THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Aggregator
This applies for Camel version 2.3 or newer. If you use an older version then use this Aggregator link instead.
The Aggregator from the EIP patterns allows you to combine a number of messages together into a single message.
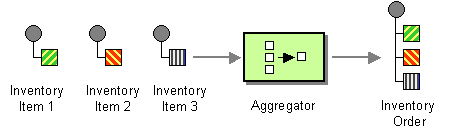
A correlation Expression is used to determine the messages which should be aggregated together. If you want to aggregate all messages into a single message, just use a constant expression. An AggregationStrategy is used to combine all the message exchanges for a single correlation key into a single message exchange.
Aggregator options
The aggregator supports the following options:
| Wiki Markup |
|---|
{div:class=confluenceTableSmall}
|| Option || Default || Description ||
| correlationExpression | | Mandatory [Expression] which evaluates the correlation key to use for aggregation. The [Exchange] which has the same correlation key is aggregated together. If the correlation key could not be evaluated an Exception is thrown. You can disable this by using the {{ignoreBadCorrelationKeys}} option. |
| aggregationStrategy | | Mandatory {{AggregationStrategy}} which is used to _merge_ the incoming [Exchange] with the existing already merged exchanges. At first call the {{oldExchange}} parameter is {{null}}. On subsequent invocations the {{oldExchange}} contains the merged exchanges and {{newExchange}} is of course the new incoming Exchange. From *Camel 2.9.2* onwards the strategy can also be a {{TimeoutAwareAggregationStrategy}} implementation, supporting the timeout callback, see further below for more details. |
| strategyRef | | A reference to lookup the {{AggregationStrategy}} in the [Registry]. From *Camel 2.12* onwards you can also use a POJO as the {{AggregationStrategy}}, see further below for details. |
| strategyMethodName | | *Camel 2.12:* This option can be used to explicit declare the method name to use, when using POJOs as the {{AggregationStrategy}}. See further below for more details. |
| strategyMethodAllowNull | {{false}} | *Camel 2.12:* If this option is {{false}} then the aggregate method is not used for the very first aggregation. If this option is {{true}} then {{null}} values is used as the {{oldExchange}} (at the very first aggregation), when using POJOs as the {{AggregationStrategy}}. See further below for more details. |
| completionSize | | Number of messages aggregated before the aggregation is complete. This option can be set as either a fixed value or using an [Expression] which allows you to evaluate a size dynamically - will use {{Integer}} as result. If both are set Camel will fallback to use the fixed value if the [Expression] result was {{null}} or {{0}}. |
| completionTimeout | | Time in millis that an aggregated exchange should be inactive before its complete. This option can be set as either a fixed value or using an [Expression] which allows you to evaluate a timeout dynamically - will use {{Long}} as result. If both are set Camel will fallback to use the fixed value if the [Expression] result was {{null}} or {{0}}. You cannot use this option together with completionInterval, only one of the two can be used. |
| completionInterval | | A repeating period in millis by which the aggregator will complete all current aggregated exchanges. Camel has a background task which is triggered every period. You cannot use this option together with completionTimeout, only one of them can be used. |
| completionPredicate | | A [Predicate] to indicate when an aggregated exchange is complete. |
| completionFromBatchConsumer | {{false}} | This option is if the exchanges are coming from a [Batch Consumer]. Then when enabled the [Aggregator2] will use the batch size determined by the [Batch Consumer] in the message header {{CamelBatchSize}}. See more details at [Batch Consumer]. This can be used to aggregate all files consumed from a [File|File2] endpoint in that given poll. |
| forceCompletionOnStop | {{false}} | *Camel 2.9* Indicates to complete all current aggregated exchanges when the context is stopped |
| eagerCheckCompletion | {{false}} | Whether or not to eager check for completion when a new incoming [Exchange] has been received. This option influences the behavior of the {{completionPredicate}} option as the [Exchange] being passed in changes accordingly. When {{false}} the [Exchange] passed in the [Predicate] is the _aggregated_ Exchange which means any information you may store on the aggregated Exchange from the {{AggregationStrategy}} is available for the [Predicate]. When {{true}} the [Exchange] passed in the [Predicate] is the _incoming_ [Exchange], which means you can access data from the incoming Exchange. |
| groupExchanges | {{false}} | If enabled then Camel will group all aggregated Exchanges into a single combined {{org.apache.camel.impl.GroupedExchange}} holder class that holds all the aggregated Exchanges. And as a result only one Exchange is being sent out from the aggregator. Can be used to combine many incoming Exchanges into a single output Exchange without coding a custom {{AggregationStrategy}} yourself. *Important:* This option does *not* support persistent repository with the aggregator. See further below for an example and more details. |
| ignoreInvalidCorrelationKeys | {{false}} | Whether or not to ignore correlation keys which could not be evaluated to a value. By default Camel will throw an Exception, but you can enable this option and ignore the situation instead. |
| closeCorrelationKeyOnCompletion | | Whether or not too _late_ Exchanges should be accepted or not. You can enable this to indicate that if a correlation key has already been completed, then any new exchanges with the same correlation key be denied. Camel will then throw a {{closedCorrelationKeyException}} exception. When using this option you pass in a {{integer}} which is a number for a LRUCache which keeps that last X number of closed correlation keys. You can pass in 0 or a negative value to indicate a unbounded cache. By passing in a number you are ensured that cache won't grow too big if you use a log of different correlation keys. |
| discardOnCompletionTimeout | {{false}} | *Camel 2.5:* Whether or not exchanges which complete due to a timeout should be discarded. If enabled then when a timeout occurs the aggregated message will *not* be sent out but dropped (discarded). |
| aggregationRepository | | Allows you to plugin you own implementation of {{org.apache.camel.spi.AggregationRepository}} which keeps track of the current inflight aggregated exchanges. Camel uses by default a memory based implementation. |
| aggregationRepositoryRef | | Reference to lookup a {{aggregationRepository}} in the [Registry]. |
| parallelProcessing | {{false}} | When aggregated are completed they are being send out of the aggregator. This option indicates whether or not Camel should use a thread pool with multiple threads for concurrency. If no custom thread pool has been specified then Camel creates a default pool with 10 concurrent threads. |
| executorService | | If using {{parallelProcessing}} you can specify a custom thread pool to be used. In fact also if you are not using {{parallelProcessing}} this custom thread pool is used to send out aggregated exchanges as well. |
| executorServiceRef | | Reference to lookup a {{executorService}} in the [Registry] |
| timeoutCheckerExecutorService | | *Camel 2.9:* If using either of the {{completionTimeout}}, {{completionTimeoutExpression}}, or {{completionInterval}} options a background thread is created to check for the completion for every aggregator. Set this option to provide a custom thread pool to be used rather than creating a new thread for every aggregator. |
| timeoutCheckerExecutorServiceRef | | *Camel 2.9:* Reference to lookup a {{timeoutCheckerExecutorService}} in the [Registry] |
| optimisticLocking | {{false}} | *Camel 2.11:* Turns on using optimistic locking, which requires the {{aggregationRepository}} being used, is supporting this by implementing the {{org.apache.camel.spi.OptimisticLockingAggregationRepository}} interface. |
| optimisticLockRetryPolicy | | *Camel 2.11.1:* Allows to configure retry settings when using optimistic locking. |
{div} |
Exchange Properties
The following properties are set on each aggregated Exchange:
| Wiki Markup |
|---|
{div:class=confluenceTableSmall}
|| header || type || description ||
| {{CamelAggregatedSize}} | int | The total number of Exchanges aggregated into this combined Exchange. |
| {{CamelAggregatedCompletedBy}} | String | Indicator how the aggregation was completed as a value of either: {{predicate}}, {{size}}, {{consumer}}, {{timeout}}, {{forceCompletion}} or {{interval}}. |
{div} |
About AggregationStrategy
The AggregationStrategy is used for aggregating the old (lookup by its correlation id) and the new exchanges together into a single exchange. Possible implementations include performing some kind of combining or delta processing, such as adding line items together into an invoice or just using the newest exchange and removing old exchanges such as for state tracking or market data prices; where old values are of little use.
Notice the aggregation strategy is a mandatory option and must be provided to the aggregator.
Here are a few example AggregationStrategy implementations that should help you create your own custom strategy.
| Code Block |
|---|
//simply combines Exchange String body values using '+' as a delimiter
class StringAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String oldBody = oldExchange.getIn().getBody(String.class);
String newBody = newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(oldBody + "+" + newBody);
return oldExchange;
}
}
//simply combines Exchange body values into an ArrayList<Object>
class ArrayListAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
Object newBody = newExchange.getIn().getBody();
ArrayList<Object> list = null;
if (oldExchange == null) {
list = new ArrayList<Object>();
list.add(newBody);
newExchange.getIn().setBody(list);
return newExchange;
} else {
list = oldExchange.getIn().getBody(ArrayList.class);
list.add(newBody);
return oldExchange;
}
}
}
|
About completion
When aggregation Exchanges at some point you need to indicate that the aggregated exchanges is complete, so they can be send out of the aggregator. Camel allows you to indicate completion in various ways as follows:
- completionTimeout - Is an inactivity timeout in which is triggered if no new exchanges have been aggregated for that particular correlation key within the period.
- completionInterval - Once every X period all the current aggregated exchanges are completed.
- completionSize - Is a number indicating that after X aggregated exchanges it's complete.
- completionPredicate - Runs a Predicate when a new exchange is aggregated to determine if we are complete or not
- completionFromBatchConsumer - Special option for Batch Consumer which allows you to complete when all the messages from the batch has been aggregated.
- forceCompletionOnStop - Camel 2.9 Indicates to complete all current aggregated exchanges when the context is stopped
Notice that all the completion ways are per correlation key. And you can combine them in any way you like. It's basically the first which triggers that wins. So you can use a completion size together with a completion timeout. Only completionTimeout and completionInterval cannot be used at the same time.
Notice the completion is a mandatory option and must be provided to the aggregator. If not provided Camel will thrown an Exception on startup.
| Tip | ||
|---|---|---|
| ||
See the |
Persistent AggregationRepository
The aggregator provides a pluggable repository which you can implement your own org.apache.camel.spi.AggregationRepository.
If you need persistent repository then you can use either Camel HawtDB, LevelDB, or SQL Component components.
Examples
See some examples from the old Aggregator which is somewhat similar to this new aggregator.
| Tip | ||
|---|---|---|
| ||
Many of the options are configurable as attributes on the |
Using completionTimeout
In this example we want to aggregate all incoming messages and after 3 seconds of inactivity we want the aggregation to complete. This is done using the completionTimeout option as shown:
| Wiki Markup |
|---|
{snippet:id=e1|lang=java|url=camel/trunk/camel-core/src/test/java/org/apache/camel/processor/aggregator/AggregateSimpleTimeoutTest.java} |
And the same example using Spring XML:
| Wiki Markup |
|---|
{snippet:id=e1|lang=xml|url=camel/trunk/components/camel-spring/src/test/resources/org/apache/camel/spring/processor/aggregator/SpringAggregateSimpleTimeoutTest.xml} |
Using TimeoutAwareAggregationStrategy
Available as of Camel 2.9.2
If your aggregation strategy implements TimeoutAwareAggregationStrategy, then Camel will invoke the timeout method when the timeout occurs. Notice that the values for index and total parameters will be -1, and the timeout parameter will be provided only if configured as a fixed value. You must not throw any exceptions from the timeout method.
Using CompletionAwareAggregationStrategy
Available as of Camel 2.9.3
If your aggregation strategy implements CompletionAwareAggregationStrategy, then Camel will invoke the onComplete method when the aggregated Exchange is completed. This allows you to do any last minute custom logic such as to cleanup some resources, or additional work on the exchange as it's now completed.
You must not throw any exceptions from the onCompletion method.
Using completionSize
In this example we want to aggregate all incoming messages and when we have 3 messages aggregated (in the same correlation group) we want the aggregation to complete. This is done using the completionSize option as shown:
| Wiki Markup |
|---|
{snippet:id=e1|lang=java|url=camel/trunk/camel-core/src/test/java/org/apache/camel/processor/aggregator/AggregateSimpleSizeTest.java} |
And the same example using Spring XML:
| Wiki Markup |
|---|
{snippet:id=e1|lang=xml|url=camel/trunk/components/camel-spring/src/test/resources/org/apache/camel/spring/processor/aggregator/SpringAggregateSimpleSizeTest.xml} |
Using completionPredicate
In this example we want to aggregate all incoming messages and use a Predicate to determine when we are complete. The Predicate can be evaluated using either the aggregated exchange (default) or the incoming exchange. We will so both situations as examples. We start with the default situation as shown:
| Wiki Markup |
|---|
{snippet:id=e1|lang=java|url=camel/trunk/camel-core/src/test/java/org/apache/camel/processor/aggregator/AggregateSimplePredicateTest.java} |
And the same example using Spring XML:
| Wiki Markup |
|---|
{snippet:id=e1|lang=xml|url=camel/trunk/components/camel-spring/src/test/resources/org/apache/camel/spring/processor/aggregator/SpringAggregateSimplePredicateTest.xml} |
And the other situation where we use the eagerCheckCompletion option to tell Camel to use the incoming Exchange. Notice how we can just test in the completion predicate that the incoming message is the END message:
| Wiki Markup |
|---|
{snippet:id=e1|lang=java|url=camel/trunk/camel-core/src/test/java/org/apache/camel/processor/aggregator/AggregateSimplePredicateEagerTest.java} |
And the same example using Spring XML:
| Wiki Markup |
|---|
{snippet:id=e1|lang=xml|url=camel/trunk/components/camel-spring/src/test/resources/org/apache/camel/spring/processor/aggregator/SpringAggregateSimplePredicateEagerTest.xml} |
Using dynamic completionTimeout
In this example we want to aggregate all incoming messages and after a period of inactivity we want the aggregation to complete. The period should be computed at runtime based on the timeout header in the incoming messages. This is done using the completionTimeout option as shown:
| Wiki Markup |
|---|
{snippet:id=e1|lang=java|url=camel/trunk/camel-core/src/test/java/org/apache/camel/processor/aggregator/AggregateExpressionTimeoutTest.java} |
And the same example using Spring XML:
| Wiki Markup |
|---|
{snippet:id=e1|lang=xml|url=camel/trunk/components/camel-spring/src/test/resources/org/apache/camel/spring/processor/aggregator/SpringAggregateExpressionTimeoutTest.xml} |
Note: You can also add a fixed timeout value and Camel will fallback to use this value if the dynamic value was null or 0.
Using dynamic completionSize
In this example we want to aggregate all incoming messages based on a dynamic size per correlation key. The size is computed at runtime based on the mySize header in the incoming messages. This is done using the completionSize option as shown:
| Wiki Markup |
|---|
{snippet:id=e1|lang=java|url=camel/trunk/camel-core/src/test/java/org/apache/camel/processor/aggregator/AggregateExpressionSizeTest.java} |
And the same example using Spring XML:
| Wiki Markup |
|---|
{snippet:id=e1|lang=xml|url=camel/trunk/components/camel-spring/src/test/resources/org/apache/camel/spring/processor/aggregator/SpringAggregateExpressionSizeTest.xml} |
Note: You can also add a fixed size value and Camel will fallback to use this value if the dynamic value was null or 0.
| Include Page | ||||
|---|---|---|---|---|
|
Manually Force the Completion of All Aggregated Exchanges Immediately
Available as of Camel 2.9
You can manually trigger completion of all current aggregated exchanges by sending a message containing the header Exchange.AGGREGATION_COMPLETE_ALL_GROUPS set to true. The message is considered a signal message only, the message headers/contents will not be processed otherwise.
Available as of Camel 2.11
You can alternatively set the header Exchange.AGGREGATION_COMPLETE_ALL_GROUPS_INCLUSIVE to true to trigger completion of all groups after processing the current message.
Using a List<V> in AggregationStrategy
Available as of Camel 2.11
If you want to aggregate some value from the messages <V> into a List<V> then we have added a org.apache.camel.processor.aggregate.AbstractListAggregationStrategy abstract class in Camel 2.11 that makes this easier. The completed Exchange that is sent out of the aggregator will contain the List<V> in the message body.
For example to aggregate a List<Integer> you can extend this class as shown below, and implement the getValue method:
| Wiki Markup |
|---|
{snippet:id=e1|lang=java|url=camel/trunk/camel-core/src/test/java/org/apache/camel/processor/aggregator/CustomListAggregationStrategyTest.java} |
Using GroupedExchanges
In the route below we group all the exchanges together using groupExchanges():
| Code Block |
|---|
from("direct:start")
// aggregate all using same expression
.aggregate(constant(true))
// wait for 0.5 seconds to aggregate
.completionTimeout(500L)
// group the exchanges so we get one single exchange containing all the others
.groupExchanges()
.to("mock:result");
|
As a result we have one outgoing Exchange being routed the the "mock:result" endpoint. The exchange is a holder containing all the incoming Exchanges.
To get access to these exchanges you need to access them from a property on the outgoing exchange as shown:
| Code Block |
|---|
List<Exchange> grouped = out.getProperty(Exchange.GROUPED_EXCHANGE, List.class); |
From Camel 2.13 onwards this behavior has changed to store these exchanges directly on the message body which is more intuitive:
| Code Block |
|---|
List<Exchange> grouped = exchange.getIn().getBody(List.class); |
| Info |
|---|
Notice the old way using the property is still present in Camel 2.13 onwards, but its considered deprecated and to be removed in Camel 3.0 onwards. |
Using POJOs as AggregationStrategy
Available as of Camel 2.12
| Tip |
|---|
You can use POJOs as AggregationStrategy with the other EIPs that supports aggregation, such as Splitter, Recipient List, etc. |
To use the AggregationStrategy you had to implement the org.apache.camel.processor.aggregate.AggregationStrategy interface, which means your logic would be tied to the Camel API. From Camel 2.12 onwards you can use a POJO for the logic and let Camel adapt to your POJO. To use a POJO a convention must be followed:
- there must be a public method to use
- the method must not be void
- the method can be static or non-static
- the method must have 2 or more parameters
- the parameters is paired so the first 50% is applied to the
oldExchangeand the reminder 50% is for thenewExchange - .. meaning that there must be an equal number of parameters, eg 2, 4, 6 etc.
The paired methods is expected to be ordered as follows:
- the first parameter is the message body
- the 2nd parameter is a Map of the headers
- the 3rd parameter is a Map of the Exchange properties
This convention is best explained with some examples.
In the method below, we have only 2 parameters, so the 1st parameter is the body of the oldExchange, and the 2nd is paired to the body of the newExchange:
| Code Block |
|---|
public String append(String existing, String next) {
return existing + next;
}
|
In the method below, we have only 4 parameters, so the 1st parameter is the body of the oldExchange, and the 2nd is the Map of the oldExchange} headers, and the 3rd is paired to the body of the {{newExchange, and the 4th parameter is the Map of the newExchange headers:
| Code Block |
|---|
public String append(String existing, Map existingHeaders, String next, Map nextHeaders) {
return existing + next;
}
|
And finally if we have 6 parameters the we also have the properties of the Exchanges:
| Code Block |
|---|
public String append(String existing, Map existingHeaders, Map existingProperties, String next, Map nextHeaders, Map nextProperties) {
return existing + next;
}
|
To use this with the Aggregate EIP we can use a POJO with the aggregate logic as follows:
| Code Block |
|---|
public class MyBodyAppender {
public String append(String existing, String next) {
return next + existing;
}
}
|
And then in the Camel route we create an instance of our bean, and then refer to the bean in the route using bean method from org.apache.camel.util.toolbox.AggregationStrategies as shown:
| Code Block |
|---|
private MyBodyAppender appender = new MyBodyAppender();
public void configure() throws Exception {
from("direct:start")
.aggregate(constant(true), AggregationStrategies.bean(appender, "append"))
.completionSize(3)
.to("mock:result");
}
|
We can also provide the bean type directly:
| Code Block |
|---|
public void configure() throws Exception {
from("direct:start")
.aggregate(constant(true), AggregationStrategies.bean(MyBodyAppender.class, "append"))
.completionSize(3)
.to("mock:result");
}
|
And if the bean has only one method we do not need to specify the name of the method:
| Code Block |
|---|
public void configure() throws Exception {
from("direct:start")
.aggregate(constant(true), AggregationStrategies.bean(MyBodyAppender.class))
.completionSize(3)
.to("mock:result");
}
|
And the append method could be static:
| Code Block |
|---|
public class MyBodyAppender {
public static String append(String existing, String next) {
return next + existing;
}
}
|
If you are using XML DSL then we need to declare a <bean> with the POJO:
| Code Block | ||||
|---|---|---|---|---|
| ||||
<bean id="myAppender" class="com.foo.MyBodyAppender"/> |
And in the Camel route we use strategyRef to refer to the bean by its id, and the strategyMethodName can be used to define the method name to call:
| Code Block | ||||
|---|---|---|---|---|
| ||||
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="myAppender" strategyMethodName="append" completionSize="3">
<correlationExpression>
<constant>true</constant>
</correlationExpression>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>
|
When using XML DSL you must define the POJO as a <bean>.
Aggregating when no data
By default when using POJOs as AggregationStrategy, then the method is only invoked when there is data to be aggregated (by default). You can use the option strategyMethodAllowNull to configure this. Where as without using POJOs then you may have null as oldExchange or newExchange parameters. For example the Aggregate EIP will invoke the AggregationStrategy with oldExchange as null, for the first Exchange incoming to the aggregator. And then for subsequent Exchanges then oldExchange and newExchange parameters are both not null.
Example with Content Enricher and no data
Though with POJOs as AggregationStrategy we made this simpler and only call the method when oldExchange and newExchange is not null, as that would be the most common use-case. If you need to allow oldExchange or newExchange to be null, then you can configure this with the POJO using the AggregationStrategyBeanAdapter as shown below. On the bean adapter we call setAllowNullNewExchange to allow the new exchange to be null.
| Code Block |
|---|
public void configure() throws Exception {
AggregationStrategyBeanAdapter myStrategy = new AggregationStrategyBeanAdapter(appender, "append");
myStrategy.setAllowNullOldExchange(true);
myStrategy.setAllowNullNewExchange(true);
from("direct:start")
.pollEnrich("seda:foo", 1000, myStrategy)
.to("mock:result");
}
|
This can be configured a bit easier using the beanAllowNull method from AggregationStrategies as shown:
| Code Block |
|---|
public void configure() throws Exception {
from("direct:start")
.pollEnrich("seda:foo", 1000, AggregationStrategies.beanAllowNull(appender, "append"))
.to("mock:result");
}
|
Then the append method in the POJO would need to deal with the situation that newExchange can be null:
| Code Block |
|---|
public class MyBodyAppender {
public String append(String existing, String next) {
if (next == null) {
return "NewWasNull" + existing;
} else {
return existing + next;
}
}
}
|
In the example above we use the Content Enricher EIP using pollEnrich. The newExchange will be null in the situation we could not get any data from the "seda:foo" endpoint, and therefore the timeout was hit after 1 second. So if we need to do some special merge logic we would need to set setAllowNullNewExchange=true, so the append method will be invoked. If we do not do that then when the timeout was hit, then the append method would normally not be invoked, meaning the Content Enricher did not merge/change the message.
In XML DSL you would configure the strategyMethodAllowNull option and set it to true as shown below:
| Code Block | ||||
|---|---|---|---|---|
| ||||
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="myAppender" strategyMethodName="append" strategyMethodAllowNull="true" completionSize="3">
<correlationExpression>
<constant>true</constant>
</correlationExpression>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>
|
Different body types
When for example using strategyMethodAllowNull as true, then the parameter types of the message bodies does not have to be the same. For example suppose we want to aggregate from a com.foo.User type to a List<String> that contains the user name. We could code a POJO doing this as follows:
| Code Block |
|---|
public static final class MyUserAppender {
public List addUsers(List names, User user) {
if (names == null) {
names = new ArrayList();
}
names.add(user.getName());
return names;
}
}
|
Notice that the return type is a List which we want to contain the user names. The 1st parameter is the list of names, and then notice the 2nd parameter is the incoming com.foo.User type.
See also
- The Loan Broker Example which uses an aggregator
- Blog post by Torsten Mielke about using the aggregator correctly.
- The old Aggregator
- HawtDB, LevelDB or SQL Component for persistence support
- Aggregate Example for an example application