Apache Kylin : Analytical Data Warehouse for Big Data
Page History
Table of Contents maxLevel 4
Part I . Why Kylin on Parquet
Benifits
Compare to kylin architechture, the main changes include the following:
...
Cuboids are saved into HDFS as parquet format(or other file system, no longer need HBase)

Storage Engine
Currently, Kylin uses Apache HBase as the storage. HBase Storage is very fast, while it also has some drawbacks:
...
Benchmark Report for Parquet Storage
Query Engine
Kylin 3.X or lower version
- Query node calculate pressure, single bottleneck
- Hard to debug the code generated by Calcite
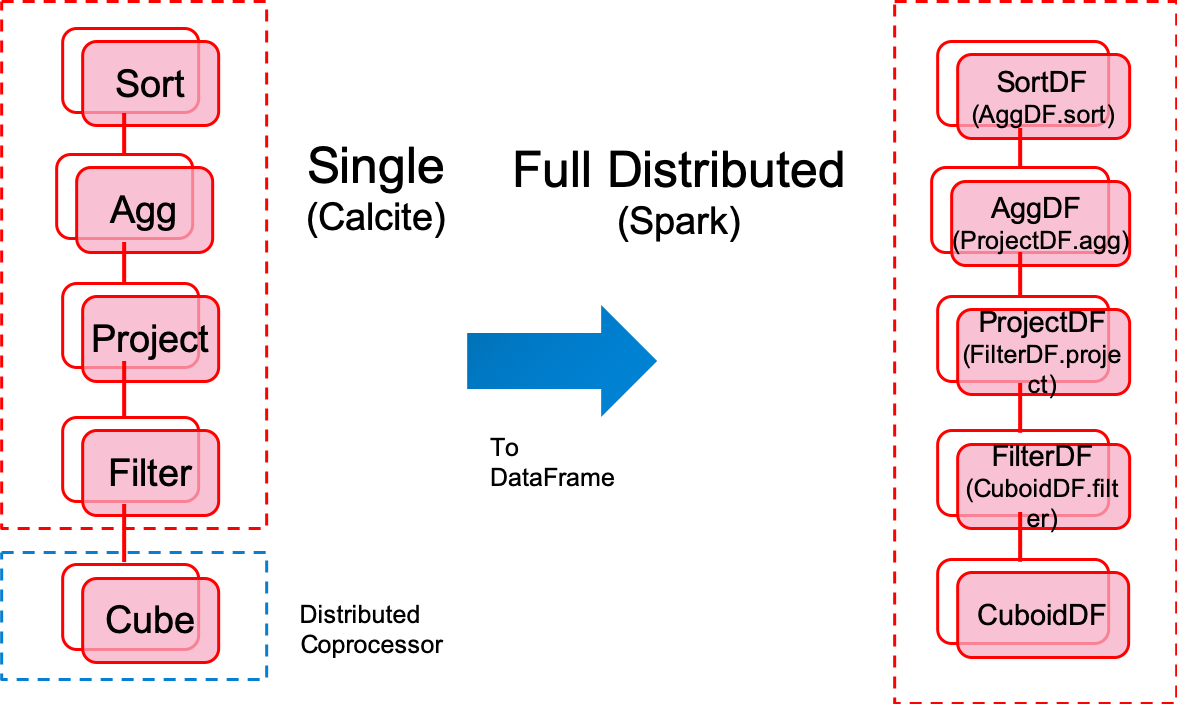
Kylin 4.X
- Fully Distributeddistributed
- Easy to debug and add breakpoint in each DataFrame
...
Part II . How Kylin on Parquet
Code design diagram and analysis
...
Columns[id, name, age] correspond to Dimension[2, 1, 0], measures[COUNT, SUM] correspond to [3, 4]

Query optimize
FilePruner
Effection
- Prune segment with partition column(Date type)
- Prune cuboid parquet files with shard by columns
How to use
- Prune with paritition column will auto analyse date range to prune segments
- Prune shard columns
Identify the columns that need shard by. It's usually the column that used after where. For example: "select count from kylin_sales left join kylin_order where seller_id = '100041'", the "shard by" column is seller_id.
Edit cube. The shard by column should set as normal column not derived column.
Set "Shard by" to true in "Cube edit" -> "Advanced Setting" -> "Rowkey"
Set "kylin.storage.columnar.shard-rowcount" in kylin.properties, the default value is 2500000. The property is used to cut the cuboid file into multiple files and then filter out unwanted files when query.
Limit:
As for now, the shard by is set by cube leve, so there should only be one shard by column. In the future, we may support multi shard by columns with cuboid level. And community users can also give more suggestions.
Overview
Content Tools
ThemeBuilder
Apps