Apache Kylin : Analytical Data Warehouse for Big Data
Page History
...
| Table of Contents | ||
|---|---|---|
|
Background
Since that fact that Kylin4 is highly depend on Spark SQL, it better we have a deeper understanding of Spark SQL.
Definitation
Catalyst is an execution-agnostic framework to represent and manipulate a dataflow graph, i.e. trees of relational operators and expressions.
The main abstraction in Catalyst is TreeNode that is then used to build trees of Expressions or QueryPlans.
Core Contract
| Name | Role | Comment |
|---|---|---|
| SparkSession | Entry Point to Spark SQL |
As a Spark developer, you create a |
| Dataset | Structured Query with Data Encoder | Dataset is a strongly-typed data structure in Spark SQL that represents a structured query. |
| Catalyst | Tree Manipulation Framework | Catalyst is an execution-agnostic framework to represent and manipulate a dataflow graph, i.e. trees of relational operators and expressions. |
| TreeNode | Node in Catalyst Tree |
|
| Expression | Executable Node in Catalyst Tree |
|
| QueryPlan | Structured Query Plan |
Scala-specific, |
Core Diagram
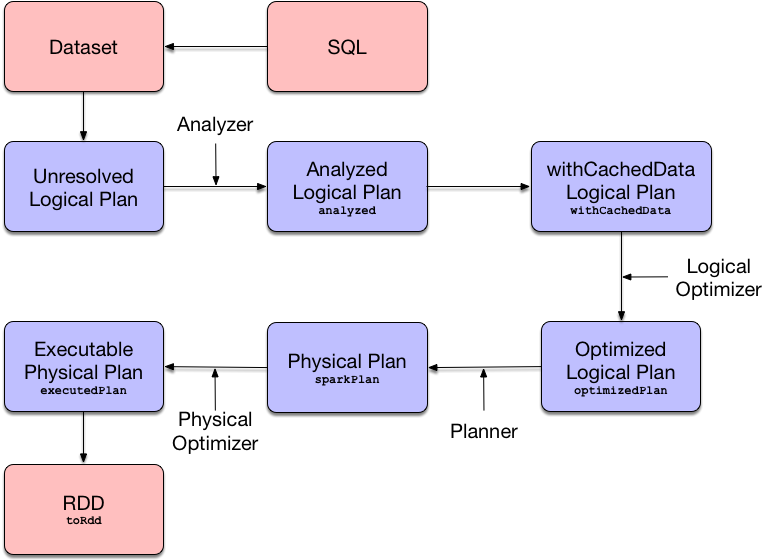
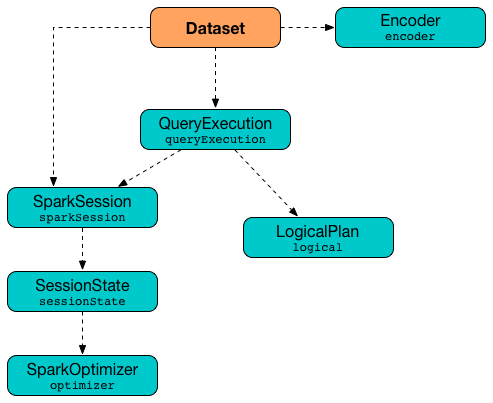
Framework UML Diagram
| PlantUML |
|---|
class TreeNode << BASIC >> {
// TreeNode is a recursive data structure that can have one or many children that are again TreeNodes.
-children : Seq[BaseType]
-verboseString: String
}
abstract class Expression {
// only required methods that have no implementation
+ dataType: DataType
+ doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode
+ eval(input: InternalRow = EmptyRow): Any
+ nullable: Boolean
}
abstract class QueryPlan {
def output: Seq[Attribute]
def validConstraints: Set[Expression]
}
TreeNode <|-- Expression
TreeNode <|-- QueryPlan
|
Credit
All right reserved to jaceklaskowski.
...
Overview
Content Tools
ThemeBuilder
Apps