THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
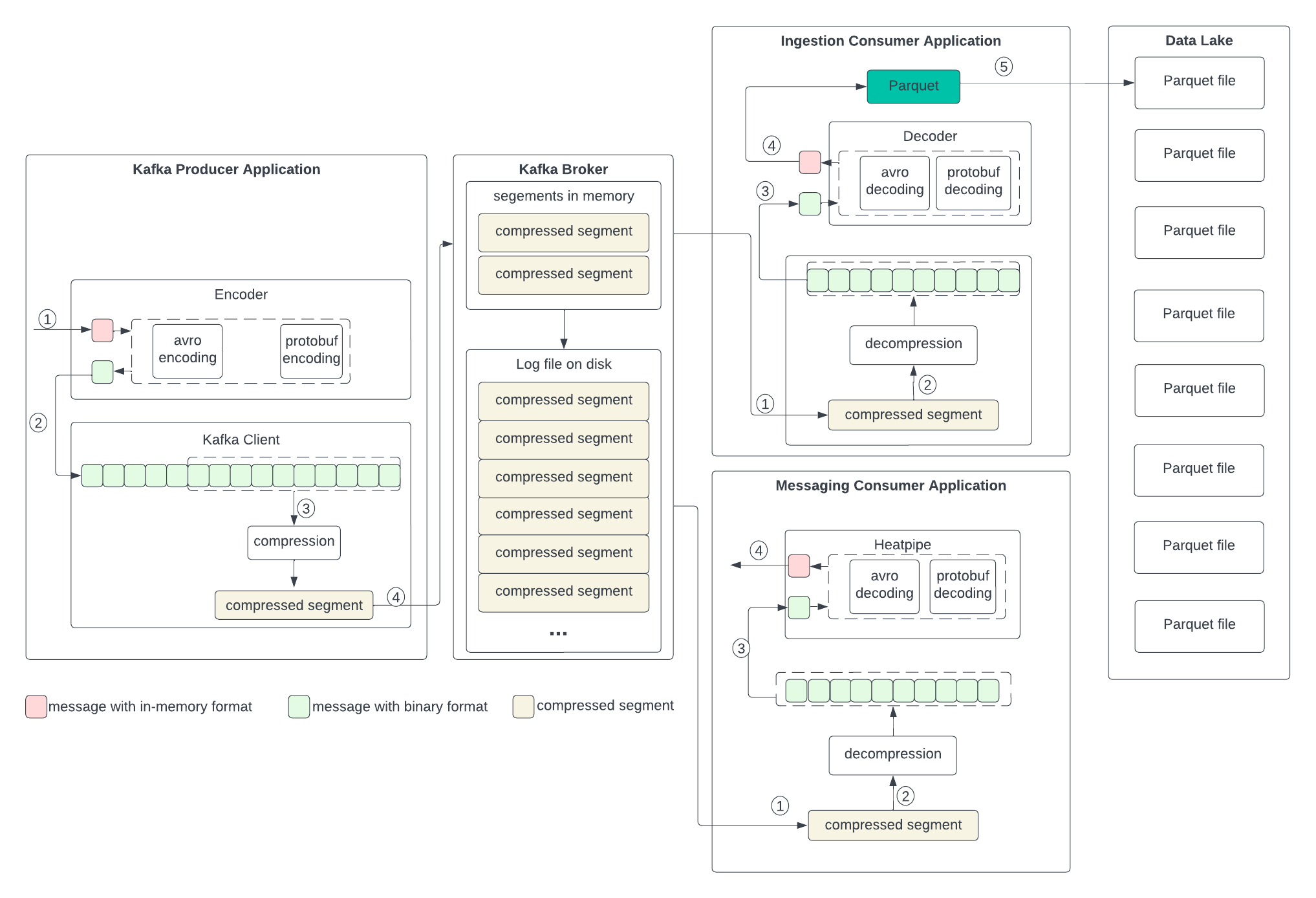
To set up the context for discussing the changes in the next section, let’s examine the current data formats in the producer, broker, and consumer, as well as the process of transformation outlined in the following diagram. We don’t anticipate changes to the broker, so we will skip discussing its format.
Producer
The producer writes the in-memory data structures to an encoder to serialize them to binary and then sends them to the Kafka client.
...
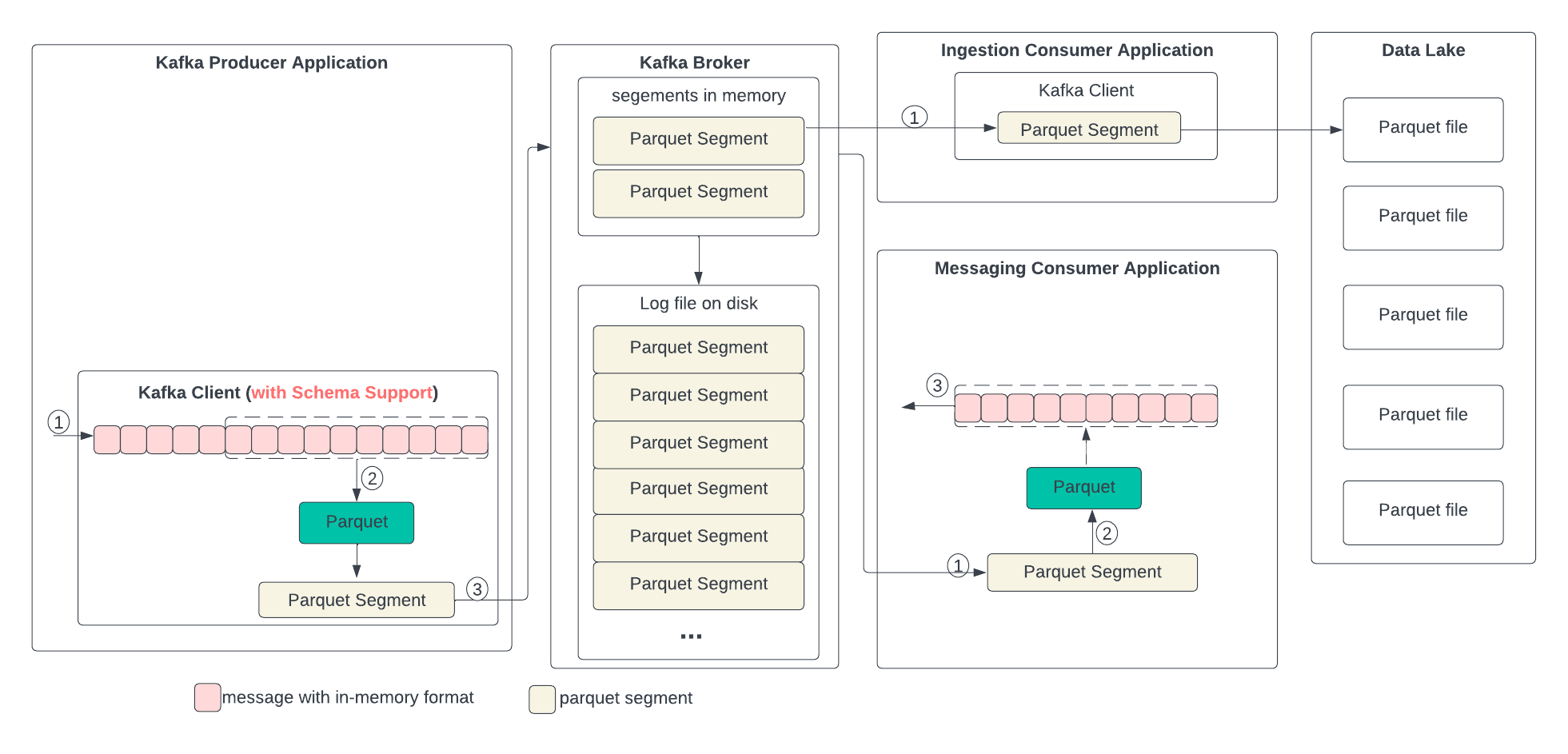
In the following diagram, we describe the proposed data format changes in each state and the process of the transformation. In short, we propose replacing compression with Parquet. Parquet combines encoding and compression at the segment level. The ingestion consumer is simplified by solely dumping the Parquet segment into the data lake.
Producer
The producer writes the in-memory data structures directly to the Kafka client and encodes and compresses all together.
...
The columnar encoding type for the data generated for a topic by the producer. The default is none (i.e., no columnar encoding). Valid values are Parquet for now and future to include ORC. When the value is not none, the key.serializer and value.serializer are disabled because the column encoder will serialize and deserialize the data. Column encoding is for full batches of data, so the efficacy of batching will also impact the efficiency of columnar encoding (more batching means better encoding).
Type: | string | |
Default: | none | |
Valid Values: | [none, parquet] | |
Importance: | low |
columnar.encoding.compression
The columnar encoders, such as Parquet, have their own compression methods. This configuration specifies the compression method in the columnar encoding. The default is none (i.e., no compression). Valid values are snappy, gzip, zstd, and lz4. When the value is not none, the data in the columnar format will be compressed using the specified method, and the specified compression in compression.type will be disabled. If the value is none, the specified compression in compression.type will work as before. Column encoding is for full batches of data, so the efficacy of batching will also impact the efficiency of columnar compression (more batching means better compression).
Type: | string |
Default: | none |
Valid Values: | [none, gzip, snappy, lz4, zstd] |
Importance: | high |
Compatibility, Deprecation, and Migration Plan
...