THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
The parallelism of non-source vertices will be calculated by the interface VertexParallelismDecider according to the size of the consumed results. We provide a default implementation as follows(Suppose P is the parallelism and V is the size of data volume to be processed by each task): follows:
follows:
Suppose
- V is the bytes of data the user expects to be processed by each task.
- totalBytesnon-broadcast is the sum of the non-broadcast result sizes consumed by this job vertex.
- totalBytesbroadcast is the sum of the broadcast result sizes consumed by this job vertex.
- maxBroadcastRatio is the maximum ratio of broadcast bytes that affects the parallelism calculation.
- normalize(x) is a function that round x to the closest power of 2.
then the parallelism of this job vertex P will be:
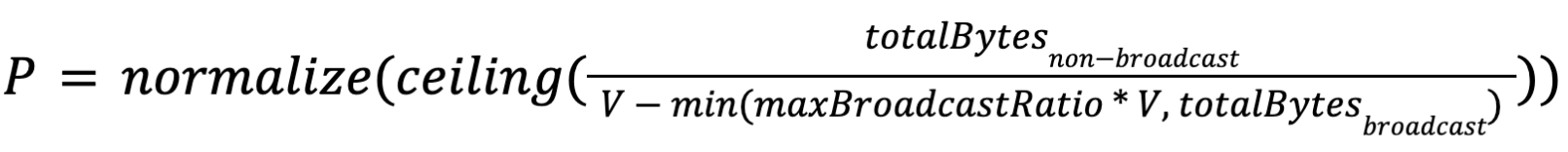
Note that we introduced two special treatment in the above formula (you can click the links for details):
Dynamic Execution Graph
Currently the execution graph will be fully built in a static way before starting scheduling. To allow parallelisms of job vertices to be decided lazily, the execution graph must be able to be built up dynamically.
...
For one result partition, if N is the number of consumer execution vertices and P is the number of subpartitions. For the kth consumer execution vertex, the consumed subpartition range should be:
range = [floor(P * (k - 1) / N), floor(P * k / N) - 1]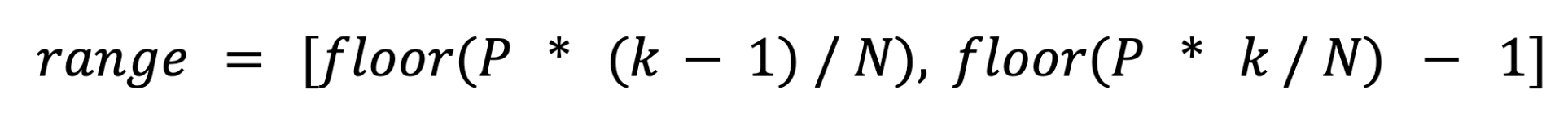
For broadcast results, we can't directly use the above formula, but need to do some special processing. Because for the broadcast result, each subpartition contains all the data to broadcast in the result partition, consuming multiple subpartitions means consuming a record multiple times, which is not correct. Therefore, we propose that the number of subpartitions for broadcast partitions should always be 1, and then all downstream tasks consume this single subpartition( The partition range of the broadcast partition is always set to 0).
...