THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
Here's an illustration of the above pseudo-code topology:
...

This implies that after “new key” there was no to()/through() performed. The aggregation itself uses a RocksDB instance as key-value state store that also persists to local disk. Flushing to disk happens asynchronously. Furthermore, an internal compacted changelog topic is created.
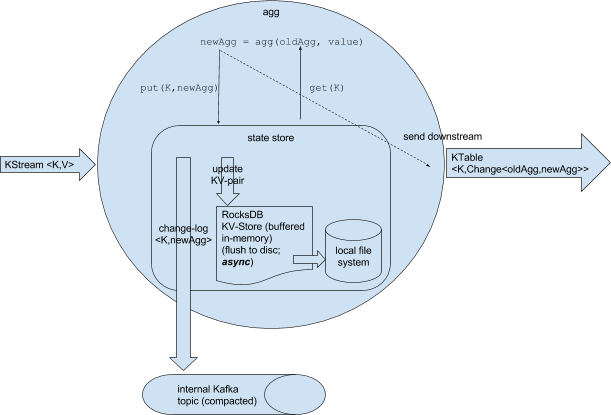
RocksDB is just used as an internal lookup table (that is able to flush to disc if the state does not fit into memory
) and the internal changelog topic is created for fault-tolerance reasons. Thus, the changelog topic is the source of truth for the state (= the log of the state), while RocksDB is used as (non-fault tolerant) cache. RocksDB cannot be used for fault-tolerance because flushing happens to local disc, and it cannot be controlled when flushing happens. RocksDB flushing is only required because state could be larger than available main-memory. Thus, the internal changelog topic is used for fault-tolerance: If a task crashes and get restarted on different machine, this internal changelog topic is used to recover the state store. Currently, the default replication factor of internal topics is 1.Jira server ASF JIRA serverId 5aa69414-a9e9-3523-82ec-879b028fb15b key KAFKA-3776
...