THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
Describe the problems you are trying to solveWhen a broker’s log directory becomes full Kafka is terminated forcefully (source: Exit.halt(1) eventually calls Runtime::halt which does not cause shutdown hooks to be started). When a broker stops data cannot be produced and consumed, and administrative operations cannot be carried out on the cluster via the broker. Assuming partitions are evenly distributed across the cluster and have balanced traffic such a saturation can occur across multiple brokers simultaneously. Expanding the log directory and restarting the broker can bring it back up. Such an expansion, however, is not always feasible in cloud deployments, for example with a standard block size of 4KB an AWS EBS volume can support only up to 16TB (source). There are other ways to alleviate the problem as well (manually delete data outside of Kafka; try to split a log directory across multiple disks; attach additional disks) but all of them require intervention outside of Kafka. Tiered Storage (KIP-405) is expected to alleviate some of these problems, but it still requires expertise to ensure that the rate of archival from local to remote storage is higher or equal to the rate at which data is written to local storage. As such, from the point of view of a Kafka customer it is important to provide a solution to free up disk space without requiring external intervention.
Public Interfaces
Briefly list any new interfaces that will be introduced as part of this proposal or any existing interfaces that will be removed or changed. The purpose of this section is to concisely call out the public contract that will come along with this feature.
...
Binary log format
The network protocol and api behavior
Any class in the public packages under clientsConfiguration, especially client configuration
org/apache/kafka/common/serialization
org/apache/kafka/common
org/apache/kafka/common/errors
org/apache/kafka/clients/producer
org/apache/kafka/clients/consumer (eventually, once stable)
Monitoring
Command line tools and arguments
- Anything else that will likely break existing users in some way when they upgrade
Proposed Changes
Current state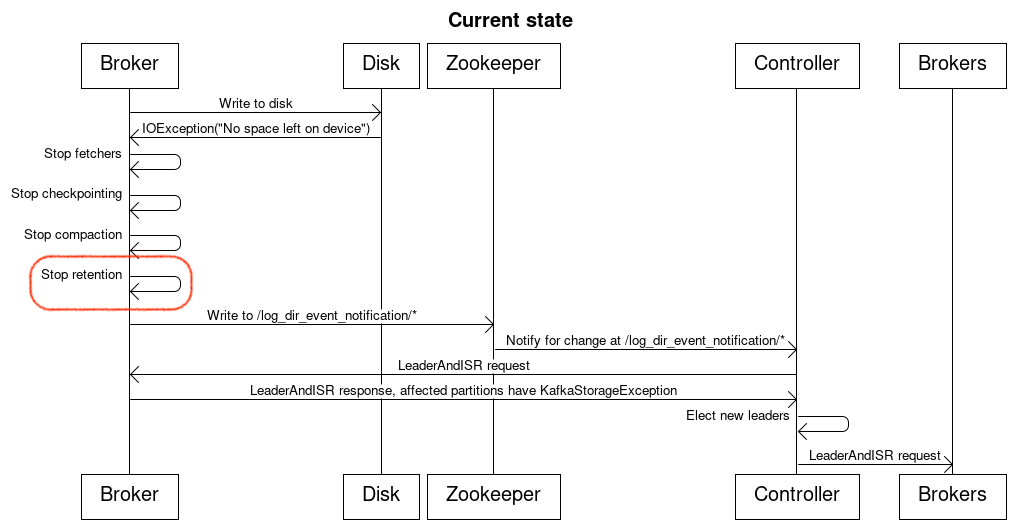
A Kafka broker has a big try-catch statement around all interactions with a log directory. If an IOException is raised the broker will stop all operations on logs located in that log directory, remove all fetchers, stop checkpointing, prevent compaction and retention from taking place and write to a node in Zookeeper.
The Kafka controller will get notified by Zookeeper that there was a problem with a log directory on a particular broker. The controller will then reach out to the broker to understand the state of partition replicas. The broker responds with which partition replicas are offline due to a log directory going offline. The controller determines the new leaders of said partitions and issues new leader and in-sync replicas requests.
The controller keeps track of which replicas of partitions are offline and does not forward delete topic requests to the brokers hosting said replicas.
Goal state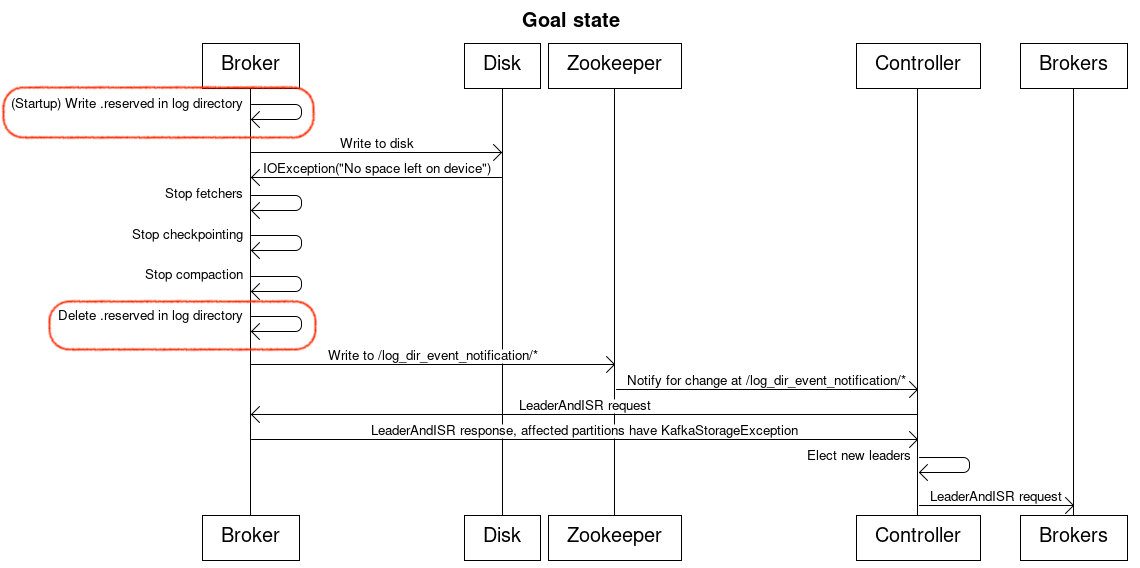
A Kafka broker still has a big try-catch statement around all interactions with a log directory. If an IOException due to No space left on device is raised the broker will stop all operations on logs located in that directory, remove all fetchers and stop compaction. Retention will continue to be respected. The same node as the current state will be written to in Zookeeper. All other IOExceptions will continue to be treated the same way they are treated now and will result in a log directory going offline.
The Kafka controller will get notified by Zookeeper that there was a problem with a log directory on a particular broker. The controller will then reachout to the broker to understand the state of partition replicas. The broker responds with which partition replicas are offline due to a log directory becoming saturated. The controller determines the new leaders of said partitions and issues new leader and in-sync replicas requests.
In addition to the above, upon Kafka server startup we will write and flush to disk a 40MB (from tests: ~10KB per partition for approximately 4000 partitions) file with random bytes to each log directory which we will delete whenever a broker goes into a saturated state. Since the file will be written before any of the log recovery processes are started if there are any problems Kafka will shut down. This reserved space is a space-of-last-resort for any admin operations requiring disk to run while the broker is in a saturated state. For example, if all segments of a partition are marked for deletion Kafka rolls a new segment before deleting any old ones. If we do not have some space put aside for such operations then we will have to change their ordering.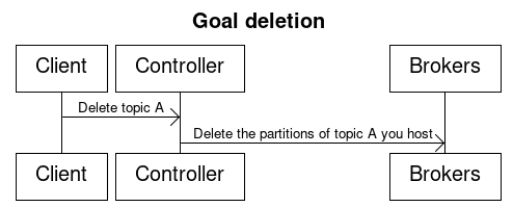
The controller will forward delete topic requests to all brokers hosting replicas of partitions of the topic under deletion. Requests targeting saturated log directories will be respected and will succeed. Requests targeting offline log directories will fail, which is expected.
The design presented focuses on Kafka clusters with Zookeeper because the feature upon which the solution is build does not yet exist in KRaft. It is being added to KRaft as part of KIP-858. What differs between the Zookeeper implementation and the proposed KRaft implementation would be the notification mechanism, but not the steps a broker needs to go through. As such, when KIP-858 is accepted and implemented the proposed design should work with minimal changes.
There are three entities interacting when Kafka handles exceptions arising from using a disk - Zookeeper, controller, and broker. Zookeeper is used to notify the controller that a broker’s disk has experienced an exception. The controller determines which partitions from the ones on the affected broker need new leaders and notifies the new leaders. The proposed solution builds on top of the notification and handling mechanism introduced in KIP-112.
There are three state machines related to this change, two on the broker (log directory and partition state) and one on the controller (partition state) and we will be modifying only the state machines of the broker. Both the broker and the controller have a state machine for a partition state, but these are two completely separate state machines which just share a name. There are more states in a controller’s partition state machine and they need to be more in order to choose a leader correctly. A broker’s partition state machine is simplified because it only needs to know whether it hosts the partition or not. Whenever a broker detects a problem with a log directory it carries out contingency measures and writes a node to Zookeeper at location /log_dir_event_notification with data of the format {"version" : 1, "broker" : brokerId, "event" : LogDirFailure}. The controller watches for changes at that location and when notified sends a LeaderAndISR request to the affected broker. The broker gathers the state of its partition replicas and responds to the controller with which partition replicas should be considered impaired. Leadership election is triggered for every partition, which has an impaired leader replica on said broker.
Current Broker Log Directory State Machine

Target Broker Log Directory State Machine
Current Broker Partition State Machine
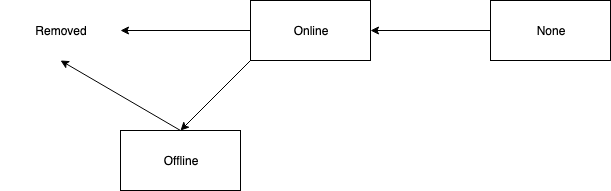
Target Broker Partition State Machine
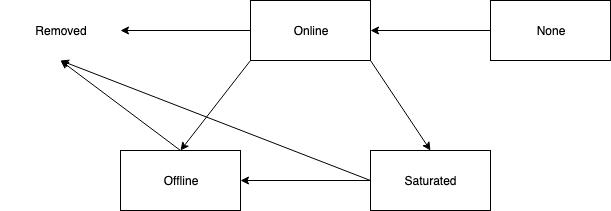
We will add a new state to the broker state machines of a log directory (saturated) and a partition replica (saturated). The partition state machine is only known to the broker and it won’t be replicated on the controller. We need these additional states in order to restrict which background tasks operate on them. If we do not have a separate state then we have no way to tell Kafka that we would like deletion and retention to continue working on saturated log directories and partitions.
Zookeeper
No changes will be introduced to Zookeeper. We continue to use it only as a notification mechanism.
Controller
Instead of sending a delete topic request only to replicas we know to be online, we will allow a delete topic request to be sent to all replicas regardless of their state. Previously a controller did not send delete topic requests to brokers because it knew they would fail. In the future, topic deletions for saturated topics will succeed, but topic deletions for the offline scenario will continue to failDescribe the new thing you want to do in appropriate detail. This may be fairly extensive and have large subsections of its own. Or it may be a few sentences. Use judgement based on the scope of the change.
Compatibility, Deprecation, and Migration Plan
...