THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
The main differences between ZooKeeper and standard file systems are that every znode can have data associated with it (every file can also be a directory and vice-versa) and znodes are limited to the amount of data that they can have. ZooKeeper was designed to store coordination data: status information, configuration, location information, etc. This kind of meta-information is usually measured in kilobytes, if not bytes. ZooKeeper has a built-in sanity check of 1M, to prevent it from being used as a large data store, but in general it is used to store much smaller pieces of data.
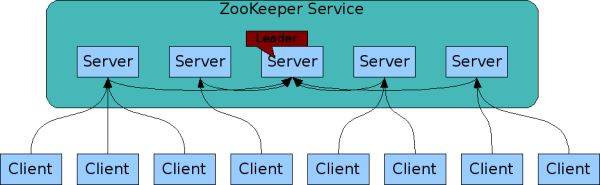
The service itself is replicated over a set of machines that comprise the service. These machines maintain an in-memory image of the data tree along with a transaction logs and snapshots in a persistent store. Because the data is kept in-memory ZooKeeper is able to get very high throughput and low latency numbers. The downside to an in memory database is that the size of the database that ZooKeeper can manage is limited by memory. This limitation is further reason to keep the amount of data stored in znodes small.
...