THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
Producers can explicitly initiate transactional sessions, send (transactional) messages within those sessions and either commit or abort the transaction. The guarantees that we aim to achieve for transactions are perhaps best understood by enumerating the functional requirements.
- Atomicity: A consumer's application should not be exposed to messages from uncommitted transactions.
- Durability: The broker cannot lose any committed transactions.
- There should be no duplicate messages within transactions.
- Transaction ordering within a partitionOrdering: A transaction-aware consumer should see transactions in the original transaction-order within each partition.
- Interleaving: Each partition should be able to accept messages from both transactional and non-transactional producers
- There should be no duplicate messages within transactions.
If interleaving of transactional and non-transactional messages is allowed, then the relative ordering of non-transactional and transactional messages will be based on the relative order of append (for non-transactional messages) and final commit (for the transactional messages).
...
Finally, it is worth adding that any implementation should also provide the ability to associate each transaction's input state with the transaction itself. This is necessary to facilitate retries for transactions - i.e., if a transaction needs to be aborted and retried, then the entire input for that transaction needs to be replayed.
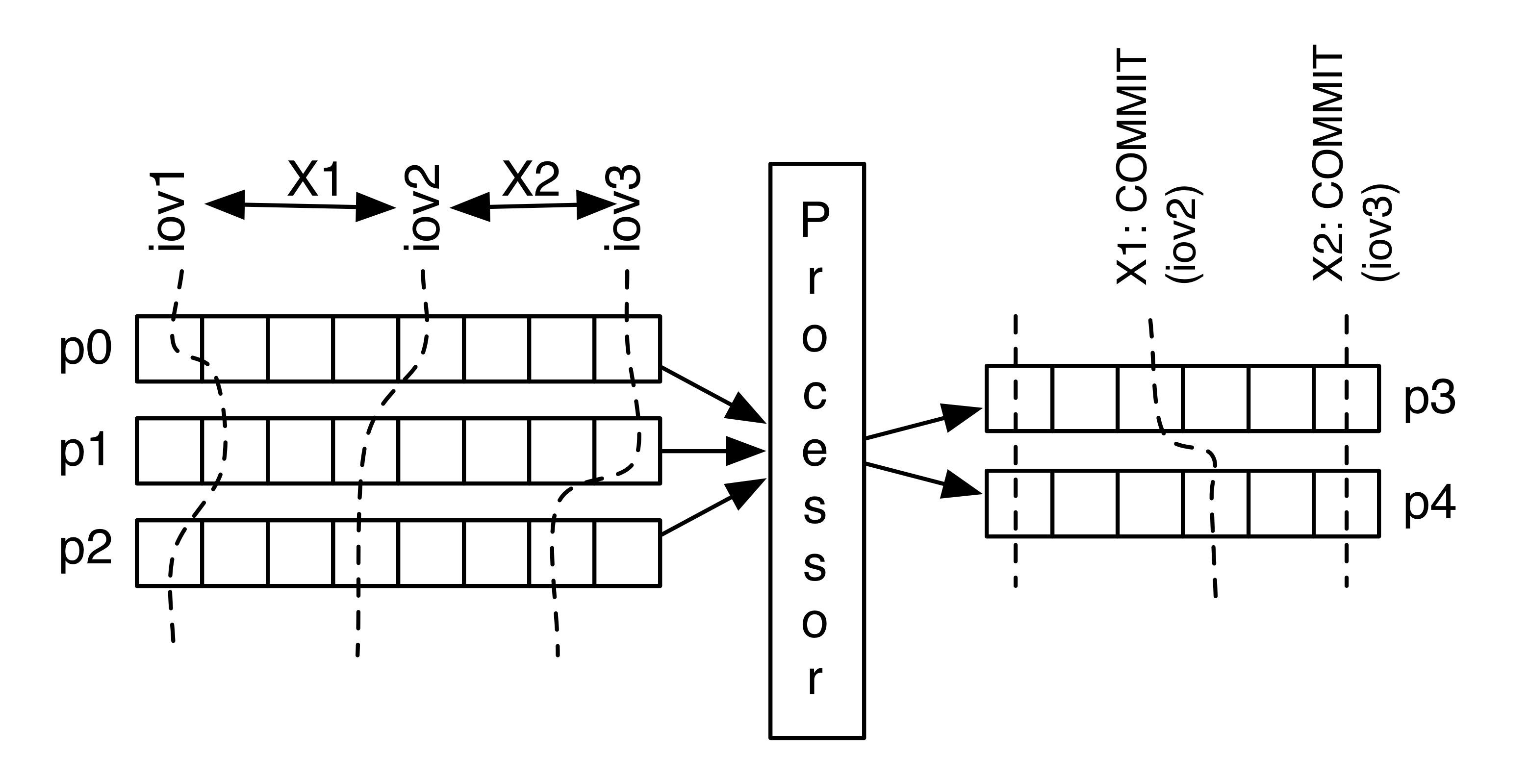 Each transaction is associated with a block of input that is processed and results in the output (transaction). When we commit the transaction we would need to also associate the next block of input with that transaction. In the event of a failure the processor would need to query (the downstream Kafka cluster) to determine the next block that needs to be processed. In our case, this would simply be an input offset vector (IOV) for the input partitions that are being processed for each transaction.
Each transaction is associated with a block of input that is processed and results in the output (transaction). When we commit the transaction we would need to also associate the next block of input with that transaction. In the event of a failure the processor would need to query (the downstream Kafka cluster) to determine the next block that needs to be processed. In our case, this would simply be an input offset vector (IOV) for the input partitions that are being processed for each transaction.
Implementation overview
In this implementation proposal, the producer sends transactional control messages that signal the begin/end/abort state of transactions to a highly-available transaction coordinator which manages transactions using a multi-phase protocol. The producer sends transaction control records (begin/end/abort) to the transaction coordinator, and sends the payload of the transaction directly to the destination data partitions. Consumers need to be transaction-aware and buffer each pending transaction until they reach its corresponding end (commit/abort) record.
- Transaction group
- Producer(s) in that transaction group
- Transaction coordinator for that transaction group
- Leader brokers (of the transaction payload's data partitions)
- Consumers of transactions
Transaction group
The transaction group is used to map to a specific transaction coordinator (say, based on a hash against the number of journal partitions). The producers in the group would need to be configured to use this group. Since all transactions from these producers go through this coordinator, we can achieve strict ordering across these transactional producers.
Producer IDs and state groups
In this section, I will go over the need to introduce two new parameters for transactional producers: producer ID and producer group. These don't necessarily need to be part of the producer configuration but may be specified as a parameter in the producer's transactional API.
The preceding overview describes the need to associate the input state of a producer (or in general a processor of some input) along with the last committed transaction. This enables the processor to redo a transaction (by recreating the input state for that transaction - which in our use cases is typically a vector of offsets).
We can utilize the consumer offset management feature to maintain this state. The consumer offset manager associates each key (consumergroup-topic-partition) to the last checkpointed offset and metadata for that partition. In the case of a transactional processor, we would want to save the offsets of its consumer that are associated with the commit point of the transaction. This offset commit record (in the __consumer_offsets topic) should be written as part of the transaction. i.e., the __consumer_offsets topic's partition that stores offsets for the consumer group will need to participate in the transaction.