THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
It applies to the ack=1 message replication as well. Note that the leader still acknowledges the client requests when the ack=1 messages have persisted in the leader log.
The ISR membership refers to the latest ISR membership persisted by the controller, not the "maximal ISR" which is defined by the leader that includes the current ISR members and pending-to-add replicas that have not yet been committed to the controller.
Note that, if If maximal ISR > ISR, the message should be replicated to the maximal ISR before covering the message under HWM. The proposal does not change this behaviorISR refers to the ISR committed by the controller.
As a side effect of the new requirement:
...
The ISR will still continue to serve its replication function. The High Watermark forwarding still requires a quorum within the ISRthe replication of the full ISR. This ensures that replication between brokers remains unchanged.
To handle leader elections, we will introduce a concept called Eligible Leader Replicas (ELR). In addition to the ISR members, replicas in ELR are also eligible for leader election during a clean election process.
...
Here is an example that demonstrates most of the above ELR behaviors. The setup is 4 brokers with min ISR 3.

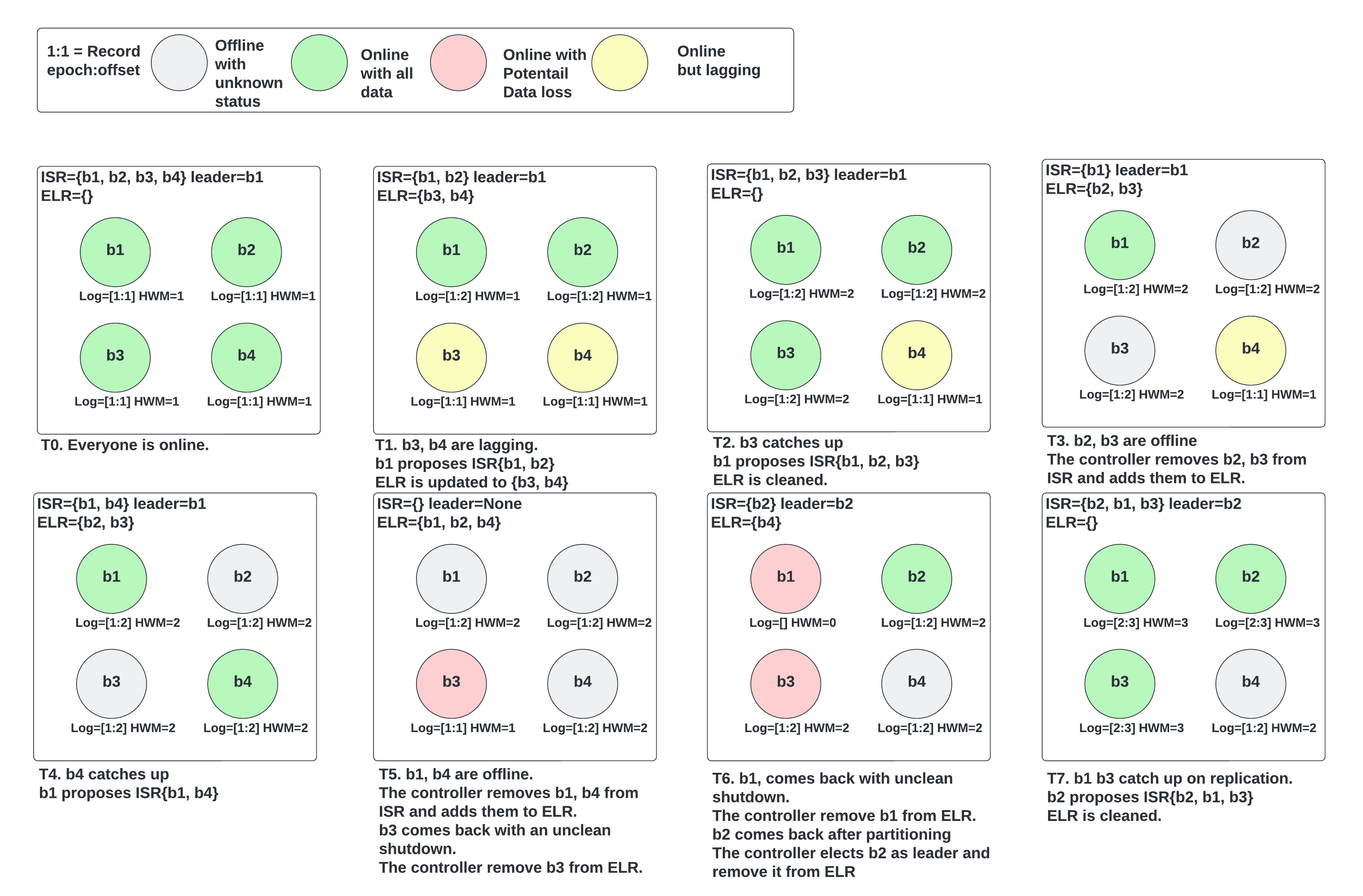
A common question is whether we could advance HWM when we have an ELR member (not replicating from leader), thus violating the invariant that every ELR member has data at least up to HWM. Consider the following example of a 3 replicas partition with min ISR=2:
...
If there are other ISR members, choose an ISR member.
If there are unfenced ELR members, choose an ELR member.
If there are fenced ELR members
If the unclean.recovery.strategy=Proactive, then an unclean recovery will happen.
Otherwise, we will wait for the fenced ELR members to be unfenced.
If there are no ELR members.
If the unclean.recovery.strategy=balanced or Proactive, the controller will do the unclean recovery.
Otherwise, unclean.recovery.strategy=Manual, the controller will not attempt to elect a leader. Waiting for the user operations.
...
In Balance mode, all the LastKnownELR members have replied, plus the replicas replied within the timeout.
In Proactive mode, any replicas replied within a fixed amount of time OR the first response received after the timeout. We don’t want to make a separate config for it so just make the fixed time of 5 seconds.
...
|
DescribeTopicRequest
Should be issued by admin clients or brokers. The controller will serve this request.
ACL: Describe Topic
|
...
GetReplicaLogInfo Request
ACL: Read Topic
|
...
|
...
- kafka.replication.electable_replicas_count. It will be the sum of (size of ISR + size of ELR).
The following count metrics will be added.
- kafka.replication.unclean_recovery_partitions_count. It counts the partitions that are under unclean recovery.
- kafka.replication.
...
- manual_operation_required_partition_count. It counts the partition that is leaderless and waits for user operations to find the next leader.
Public-Facing Changes
min.insync.replicas now applies to the replication of all kinds of messages. The High Watermark will only advance if all the messages below it have been replicated to at least least min.insync.replicas replicasISR members.
The consumer is affected when consuming the ack=1 and ack=0 messages. When there is only 1 replica(min ISR=2), the HWM advance is blocked, so the incoming ack=0/1 messages are not visible to the consumers. Users can avoid the side effect by updating the min.insync.replicas to 1 for their ack=0/1 topics.
Compared to the current model, the proposed design has availability trade-offs:
If the network partitioning only affects the heartbeats between a follower and the controller, the controller will kick it out of ISR. If If losing this replica makes the ISR under min ISR, the HWM advancement will be blocked unnecessarily because we require the ISR to have at least min ISR members. However, it is not a regression compared to the current system at this point. But later when the network partitioning finishes, the current leader will put the follower into the pending ISR(aka "maximum ISR") and continue moving forward while in the proposed world, the leader needs to wait for the controller to ack the ISR change.
Electing a leader from ELR may mean choosing a degraded broker. Degraded means the broker can have a poor performance in replication due to common reasons like networking or disk IO, but it is alive. It can also be the reason why it fails out of ISR in the first place. This is a trade-off between availability and durability.
The unclean leader election will be replaced by the unclean recovery.
- For fsync users, the ELR can be beneficial to have more choices when the last known leader is fenced. It is worth mentioning what to expect when ISR and ELR are both empty. We assume fsync users adopt the unclean.leader.election.enable as false.
- If the KIP has been fully implemented. The unclean.recovery.strategy will be balanced. During the unclean recovery, the URM will elect a leader when all the LastKnownElr members have replied.
- If only the ELR or Unclean recovery is implemented, the LastKnownLeader is preferred.
...
For the existing unclean.leader.election.enable
If true, unclean.recovery.strategy will be set to Proactive.
If false, unclean.recovery.strategy will be set to Balanced.
unclean.recovery.strategy is guarded by the metadata version. Ideally, it should be enabled with the same MV with the ELR change.
The unclean leader election behavior is kept before the MV upgrade.
- Once the unclean recovery is enabled, the MV is not downloadable.
Delivery plan
The KIP is a large plan, it can be across multiple quarters. So we have to consider how to deliver the project in phases.
...