THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
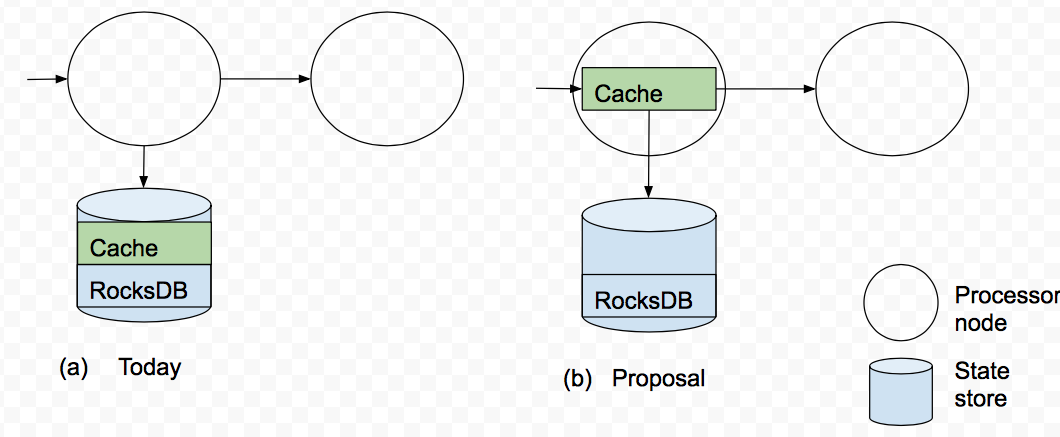
The cache has two functions. First, it continues to serve as a read buffer for data that is sent to the state store, just like today. Second, it serves as a write deduplicator for the state store (just like today) as well as for the downstream processor node(s). So the tradeoff is "getting each update, i.e., a low update delay -- but a large CPU and storage load" vs. "skipping some updates, i.e., larger update delay -- but a reduced resource load". Note that this optimization does not affect correctness. The optimization is applicable to aggregations and to operators. It is not applicable to joins.
The proposal calls for one parameter to be added to the streams configuration options:
...
The semantics of this parameter is that data is forwarded and flushed whenever the earliest of commit.interval.ms (note this parameter already exists and specifies the frequency with which a processor flushes its state) or cache pressure hits. Both parameters specify per-processor buffering time and buffering size. They These are global parameters in the sense that they apply to all processor nodes in the topology, i.e., it will not be possible to specify different parameters for each node. Such fine grained control is probably not needed from the DSL.
Continuing with the motivating example above, what is forwarded for K1, assuming all three operations hit in cache, is a final Change value <V1 + V10 + V100, null>.
For the low-level Processor API, we propose to allow users for disabling caching on a store-by-store basis using a new .enableCaching() call. For example:
TopologyBuilder builder = new TopologyBuilder();
builder.addStateStore(Stores.create("Counts").withStringKeys().withIntegerValues().persistent().enableCaching().build(), "Process");
Public Interfaces
This KIP adds the cache.max.bytes.buffering configuration to the streams configuration as described above.
This KIP adds the .enableCaching() call to the StoreFactory class for the Processor API only (this does not lead to changes in the DSL).
Proposed implementation outline
Change the RocksDB implementation for KStream windowed aggregations, to not use “range queries” but multiple gets, so that we can leverage caches for it as wellmerge range queries from the cache with range queries from RocksDb.
Extract the LRU cache out of RocksDBStore, as a separate store for KGroupedStream.aggregate() / reduce(), and KStream.aggregateByKey() / reduceByKey(). Forward entires downstream on flush or evict.
Add the LRU cache for
KTable.to()operator.Add the above config into StreamsConfig
...