THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
We summarize some key architecture design points in the following sub-sections.
Partition Distribution
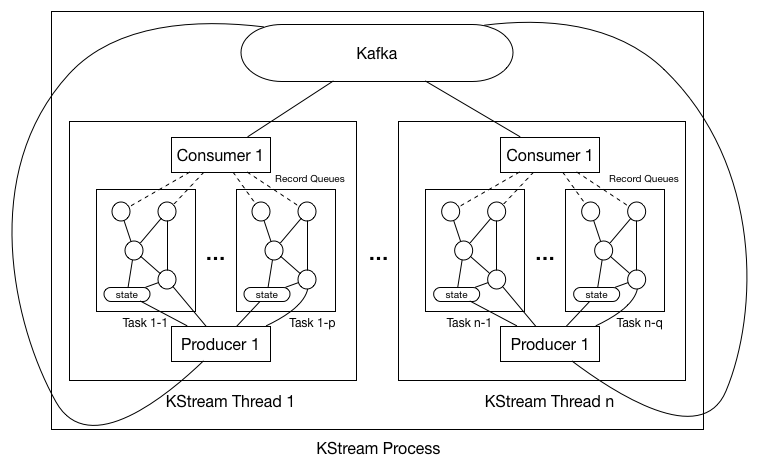
Each instance of the KafkaProcess can contain As shown in the digram above, each KStream process could have multiple threads (#.threads configurable in the properties). And users can start multiple instances of their process job. So , with each thread having a separate consumer and producer. So the first question is how can we distribute the partitions of the subscribed topics in the source processor among all the processes / threads.
...
With this new assignment protocol (details of this change can be found here), we distribute the partitions among worker thread as the following:
1. Each worker thread in the process maintains a separate consumer and producer.
2. Upon startup, each thread's consumer executes the partition assignment algorithm and gets the allocated partitions.
Stream Time and Sync.
Time in the stream processing is very important. Windowing operations (join and aggregation) are defined by time. Since Kafka can replay stream, wall-clock based time (system time) may not make sense due to delayed messages / out-of-order messages. Hence we need to define a "time" for each stream according to its progress. We call it stream time.
...
0. Upon starting the KStream process, user-specified number of KStream threads will be created. There is no shared variables between threads and no synchronization barriers as well hence these threads will execute completely asynchronously. Hence we will describe the behavior of a s single thread in all the following steps.
1. Thread constructs the user-specified processor topology without initializing it just in order to extract the list of subscribed topics from the topology.
2. Thread uses its consumer's partitionsFor() to fetch the metadata for each of the subscribed topics to get a information of topic -> #.partitions.
3. Thread now triggers consumer's subscribe() with the subscribed topics, which will then applies the new rebalance protocol. The join-group request will be instantiated as follows (for example):
| Code Block |
|---|
JoinGroupRequest =>
GroupId => "KStream-[JobName]"
GroupType => "KStream" |
And the assignor interface is implemented as follows:
| Code Block |
|---|
List<TopicPartition> assign(String consumerId,
Map<String, Integer> partitionsPerTopic,
List<ConsumerMetadata<T>> consumers) {
// 1. trigger user-customizable grouping function to group the partitions into groups.
// 2. assign partitions to consumers at the granularity of partition-groups.
// 3*. persist the assignment result using commit-offset to Kafka.
} |
The interface of the grouping function is the following, it is very similar to the assign() interface above, with the only difference that it does not have the consumer-lists.
| Code Block |
|---|
interface PartitionGrouper {
/**
* Group partitions into partition groups
*/
List<Set<TopicPartition>> group(Map<String, Integer> partitionsPerTopic)
} |
So after the rebalance completes, each partition-group will be assigned as a whole to the consumers, i.e. no partitions belonging to the same group will be assigned to different consumers. The default grouping function maps partitions with the same id across topics to into a group (i.e. co-partitioning).
4. Upon getting the partition-groups, thread creates one task for each partition-group. And for each task, constructs the processor topology AND initializes the topology with the task context.
a. Initialization process will trigger Processor.init() on each processor in the topology following topology's DAG order.
b. All user-specified local states will also be created during the initialization process. This will require the corresponding changelog to be created for the local state stores, such that:
| Code Block |
|---|
#. partition groups == #. tasks == #. store instances for each state store == #.partitions of the change log for each state store |
c. Creates the record queue for each one of the task's associated partition-group's partitions, so that when consumers fetches new messages, it will put them into the corresponding queue.
Hence all tasks' topologies have the same "skeleton" but different processor / state instantiated objects; in addition, partitions are also synchronized at the tasks basis (we will talk about partition-group synchronization in the next section).
5. When rebalance is triggered, the consumers will read its last persisted partition assignment from Kafka and checks if the following are true when comparing with the new assignment result:
a. Existing partitions are still assigned to the same partition-groups.
b. New partitions are assigned to the existing partition-groups instead of creating new groups.
For a), since the partition-group's associated task-id is used as the corresponding change-log partition id, if a partition gets migrated from one group to another during the rebalance, its state will be no longer valid; for b) since we cannot (yet) dynamically change the #.partitions from the consumer APIs, dynamically adding more partition-groups (hence tasks) will cause change log partitions possibly not exist yet.
[NOTE] there are some more advanced partitioning setting such as sticky-partitioning / consistent hashing that we want to support in the future, which may then require additionally:
c. Partition groups are assigned to the specific consumers instead of randomly / round-robin.
Stream Time and Sync.
Time in the stream processing is very important. Windowing operations (join and aggregation) are defined by time. Since Kafka can replay stream, wall-clock based time (system time) may not make sense due to delayed messages / out-of-order messages. Hence we need to define a "time" for each stream according to its progress. We call it stream time.
Stream Time
A stream is defined to abstract all the partitions of the same topic within a task, and its name is the same as the topic name. For example if a task's assigned partitions are {Topic1-P1, Topic1-P2, Topic1-P3, Topic2-P1, Topic2-P2}, then we treat this task as having two streams: "Topic1" and "Topic2" where "Topic1" represents three partitions P1 P2 and P3 of Topic1, and stream "Topic2" represents two partitions P1 and P2 of Topic2.
Each message in a stream has to have a timestamp to perform window based operations and punctuations. Since Kafka message does not have timestamp in the message header, users can define a timestamp extractor based on message content that is used in the source processor when deserializing the messages. This extractor can be as simple as always returning the current system time (or wall-clock time), or it can be an Avro decoder that gets the timestamp field specified in the record schema.
...
2. Each message has an associated timestamp that is extracted from the timestamp extractor in the message content.
3. The partition 's timestamp time is defined as the lowest message timestamp value in its buffer.
...
4. The stream time is defined as the lowest partition timestamp value across all its partitions in the processtask:
a. Since partition times are monotonically increasing, stream times are also monotonically increasing.
...
When joining two streams, their progress need to be synchronized. If they are out of sync, a time window based join becomes faulty. Say a delay of one stream is negligible and a delay of the other stream is one day, doing join over 10 minutes window does not make sense. To handle this case, we define a stream group as a set of streams whose rate of consumptions need to be synchronized. Within a process instance, such stream groups are actually instantiated as partition groups from the assigned topic partitions. Each worker need to make sure that the consumption rates of all partitions within each task's assigned partition-group are "synchronized". Note that each thread may have one or more tasks, but it does not need to synchronize the partitions across tasks' partition-groups.
Work thread synchronizes the consumption within each one of such groups through consumer's pause / resume APIs as following:
1. When one un-paused partition is a head of time (partition time defined as above) beyond some defined threshold with other partitions, notify the corresponding consumer to pause. 2. When one paused partition is ahead of time below some defined with other partitions, notify the corresponding consumer to un-pause.
consumer to pause.
2. When one paused partition is ahead of time below some defined with other partitions, notify the corresponding consumer to un-pause.
Two Users can instantiate a "grouping function" that maps the assigned partitions from the consumer into partition groups; they act as the stream groups in which the stream synchronization mechanism above is applied. The default grouping function maps partitions with the same id across topics to into a group (i.e. co-partitioning). Two streams that are joined together have to be in the same stream grouptask, and their represented partition lists have to match each other. That is, for example, a stream representing P1, P2 and P3 can be joined with another stream also representing P1, P2 and P3.
Local State Management
Users can create one or more state stores during their processing logic, and a store instance will be created for each of their specified partition groups. Since a single store instance will not be shared across multiple partition groups, and each partition group will only be processed by a single thread, this guarantees any store will not be accessed concurrently by multiple thread at any given time.
...