THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
The earlier approach consists of pulling the remote log segment metadata from remote log storage APIs as mentioned in the earlier RemoteStorageManager_Old section. This approach worked fine for storages like HDFS. One of the problems of relying on the remote storage to maintain metadata is that tiered-storage needs to be strongly consistent, with an impact not only on the metadata itself (e.g. LIST in S3) but also on the segment data (e.g. GET after a DELETE in S3). Also, the cost (and to a lesser extent performance) of maintaining metadata in remote storage needs to be factored in. In the case of S3, frequent LIST APIs incur huge costs.
...
The below diagram gives a brief overview of the interaction between leader, follower, and remote log and metadata storagesstorage. It will be described more in detail in the next section.
...
last-tiered-offset
- The advantage with of this option is that followers can catch up quickly with the leader as the segments that are required to be fetched by followers are the segments that are not yet moved to remote storage.
- One disadvantage with this approach is that followers may have a few local segments than the leader. When that follower becomes a leader then the existing followers will truncate their logs to the leader's local log-start-offset.
...
When a partition is deleted, the controller updates its state in RLMM with DELETE_PARTITION_MARKED and it expects RLMM will have a mechanism to cleanup the remote log segments. This process for default RLMM is described with details in detail here.
RemoteLogMetadataManager implemented with an internal topic
...
RLMM registers the topic partitions that the broker is either a leader or a follower. These topic partitions include the remote log metadata topic partitions also.
RLMM maintains metadata cache by subscribing to the respective remote log metadata topic partitions. Whenever a topic partition is reassigned to a new broker and RLMM on that broker is not subscribed to the respective remote log metadata topic partition then it will subscribe to the respective remote log metadata topic partition and adds all the entries to the cache. So, in the worst case, RLMM on a broker may be consuming from most of the remote log metadata topic partitions. This requires the cache to be based on disk storage like RocksDB to avoid a high memory footprint on a brokerIn the initial version, we will have a file-based cache for all the messages that are already consumed by this instance and it will load inmemory whenever RLMM is started. This will allow us to commit offsets of the partitions that are already read. Committed offsets can be stored in a local file to avoid reading the messages again when a broker is restarted. We can improve this by having a RocksDB based cache to avoid a high memory footprint on a broker.

Message Format
RLMM instance on broker publishes the message to the topic with key as null and value with the below format.
...
The controller receives a delete request for a topic. It goes through the existing protocol of deletion and it makes all the replicas offline to stop taking any fetch requests. After all the replicas reach the offline state, the controller publishes an event to the remote log metadata topic by marking the topic as deleted. With KIP-516, topics are represented with uuid, and topics can be deleted asynchronously. This allows the remote logs can be garbage collected later by publishing the deletion marker into the remote log metadata topic.
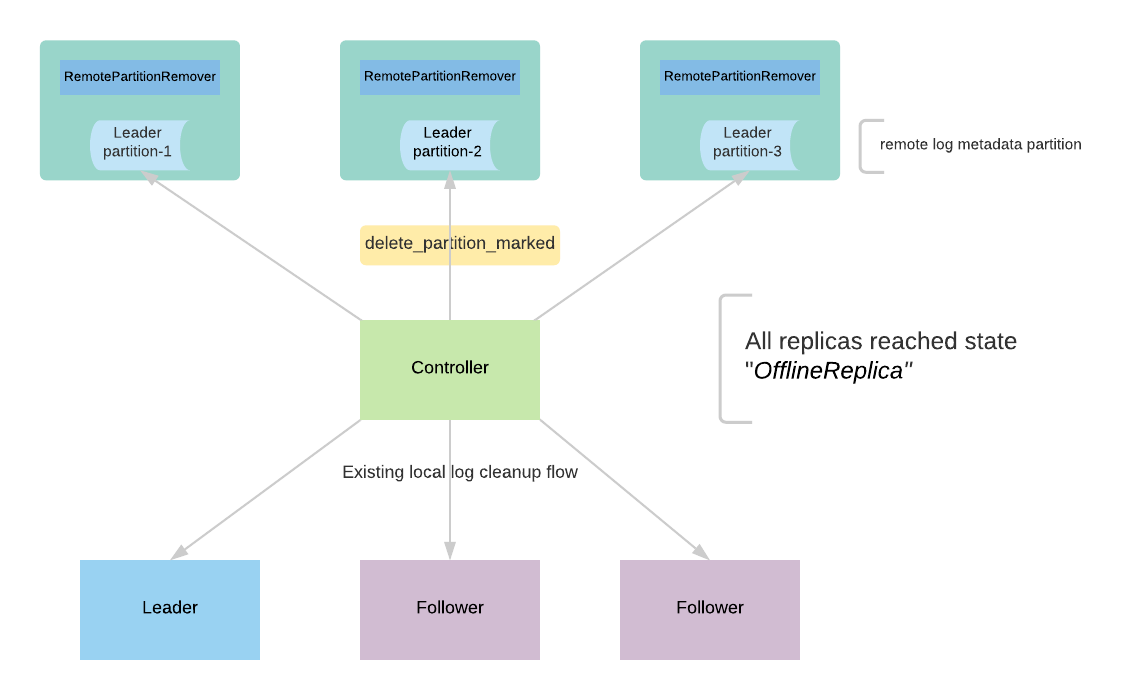
RemoteLogCleaner instance RemotePartitionRemover instance is created on the leader for each of the remote log segment metadata topic partitions. It consumes messages from that partitions and filters the delete partition events which need to be processed. It also maintains a committed offset for this instance to handle leader failovers to a different replica so that it can start processing the messages where it left off.
RemoteLogCleanerRemotePartitionRemover(RLCRPM) processes the request with the following flow as mentioned in the below diagram.
- The controller publishes delete_partition_marked event to say that the partition is marked for deletion. There can be multiple events published when the controller restarts or failover and this event will be deduplicated by RLC.
- RLC RPM receives the delete_partition_marked and processes it if it is not yet processed earlier.
- RLC publishes RPM publishes an event delete_partition_started that indicates the partition deletion has already been started.
- RLC gets RPMgets all the remote log segments for the partition and each of these remote log segments is are deleted with the next steps.
- Publish delete_segment_started event with the segment id.
- RLC deletes RPM deletes the segment using RSM
- Publish delete_segment_finished event with segment id once it is successful.
- Publish delete_partition_finished once all the segments have been deleted successfully.
...
Without tiered storage, the rebuilding broker has to read a large amount of data from the local hard disks of the leaders. This competes page cache and local disk bandwidth with the normal traffic, and dramatically increases the acks=all produce latency.
Future work
- Enhance RLMM local file-based cache with RocksDB to avoid loading the whole cache inmemory.
- Enhance RLMM implementation based on topic based storage pointing to a target Kafka cluster instead of using as system level topic within the cluster.
- Improve default RLMM implementation with a less chatty protocol.
...