THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
- DescribeQuorum: Administrative API to list the replication state (i.e. lag) of the voters. More of the details can also be found in KIP-642: Dynamic quorum reassignment#DescribeQuorum.
Before getting into the details of these APIs, there are a few common attributes worth mentioning upfront:
...
Leader Progress Timeout
In the traditional push-based model, when a leader is disconnected from the quorum due to network partition, it will start a new election to learn the active quorum or form a new one immediately. In the pull-based model, however, say a new leader has been elected with a new epoch and everyone has learned about it except the old leader (e.g. that leader was not in the voters anymore and hence not receiving the BeginQuorumEpoch as well), then that old leader would not be notified by anyone about the new leader / epoch and become a pure "zombie leader", as there is no regular heartbeats being pushed from leader to the follower. This could lead to stale information being served to the observers and clients inside the cluster.
To resolve this issue, we will piggy-back on the "quorum.fetch.timeout.ms" config, such that if the leader did not receive Fetch requests from a majority of the quorum for that amount of time, it would begin a new election and start sending VoteRequest to voter nodes in the cluster to understand the latest quorum. If it couldn't connect to any known voter, the old leader shall keep starting new elections and bump the epoch. And if the returned response includes a newer epoch leader, this zombie leader would step down and becomes a follower. Note that the node will remain a candidate until it finds that it has been supplanted by another voter, or win the election eventually.
As we know from the Raft literature, this approach could generate disruptive voters when network partitions happen on the leader. The partitioned leader will keep increasing its epoch, and when it eventually reconnects to the quorum, it could win the election with a very large epoch number, thus reducing the quorum availability due to extra restoration time. Considering this scenario is rare, we would like to address it in a follow-up KIP.
...
Extra condition on commitment: The Raft protocol requires the leader to only commit entries from any previous epoch if the same leader has already successfully replicated an entry from the current epoch. Kafka's ISR replication protocol suffers from a similar problem and handles it by not advancing the high watermark until the leader is able to write a message with its own epoch. The diagram below taken from the Raft dissertation illustrates the scenario:

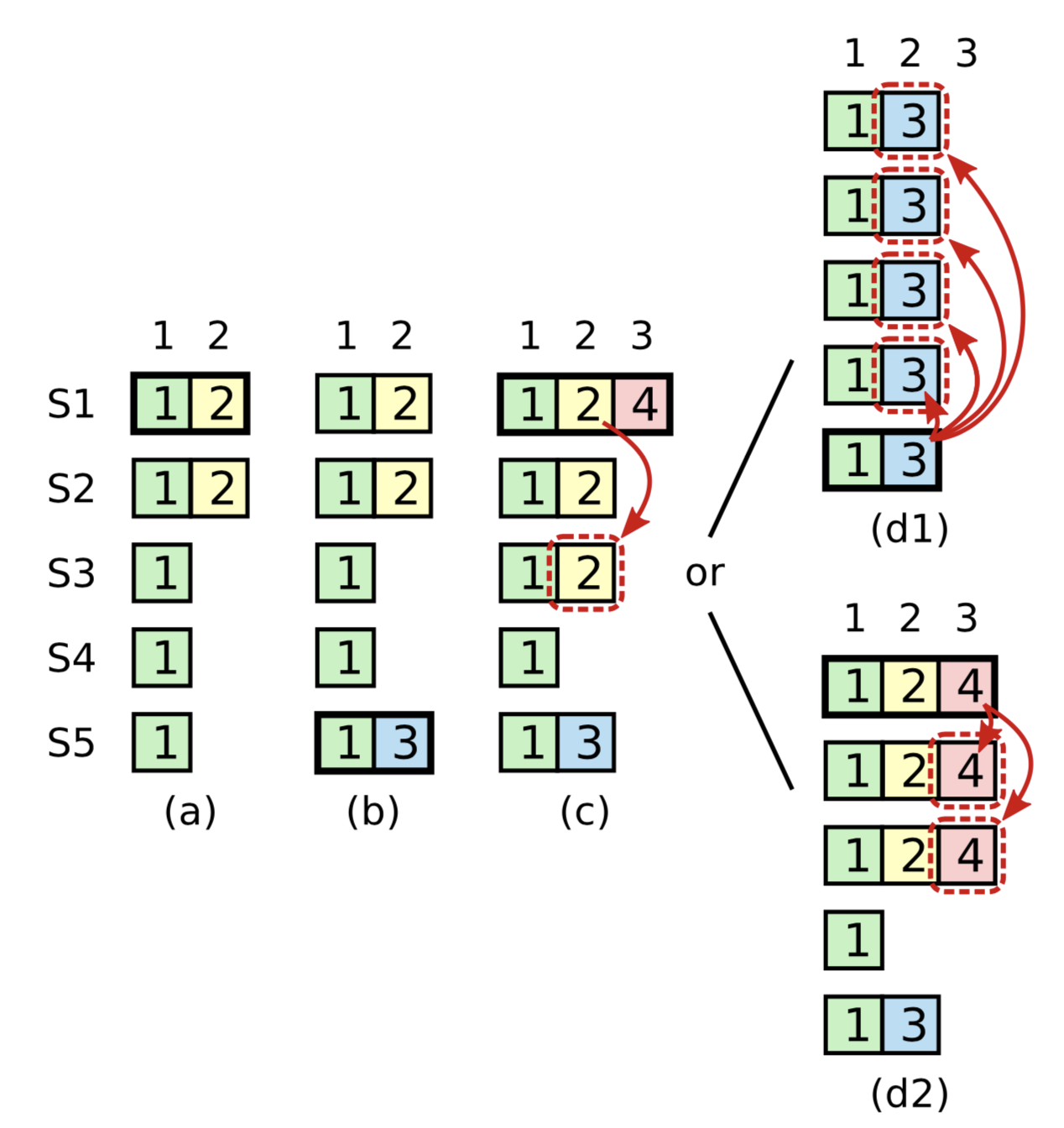
The problem concerns the conditions for commitment and leader election. In this diagram, S1 is the initial leader and writes "2," but fails to commit it to all replicas. The leadership moves to S5 which writes "3," but also fails to commit it. Leadership then returns to S1 which proceeds to attempt to commit "2." Although "2" is successfully written to a majority of the nodes, the risk is that S5 could still become leader, which would lead to the truncation of "2" even though it is present on a majority of nodes.
...
- Check that the clusterId if not null matches the cached value in
meta.properties. - First ensure that the leader epoch from the request is the same as the locally cached value. If not, reject this request with either the FENCED_LEADER_EPOCH or UNKNOWN_LEADER_EPOCH error.
- If the leader epoch is smaller, then eventually this leader's BeginQuorumEpoch would reach the voter and that voter would update the epoch.
- If the leader epoch is larger, then eventually the receiver would learn about the new epoch anyways. Actually this case should not happen since, unlike the normal partition replication protocol, leaders are always the first to discover that they have been elected.
- Check that the epoch on the
FetchOffset's FetchEpochare consistent with the leader's log. Specifically we check thatFetchOffsetis less than or equal to the end offset ofFetchEpoch. If not, return OUT_OF_RANGE and encode the nextFetchOffsetas the last offset of the largest epoch which is less than or equal to the fetcher's epoch. This is a heuristic of truncating to let the voter truncate as much as possible to get to the starting-divergence point with fewer Fetch round-trips: if the fetcher's epoch is X which does not match the epoch of that fetching offset, then it means all records of epoch X on that voter may have diverged and hence could be truncated, then returning the next offset of largest epoch Y (< X) is reasonable. - If the request is from a voter not an observer, the leader can possibly advance the high-watermark. As stated above, we only advance the high-watermark if the current leader has replicated at least one entry to majority of quorum to its current epoch. Otherwise, the high watermark is set to the maximum offset which has been replicated to a majority of the voters.
...
The DescribeQuorum API is used by the admin client to show the status of the quorum. This includes showing the progress of a quorum reassignment and viewing the lag of followers and observers. More of the details can be found in KIP-642: Dynamic quorum reassignment#DescribeQuorum.
Note that this API must be sent to the leader, which is the only node that would have lag information for all of the voters.
Request Schema
| Code Block |
|---|
{
"apiKey": N,
"type": "request",
"name": "DescribeQuorumRequest",
"validVersions": "0",
"flexibleVersions": "0+",
"fields": [
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." }
]
}]
}
]
} |
Response Schema
| Code Block |
|---|
{
"apiKey": N,
"type": "response",
"name": "DescribeQuorumResponse",
"validVersions": "0",
"flexibleVersions": "0+",
"fields": [
{ "name": "ErrorCode", "type": "int16", "versions": "0+",
"about": "The top level error code."},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "ErrorCode", "type": "int16", "versions": "0+"},
{ "name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The ID of the current leader or -1 if the leader is unknown."},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The latest known leader epoch"},
{ "name": "HighWatermark", "type": "int64", "versions": "0+"},
{ "name": "CurrentVoters", "type": "[]ReplicaState", "versions": "0+" },
{ "name": "TargetVoters", "type": "[]ReplicaState", "versions": "0+" },
{ "name": "Observers", "type": "[]ReplicaState", "versions": "0+" }
]}
]}],
"commonStructs": [
{ "name": "ReplicaState", "versions": "0+", "fields": [
{ "name": "ReplicaId", "type": "int32", "versions": "0+"},
{ "name": "LogEndOffset", "type": "int64", "versions": "0+",
"about": "The last known log end offset of the follower or -1 if it is unknown"}
]}
]
} |
DescribeQuorum Request Handling
This request is always sent to the leader node. We expect AdminClient to use the Metadata API in order to discover the current leader. Upon receiving the request, a node will do the following:
- First check whether the node is the leader. If not, then return an error to let the client retry with Metadata. If the current leader is known to the receiving node, then include the
LeaderIdandLeaderEpochin the response. - Build the response using current assignment information and cached state about replication progress.
DescribeQuorum Response Handling
On handling the response, the admin client would do the following:
...
.
Cluster Bootstrapping
When the cluster is initialized for the first time, the voters will find each other through the static quorum.voters configuration. It is the job of the first elected leader (i.e. the first controller) to generate a UUID that will serve as a unique clusterId. We expect this to happen within the controller state machine that defined by KIP-631. This ID will be stored in the metadata log as a message and will be propagated to all brokers in the cluster through the replication protocol defined by this proposal. (From an implementation perspective, the Raft library will provide a hook for the initialization of the clusterId.)
...