: 512 - (10 * 10 + 100 + 300) = 12 bytes
This is more of an illustration than an accurate calculation of course, but the principle stands.
What to encrypt?
Records don't just contain the value but can (or will) also have:
- Headers
- Timestamp
- Keys
Depending on the method of encryption that we choose for this KIP it might be possible to exclude some of these from encryption, which might be useful for compaction, tracing tools that relay on header values, and similar use cases.
Timestamps
The timestamp is a bit of a special case as this needs to be a valid timestamp and is used by the brokers for retention, we probably shouldn't fiddle with that too much.
Keys
For normal operations, I would say that we can safely encrypt the key as well, as we'd assign the partition in the producer before encryption. (Side note: is this a potential security risk because we can deduct information on the cleartext from this?)
But for compacted topics, we need the key to stay the same, which it wouldn't, even when encrypted with the same key, let alone after key rollover.
Headers
Headers are not used for anything internally, so should be safe to encrypt. However, they are outside of the actual message by design, as this makes them much easier to use for routing and tracing purposes. In a trusted environment there might be value in having some sort of unencrypted id in a header field that can be used to reference this message across topics or systems.
I propose that we leave the timestamp unencrypted and by default encrypt key and header fields. But we give users the option of leaving the key and/or individual header fields unencrypted if necessary.
Allow encrypting compressed content?
As was pointed out on the mailing list, compression is a difficult topic in the context of encryption. Encrypted content doesn't compress well as it is random by design, but encrypting compressed content has security implications that may weaken the security of the encrypted content (see CRIME & BREACH). TLS has afaik removed compression in version 1.3 for this very reason (reference missing, I couldn't find any tbh).
I propose to take an opinionated approach here and disable the parallel use of compression and encryption. But I could absolutely understand if people have other views on this and I am happy to discuss, especially in light of Kafka arguably already supporting this when compression is enabled for data transmitted to an SSL listener.
Support multiple different KeyProviders in a single Producer / Consumer
I am doubtful, whether we need to support more than one KeyProvider for a Client at this point.
I am leaning towards no, should a requirement to do this exist for a user, there is always the option of just having additional clients to accommodate this.
Whitelist unencrypted topics?
Messages might accidentally be sent unencrypted if the user simply forgets to specify a default encryption key in the producer config. To avoid this we could add a setting "encryption.unencrypted.topics" or similar that whitelists topics that are ok to receive cleartext data (or the other way around, blacklist topics that cannot receive cleartext data).
Alternatively, we might consider providing a set of options to specify default keys per topic(-pattern), but this might be taking it a step too far I think.
What do you think, should we include this?
Configuration vs Programmatic control
For the current iteration of this KIP, I have mostly chosen to provide configuration options to control the behavior of encryption functionality. The one exception being the possibility to specify a key when creating a ProducerRecord.
This has the benefit of working with 3rd party tools that just use Kafka client libraries without these tools having to change their code - at the cost of some flexibility.
The alternative / additional option would be to allow programmatic control. For example:
Instead of providing a setting that specifies a whitelist of header fields that should be unencrypted we extend the RecordHeader class to include information on whether to encrypt this header and with which key.
Should we make the actual encryption pluggable?
Or is that taking it a step too far?
- KeyProvider class & config
- Encryption engine class & config
The exact config contained in here is dependent on the implementations in use, at protocol level this will be implemented as an array of key-value pairs.
If the broker returns encryption settings the client checks if the local configuration also contains encryption settings and exits with an error, if any are present.
The client the instantiates objects for both classes with the config provided (either from the broker or locally) and uses these for encryption.
The following diagram should hopefully help make the flow clearer.

Initial Implementations
Local Keystores
This implementation will rely on keystores being provided as local files to the producers and consumers that contain all relevant keys for the topics that are being written/read.
IDs returned by the KeyManager will be mapped to aliases from the local keystore and used to retrieve keys.
The keys to be used for topics will be implemented as dynamically updateable topic settings, to allow changing keys without restarting the cluster.
Hadoop KMS
Hadoop uses a central Key Management Server to provide envelope encryption for keys that are stored with the data in an encrypted format. As a lot of Kafka users also have a Hadoop cluster in operation this may be a popular option, as it is already implemented.
A little disclaimer up front: Since a lot of the necessary design and implementation work has already been done in the Hadoop project this proposal leans on the design document & jira heavily and borrows a lot of the ideas and decisions made back then.
I propose to add functionality to Kafka that will enable producers and consumers to transparently perform encryption and decryption of messages sent to Kafka brokers. The Kafka brokers themselves will not need (nor be able to) decrypt the messages, hence they will be stored on disk in an encrypted format, providing additional security. In order to protect against unauthorized access, I suggest that envelope encryption is used for the keys in an analog fashion to how it has been done for Hadoop TDE.
The following diagram shows at a very high level the control flow for key retrieval, encryption and decryption in both scenarios for an existing topic which has been enabled for encryption - omitted specifics are defined in more detail in the later sections of this KIP.

Key Handling
Key Management Server
All key operations will be delegated to an instance of Hadoop KMS instead of locally generating or storing unencrypted keys. This means that for encryption to work a KMS needs to be accessible to producers and consumers. For people running Kafka as part of a Hadoop distribution both major vendors have KMS implementations available that can be used for this. In a standalone installation of Kafka (or Confluent platform) the Hadoop KMS is available as an isolated package and can be installed easily.
The benefit of using the existing implementation is that a lot of the enterprise features around key management have already been solved and will immediately benefit the Kafka implementation while simultaneously limiting the amount of coding necessary. Hadoop KMS setups can range from a single process that stores keys in a .jks file to highly available setups with keys being stored in several redundant hardware security modules (HSM). For some of the more advanced features a vendor specific implementation of KMS will need to be used but diving into the specifics is beyond the purpose of this document.
Integration with KMS will happen via REST calls, so no Hadoop dependencies are introduced with this KIP. I have added a discussion point whether it might make sense to use the Hadoop provided KMSClient libraries, as these would make implementation easier and offer additional services like load-balancing across multiple KMS instances. Authentication for the REST calls can be via SPNEGO or SSL certificates - initially both consumer and producer will use the same credentials that they use to authenticate with Kafka itself.
Envelope Encryption
In order to guard against insider attacks on the encrypted data envelope encryption is implemented around the actual encryption keys. At the time a topic is configured for encryption a topic encryption key (TEK) is requested with the KMS. The KMS creates this key and stores it with an id and version but doesn't send this key to anybody - it never leaves the KMS. Additionally, a data encryption key (DEK) is requested from the KMS per partition of the topic. The KMS creates these DEKs and encrypts them with the TEK to create the encrypted data encryption key (EDEK) which is returned to the broker and stored in an internal topic.
Consumers and producers retrieve the EDEKs from the topic (via an API request to the broker who caches keys internally) and send them to the KMS who will decrypt and return them. Following this process, the Kafka brokers never see the DEKs in their unencrypted form, so even a cluster admin that can impersonate a super user does not have access to the keys and in extension the unencrypted data.
The following diagram shows the key creation flow that takes place during topic creation and when producing/consuming data. Producer and consumer have been abstracted as user here, as the process is so similar that no distinction is really necessary at this point, further detail has been added to the more specific flow charts further down in this proposal.

Key Storage
Since the EDEKs are not stored by the KMS, they will need to be stored somewhere else. The Hadoop implementation creates a new key per file and stores the actual key in the metadata for that file. With predominantly large file sizes this is a feasible approach, for Kafka with small messages, adding the key to every messages seems like too much overhead, so a separate storage solution is necessary.
An internal topic __encryption_keys will be created with a high partition count (similar to what has been done with the __consumer_offsets topic) and keys stored in this topic partitioned by topic name. The brokers will keep an in-memory cache of encryption keys and whenever a client requests a key for a topic the cache will answer the request from this in-memory representation of the key topic. Updates will be dynamically read by subscribing to the topic.
Caveat:
This in memory cache may over time become quite large depending on number of encrypted topics and key rollover configuration. For example for 10 topics with 9 partitions each and a daily key rollover after a year will have accumulated 10 * 9 * 365 = 32850 keys - which at a key size of 256 bytes is 8 Megabyte of raw key data. While this is not terribly large, the input numbers are also fairly small. If this is applied to a huge cluster with hundreds of topics this may become more of an issue. Ideally a strategy could be found that enables regularly deleting old keys from the key topic, however it is not as simple as just setting the retention higher than the rollover value, as there is no way to know how long clients might use older keys without checking all messages in encrypted topics.
In a later version of this feature we might choose to implement a checkpointing feature where producers regularly commit the key they are currently using and the last offset they produced to. Once the smallest offset in an encrypted topic is larger than this committed value, the respective key can safely be removed. For now, I'd start without this feature though to gather some feedback from the community.
Alternative Solution:
As an alternative to keep memory pressure on the brokers to a minimum reading current keys from the topic could be delegated to the client implementation. In this case it would probably make sense to have a _keys topic per encrypted topic in order to isolate keys and keep read overhead at a minimum.
Key Rollover
Topic Encryption Key
In order to properly roll the TEK to a new version, all stored EDEKs should be decrypted and re-encrypted with the new TEK. The Hadoop KMS only offers this functionality starting in version 3.0.0 until then rollover of TEK would only affect DEKs created after this point in time. I propose to add configuration and functionality to perform a forward-effective lookup in the first version of the code. In a later step we can perhaps look into doing a call at startup to check whether the KMS supports reencrypting keys and performing a proper rollover only where supported.
Technically the implementation would be making the __encryption_keys topic a compacted topic, reading all EDEKs for the topic in question, re-encrypting them via the KMS and write them back to the topic with the same keys so that compaction will clean up obsolete keys. I propose to add this as a command line tool in a second step.
Data Encryption Key
The data encryption key should be changed in regular intervals, the broker will offer two parameters for this (see Configuration section) to configure key rollover based on time since last rollover or messages since last rollover. The controller will schedule a regular process to check whether one of the two conditions has been reached for any DEK and if this is the case request a new version for this key from the KMS and store it.
Any subsequent fetch_keys request from a client would return this new key which will then be used going forward. Decryption of old data is still possible, as the key version is stored with the messages and a specific key version can be retrieved for decryption. In order to keep track of the necessary information we will probably need to store information about the last key change in ZooKeeper for the partitions. A znode will be added under /brokers/topics/<topicname>/partitions/<partition_number>/key_change which stores the offset and date when the last key rollover occurred:
| Code Block | ||
|---|---|---|
| ||
{"rollover_offset":101212,"rollover_date":1524686582,"current_version":1} |
Client-side De-/Encryption
Producer
In order to avoid a wire-protocol change the implementation will serialize and encrypt the original message and then wrap it in a new message transparently. The wrapper message will have a header field set: encryption_key which contains the unique key identifier that can be used with a fetch_key request to retrieve this specific EDEK from the Kafka broker. The identifier will be of the format topicname/partition/version which should not create any parsing issues as topic names are restricted from containing / characters.
This process will be implemented after Serializer and Interceptors are done with the message right before it is added to the batch to be sent, in order to ensure that existing serializers and interceptors keep working with encryption just like without it.
Consumer
The consumer will look at the header fields of every message it receives and if an encryption_key header field is present it will treat the message as an encrypted message. If the key is not present in its in-memory cache a fetch_key request will be issued by the cache implementation to retrieve the required key and cache it for future use.
The key will be used to decrypt the message.
Configuration
New settings will be added to the broker config and topic configuration. During initial communication between broker and producer/consumer all of these settings will be passed to the client, so that encryption can happen fully transparent to the end user - no encryption parameters need to be specified in the client configuration.
The broker config will allow options to configure:
- KMS instance
- default key rotation interval
- default cipher to use
- default key length
The topic metadata that is stored in Zookeeper will be extended to contain the following information:
- key id
- rotation interval
- flag whether unencrypted data should be accepted
- the key provider that clients should use to retrieve keys
Flow Diagrams
Create encrypted topic

Produce to encrypted topic

Consume from encrypted topic

Proposed Public Interface Change
Binary Protocol
I've left this section empty for now, as I would like to gather feedback on the general principle first, before hammering out the details.
For the general types of requests that might be added please refer to the flow diagram above.
...
The topic config will be extended to include the following new properties:
...
Consumer & Producer Config
The consumer config will receive the following new properties:
...
Initial KeyProvider & KeyManager implementations
This section will receive more details around configuration that the initial implementations will support as we progress with the discussion.
Discussion points
As mentioned in the introduction, please keep discussion on the mailing list instead of the wiki, however I felt that it would be beneficial to track points that are still in need of clarification here, as I suspect discussion might be somewhat extensive around this KIP.
Rollover functionality
The ability to roll over Topic Keys is useful to have as stated - do we initially want to include version recognition for the KMS and use functionality to reencrypt keys where supported?
Encryption mechanism
I have proposed to simply encrypt the binary representation of the unencrypted message and use this as the payload in a new message wrapping the encrypted message. This way we can keep the original message unchanged and do not need to come up with a complex method of encrypting payload, header, etc. separately.
Is this a method that people can get behind or should we rethink this approach to do something "cleaner"? This approach might present a compatibility issue in certain scenarios where someone sends messages in an older wire format than the broker is using for on-disk storage as specified by log.message.format.version. The broker would convert the message before storing it on disk, however it would not be able to convert the encrypted record contained within, thus there is a potential for records coming out of a cluster in an older wire format than one would expect. I'm not sure that this would actually create issues in practice as the record would still contain the correct magic byte for version detection. A potential issue I could think of is when the difference in versions becomes so large that the consumer does not support the version of the encrypted message anymore, but this seems like a bit of a stretch.
Compatibility, Deprecation, and Migration Plan
Test Plan
TBD
Rejected Alternatives
Client Configuration
The initial idea was to offer a second alternative for configuring encryption without broker changes by adding parameters to the client libraries. However, this would necessitate storing keys somewhere, passing them into the clients and manually performing rollovers - all of which would encourage insecure behavior and provide a false sense of security to the end user. The decision was for this KIP to focus on providing a proper implementation with all these features.
KeyProvider
Key Storage
Keys will not be stored as part of the message as this would invoke a very large overhead. For Hadoop the key is stored in the metadata of each file, which is a feasible approach for large files. For Kafka a message is usually quite small, so the key might actually end up being bigger than the message itself.
Key Retrieval
Encrypting RecordBatches
It would probably be much more efficient to encrypt the payload of an entire RecordBatch, which is many records appended to each other, instead of encrypting every single message individually, however, there are a few drawbacks to encrypting a full batch:
- The broker cannot perform any validation on the record batch before appending it to its log.
- The broker cannot see control messages contained in the batch
- We'd lose the ability to use different keys for different records within a batch
- Compaction essentially becomes impossible with batches like this
We may choose to revisit Batch-Encryption at a later time, but at the moment per-record encryption seems to be the better choice. In case this is added at a later time it should become a second mode of operation instead of replacing the existing functionality.
Coding the encryption without a library
I considered not using a higher-level encryption library for the actual encryption and relying on core Java functionality. In the interest of security I decided against this and with Google Tink chose an opinionated framework that will try and keep the user (clueless me) as far away from potential mistakes as possibleKey Retrieval from the storage topic will not be implemented in the client code by simply subscribing to the keys topic to limit network activity and enable applying ACLs to key retrieval requests. KMS also authorizes requests, but there is no reason to have the keys topic world readable and allow everybody to retrieve all encrypted keys at his leisure.