THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
This page is meant as a template for writing a KIP. To create a KIP choose Tools->Copy on this page and modify with your content and replace the heading with the next KIP number and a description of your issue. Replace anything in italics with your own description.
Status
Current state: [One of "Under Discussion", "Accepted", "Rejected"]
...
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
A self-join is a join whose left and right-side arguments are the same entity (a stream reading from the same topic). Although self-joins are currently supported in Streams, their implementation is inefficient as they are implemented like regular joins where a state store is created for both left and right join arguments. Since both of these arguments represent the same entity, we don't need to create two state stores (as they will contain the exact same data) but only one. This optimization is only suitable for inner joins whose join condition is on the primary key. We do not consider foreign-key joins as we would need to create a state store for both arguments in order to be able to do efficient lookups. Hence, we will handle foreign-key self joins as regular inner foreign-key joins. Moreover, we do not consider outer joins since we are focusing on primary key joins and there will always be at least one join result, the current record joining with itself.
...
This optimization only applies to Stream-Stream inner joins. A Table-Table inner self-join would not yield interesting results since a row would always join with itself. Moreover, this optimization does not apply to N-way self-joins as in the current implementation, an inner join is a binary operator. What this entails is that first one self-join will be applied whose results contains records whose columns are the concatenation of the columns of the left and right join arguments. The subsequent join would then be applied on the result of the first join (the concatenated rows) and not on the inputs of the previous join which means it won't be a self-join anymore. In order to optimize N-way self-joins, we would need to implement a new n-ary operator which is out of the scope of this KIP.
Public Interfaces
No public interfaces will be impacted. The config TOPOLOGY_OPTIMIZATION_CONFIG will be extended to accept a list of optimization rule configs in addition to the global values "all" and "none" .
Proposed Changes
The changes required to implement this proposal are:
...
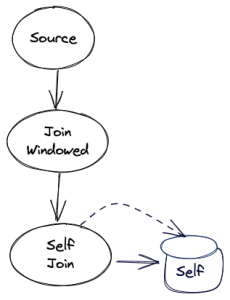
The self-join rewriting will take the above graph, and will translate it into the following topology instead:
Compatibility, Deprecation, and Migration Plan
The change is backward compatible since:
...
As you can see, none of the indices or names of the process is affected.
Rejected Alternatives
Add to the DSL the operator selfJoin. We did not go with this approach as we prefer to push the complexity of the optimization to streams instead of to the user.
...