THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
- the tick size (the minimum time unit)
- the wheel size (the number of buckets per wheel)
Benchmark
We compared the enqueue performance of two purgatory implementation, the current implementation and the proposed new implementation. This is a micro benchmark. It measures the purgatory enqueue performance. The purgatory was separated from the rest of the system and also uses a fake request which does nothing useful. So, the throughput of the purgatory in a real system may be much lower than the number shown by the test.
In the test, the intervals of the requests are assumed to follow the exponential distribution. Each request takes a time drawn from a log-normal distribution. By adjusting the shape of the log-normal distribution, we can test different timeout rate.
The timeout was set to 200ms. The data size of a request was 100 bytes. For a low timeout case, we chose 75percentile = 60ms and 50percentile = 20. And for a high timeout case, we chose 75percentile = 400ms and 50percentile = 200ms.
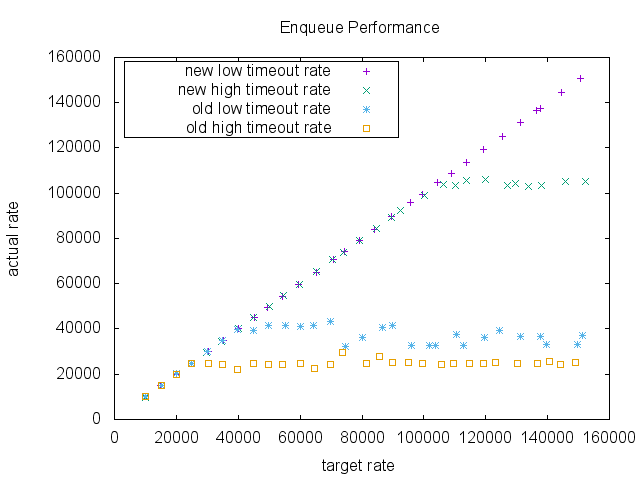
The result shows the dramatic difference in a high enqueue rate area. As the target rate increases, both implementations keep up with the requests. However, the old implementation was saturated around 60000 request per second, whereas the proposed implementation didn't show any significant performance degradation in this benchmark.Another thing worth noting is that there was a performance degradation in the current implementation when timeouts happen more often. It may be because the current implementation has to purge the delay queue and watch lists more often. The proposed implementation shows a slight degradation only when the enqueue rate was very high.
Summary
In the new design, we use Hierarchical Timing Wheels for the timeout timer, WeakReference based list for watcher lists, and DelayQueue of timer buckets to advance the clock on demand. The advantage is that a completed request is removed from the timer queue immediately and becomes GCable. When a request is completed we will immediately remove it from a timer bucket with O(1) cost. A strong reference to a request is cleared at this point. All remaining references are weak references from watcher lists, so completed requests become GCable right away. The buckets remain in the delay queue. However, the number of buckets is bounded. And, in a healthy system, most of the requests are satisfied before timeout. Many of the buckets become empty before pulled out of the delay queue. Also, the timer should rarely have the buckets of the lower interval. We expect a improvement in GC behavior and lower CPU usage.
...