THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
StatusCurrent state: Accepted
| Page properties | |
|---|---|
|
...
...
|
...
|
...
|
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
...
The parallelism of non-source vertices will be calculated by the interface VertexParallelismDecider according to the size of the consumed results. We provide a default implementation as follows:
Suppose
- V is the bytes of data the user expects to be processed by each task.
- totalBytesnon-broadcast is the sum of the non-broadcast result sizes consumed by this job vertex.
- totalBytesbroadcast is the sum of the broadcast result sizes consumed by this job vertex.
- maxBroadcastRatio is the maximum ratio of broadcast bytes that affects the parallelism calculation.
- normalize(x) is a function that round x to the closest power of 2.
then the parallelism of this job vertex P will be:
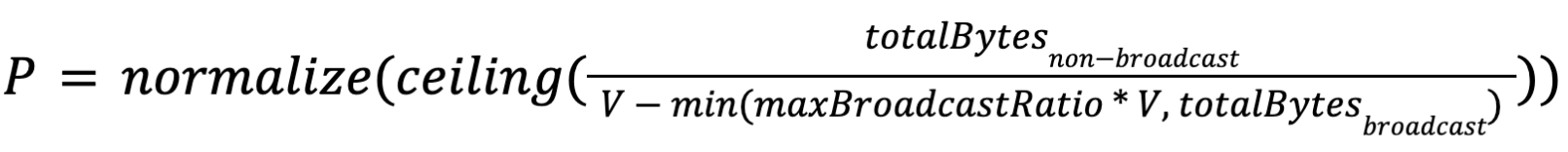
Note that we introduced two special treatment in the above formula (you can click the links for details):
Dynamic Execution Graph
Currently the execution graph will be fully built in a static way before starting scheduling. To allow parallelisms of job vertices to be decided lazily, the execution graph must be able to be built up dynamically.
...
For a broadcast result partition, assuming that the actual data to be broadcast is D, then each subpartition produced by upstream vertex will be a D, and each downstream task expects to consume a D. Assuming that P_max is the maximum parallelism of the downstream vertex and P_actual is the actual parallelism of the downstream vertex, the number of bytes/records sent by the upstream vertex is P_max*D and the number of bytes/records received by the downstream vertex is P_actual*D. Therefore, if P_actual does not equal P_max, the numBytesOut metric of a task will not equal numBytesIn metric of its downstream task.
I
Future improvements
Auto-rebalancing of workloads
...