THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
The algorithm to identify whether two streams (or tables) represent the same entity will first check if the StreamSourceNode nodes that are the join arguments are reading from the same topic(s) and then, will do a traversal of the graph and will check if the path from the StreamSourceNode node to the root does not have nodes that can change the semantics of the stream. Initially, most nodes will be disallowed to be on the path, only peek and print should be allowed. Later, we can look into adding some smarts into the algorithm to identify whether a mapper actually changes the data in the stream or not. If both conditions hold, then the join can be implemented as a self join. This algorithm is future-proof to support the addition of new DSL operators without affecting the behavior of the self-join.
-------------- In progress ------------
We will add the flag boolean isSelfJoin to StreamStreamJoinNode that will be used when building the topology. If ir is true, then instead of adding the 5 processors that are currently added for an inner join, we will add 2 processors TODO
- Implement the self-join operator (add record to state store, then do lookup)operator
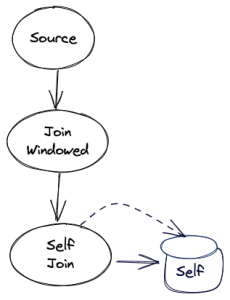
The self-join operator will maintain one state store. For every new record, the record will first get added to the state store and then the operator will perform a lookup into the state store to do the actual join.
- Add a rule to the optimizer that will rewrite an inner join to a self join TODO-join. The graph (logical plan) created from the DSL excerpts above are the same (after the optimization
mergeDuplicateSourceNodes) and look as follows:
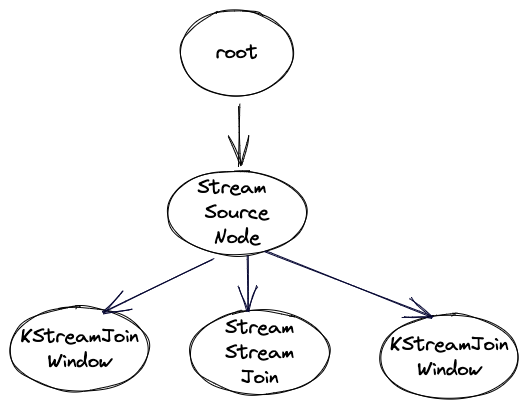
The graph gets translated into the following topology (physical plan)
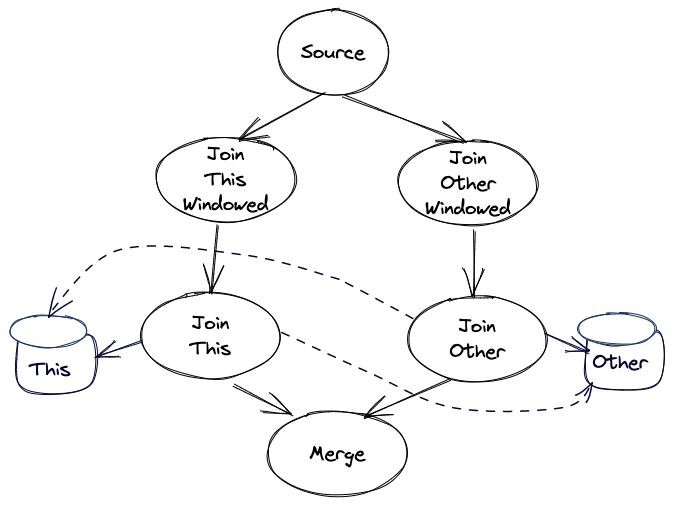
The self-join rewriting will take the above graph, and will translate it into the following topology instead:
Compatibility, Deprecation, and Migration Plan
...