THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
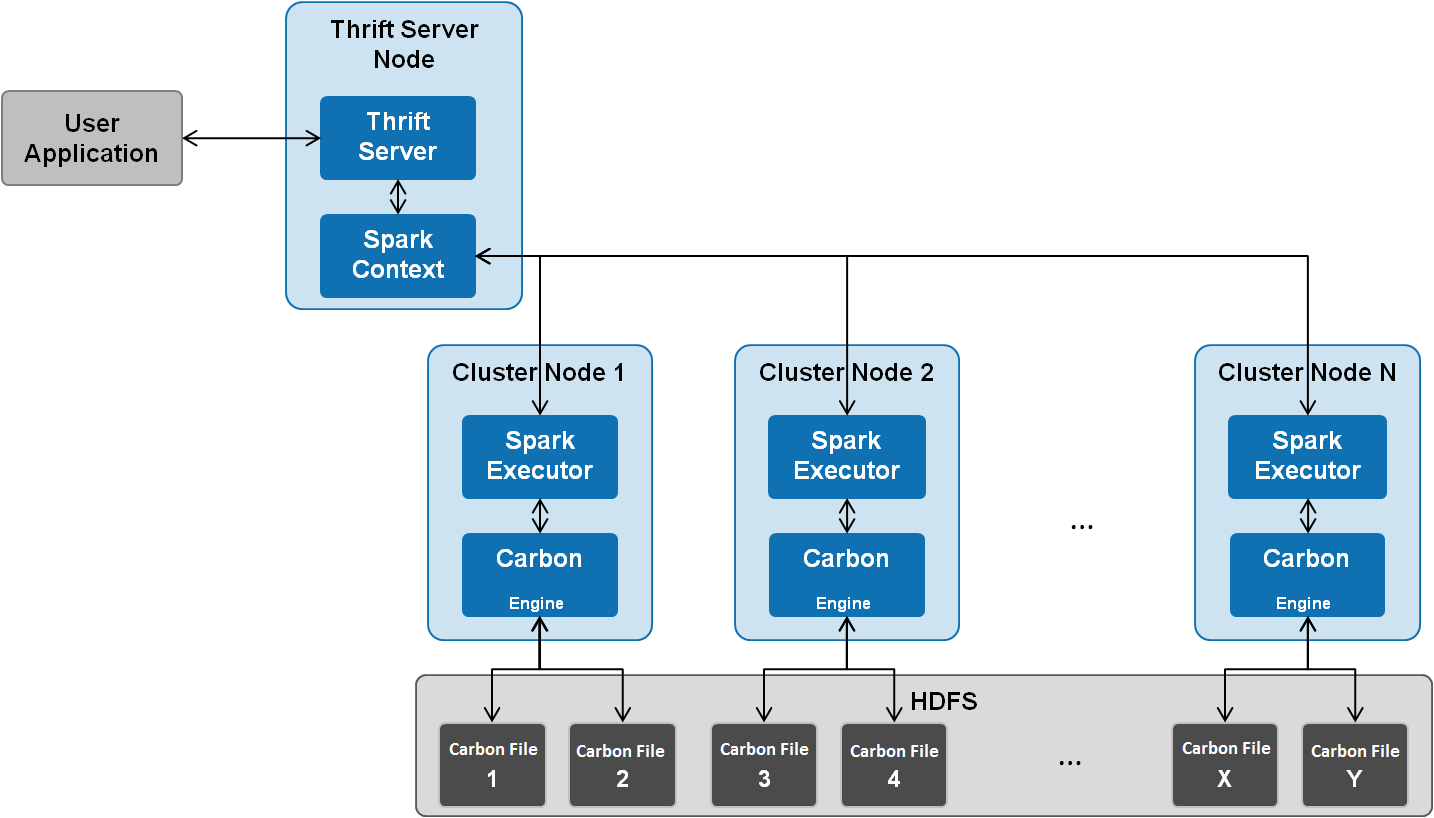
CarbonData是一种新型的Apache Hadoop本地文件格式,使用先进的列式存储、索引、压缩和编码技术,以提高计算效率,有助于加速超过PB数量级的数据查询,可用于更快的交互查询。同时,CarbonData也是一种将数据源与Spark集成的高性能分析引擎。CarbonData作为Spark内部数据源运行,不需要额外启动集群节点中的其他进程,CarbonData Engine在Spark Executor进程之中运行,运行架构如下
CarbonData特性
- SQL功能:CarbonData与Spark SQL完全兼容,支持所有可以直接在Spark SQL上运行的SQL查询操作。
- 简单的Table数据集定义:CarbonData支持易于使用的DDL(数据定义语言)语句来定义和创建数据集。CarbonData DDL十分灵活、易于使用,并且足够强大,可以定义复杂类型的Table。
...
从以上上述描述可以发现,CarbonData作为大数据的一种文件格式,通过一些压缩算法和快速查询索引技术提升查询速度和加速Spark查询,在交互式查询上面具有十分大的优势,下面我自己也做了个表格,通过简单对比目前开源社区上面已有的文件格式(ORC和Parquet)进行对比这3者的一些功能异同点
...
Presto(Trino)是什么?
Presto是什么是Facebook开源的,完全基于内存的并⾏计算,分布式SQL交互式查询引擎.是一种Massively parallel processing (MPP)架构,多个节点管道式执⾏,⽀持任意数据源(通过扩展式Connector组件),数据规模GB~PB级使用的技术,如向量计算,动态编译执⾏计划,优化的ORC和Parquet Reader等 ,它的查询架构如下:
...