Apache Kylin : Analytical Data Warehouse for Big Data
Page History
Table of Contents maxLevel 4 indent 20px style circle
Part I . Why Kylin on Parquet
...
Abstraction
Compare to kylin architechture, the main changes include the following:
- Query engineEngine
Fully distributed query engine. Query task will be sumbit to spark.
- Cube build engineBuild Engine
Spark as the only build engine.
...
Metadata still can be saved into HBase, JDBCRDBMS. There's a little difference with kylin metadata, see more from MetadataConverter.scala.
- StorageStorage Engine
Cuboids are saved into HDFS as parquet format(or other file system, no longer need HBase)

Storage
...
Engine Highlight
Currently(before Kylin 4.0), Kylin uses Apache HBase as the default storage. HBase Storage is very fast, while it also has some drawbacks:
...
Benchmark Report for Parquet Storage
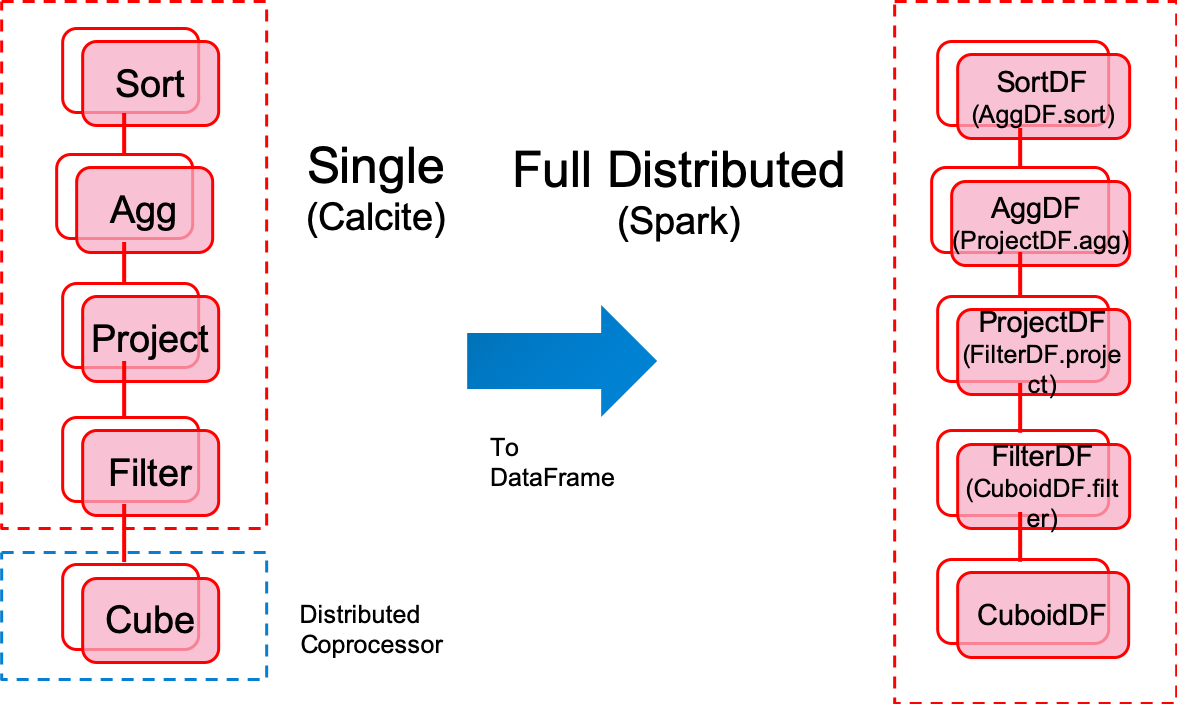
Query Engine Highlight
Kylin 3.X or lower version
- Query node calculate pressure, single bottleneck
- Hard to debug the code generated by Calcite
Kylin 4.X
- Fully distributed
- Easy to debug and add breakpoint in each DataFrame
Part II . How Kylin on Parquet
...
Cubing Step : Resources detect
Collect and dump the following three source info
If contains COUNT_DISTINCT measure(Boolean)
...
Table RDD leaf task numbers(Map). It's used for the next step -- Adaptively adjust spark parameters
Adaptively adjust spark parameters
Turned on by default
Cluster mode only
...
Driver memory base is 1024M, it will adujst by the number of cuboids. The adjust strategy is define in KylinConfigBase.java
Cubing Step : Build by layer
- Reduced build steps
- From ten-twenty steps to only two steps
- Build Engine
- Simple and clear architecture
- Spark as the only build engine
- All builds are done via spark
- Adaptively adjust spark parameters
- Dictionary of dimensions no longer needed
- Supported measures
- Sum
- Count
- Min
- Max
- TopN
- CountDictinct(Bitmap, HyperLogLog)
Cubiod Storage
The flowing is the tree of parquet storage dictory in FS. As we can see, cuboids are saved into path spliced by Cube Name, Segment Name and Cuboid Id, which is processed by PathManager.java .

Parquet file schema
If there is a dimension combination of columns[id, name, price] and measures[COUNT, SUM], then a parquet file will be generated:
Columns[id, name, age] correspond to Dimension[2, 1, 0], measures[COUNT, SUM] correspond to [3, 4]

Part III . Reference
...
Overview
Content Tools
ThemeBuilder
Apps