THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
public class CreateReplicaAssignmentResult {
private KafkaFuture<Map<Integer, Integer[]>> future;
CreateReplicaAssignmentResult(KafkaFuture<Map<Integer, Integer[]>> future) {
this.future = future;
}
public KafkaFuture<Map<Integer, Integer[]>> assignments() {
return future;
}
} |
...
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
public class CreateReplicaAssignmentOptions extends AbstractOptions<CreateReplicaAssignmentOptions> {
private boolean forceSimpleAssignment;
public boolean forceSimpleAssignment() {
return forceSimpleAssignment;
}
public CreateReplicaAssignmentOptions forceSimpleAssignment(boolean forceSimpleAssignment) {
this.forceSimpleAssignment = forceSimpleAssignment;
return this;
}
} |
By specifying the forceSimpleAssignment flag we instruct the brokers to use the default rack unaware algorithm of Kafka. This is needed to maintain compatibility with the –disable-rack-awareness flag in kafka-partition-reassignment.sh. This option will effectively be triggered by specifying that flag and will behave the same way, it will instruct the broker to skip the specified partition assignor and use the default rack unaware algorithm. Note that a rack aware assignor might support a scenario where just part of the brokers have assigned racks.
Protocol
For the Admin API described above, we’ll need a new protocol as well. This is defined as follows.
| Code Block | ||||
|---|---|---|---|---|
| ||||
{
"apiKey": 68,
"type": "request",
"listeners": ["zkBroker", "broker", "controller"],
"name": "CreateReplicaAssignmentRequest",
"validVersions": "0",
"flexibleVersions": "0+",
"fields": [
{ "name": "NumPartitions", "type": "int32", "versions": "0+",
"about": "The number of partitions of the topic in the assignment." },
{ "name": "ReplicationFactor", "type": "int16", "versions": "0+",
"about": "The number of replicas each of the topic's partitions in the assignment." },
{ "name": "ForceSimpleAssignment", "type": "bool", "versions": "0+", "default": "false",
"about": "Forces the default rack unaware partition assignment algorithm of Kafka." },
{ "name": "NodeId", "type": "[]int32", "versions": "0+", "entityType": "brokerId",
"about": "The broker ID." },
{ "name": "timeoutMs", "type": "int32", "versions": "0+", "default": "60000",
"about": "How long to wait in milliseconds before timing out the request." }
]
} |
| Code Block | ||||
|---|---|---|---|---|
| ||||
{
"apiKey": 68,
"type": "response",
"name": "CreateReplicaAssignmentResponse",
"validVersions": "0",
"flexibleVersions": "0+",
"fields": [
{ "name": "ReplicaAssignment", "type": "[]ReplicaAssignment", "versions": "0+",
"about": "A partition to list of broker ID mapping.",
"fields": [
{ "name": "PartitionId", "type": "int32", "versions": "0+", "mapKey": true },
{ "name": "Replicas", "type": "[]int32", "versions": "0+" }
]
}
]
} |
Multi-level rack assignment
In this section we’ll detail the behavior of the multi-level replica assignment algorithm. Currently the replica assignment happens on the controller which continues to be the case. The controller has the cluster metadata, therefore we know the full state of the cluster.
The very first step is that we build a tree of the rack assignments as shown below.
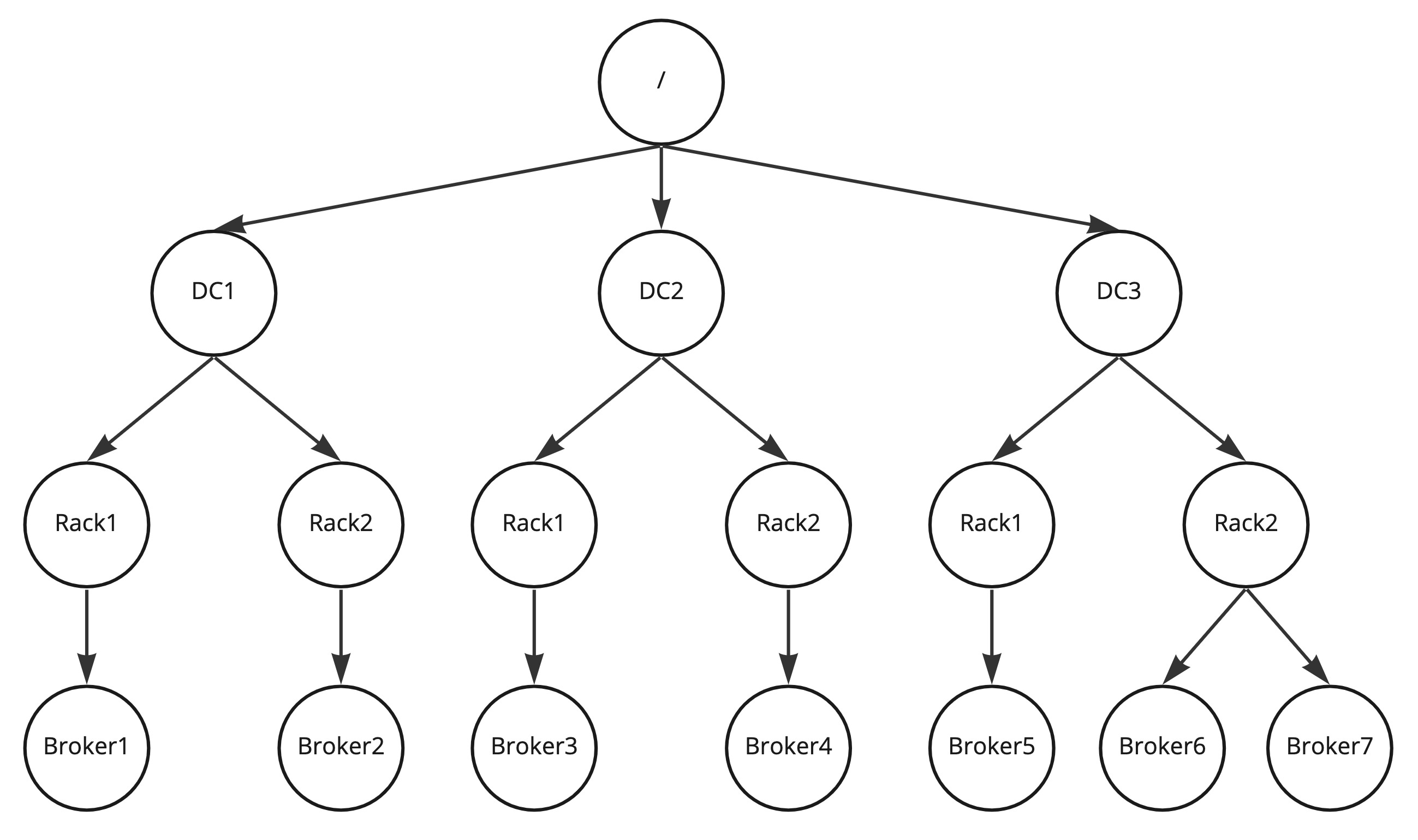
The assignor algorithm can be formalized as follows:
- Every rack definition must start with “/”. This is the root node.
- In every node we define a ring that’ll iterate through the children (and it’ll continue at the beginning if it reaches the last children). It by default points to a random leaf to ensure the even distribution of replicas of different partitions on the cluster.
- On adding a new replica on every level we select the child that is pointed by the iterator, pass down the replica to that and increment the pointer.
- Repeat the previous step for the child we passed down this replica until the leaf is reached.
To increase the replication factor, we basically pick up where the algorithm left the last partition and continue with the above algorithm from the next node that'd be given by the algorithm.
Compatibility, Deprecation, and Migration Plan
...