THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
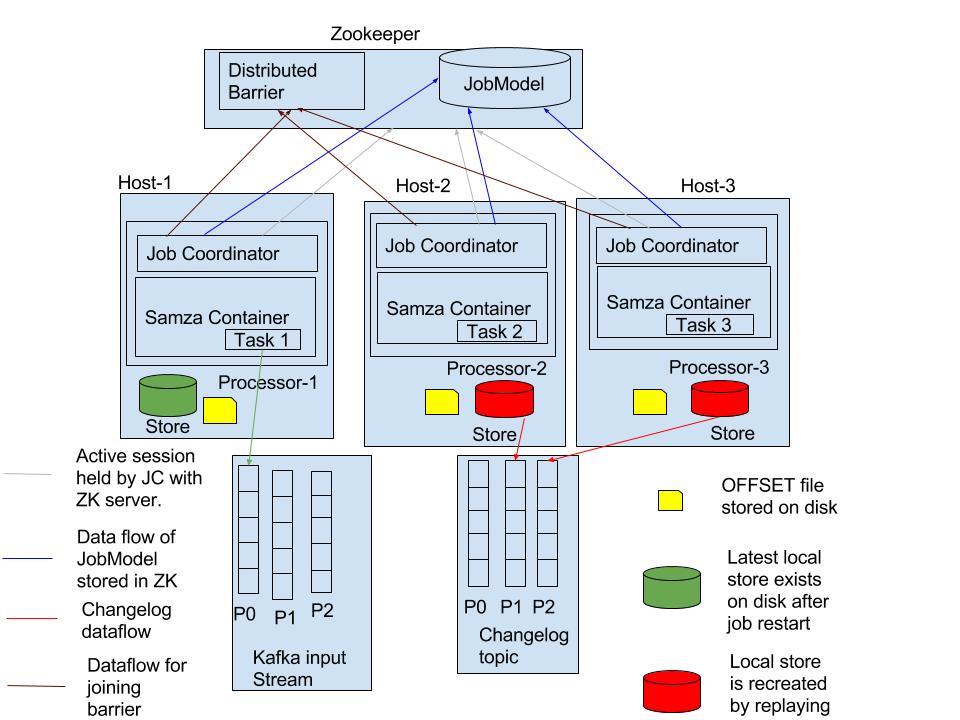
If an optimal assignment for each task to a particular processor is generated in the JobModel as part of the leader in a stateful processors group, each follower will just pick up their assignments from job model after the rebalance phase and start processing(similar to non-stateful jobs). The goal is to guarantee that the optimal assignment happens which minimizes the task movement between the processors. Local state of the tasks will be persisted in a directory(local.store.dir) provided through configuration by each processor.
ZK Data Model to support host affinity:
...
In standalone landscape, the file system location to persist the local state should be provided by the users through stream processor configuration(by defining local.store.dir configuration). It’s expected that the stream processor java process will be configured by user to run with sufficient read/write permissions to access the local state directories created by any processor in the group. The following directory structure will be used to store the local state of the stream processors with an objective to achieve store isolation between multiple stream processors running on the same machine.
When low level StreamTask/AsyncStreamTask API is used:
| Code Block | ||
|---|---|---|
| ||
- {local.store.dir}
- {jobId-jobName-1}
- {taskName-1}
- store-1
- OFFSET
- 1.sst
- {jobId-jobName-2}
- {taskName-2}
- store-2
- OFFSET
- 1.sst |
When high level fluent API is used:
| Code Block |
|---|
- {local.store.dir}
- {appId-appName-1}
- {taskName-1}
- {operatorId-1}
- store1
- OFFSET
- 1.sst
- {taskName-2}
- {operatorId-2}
- store2
- OFFSET
- 1.sst |
Remove coordinator stream bindings from JobModel:
JobModel is a data access object used to represent a samza job in both yarn and standalone deployment models. With existing implementation, JobModel requires LocalityManager(which is tied to coordinator stream) to read and populate processor locality assignments. However, since zookeeper is used as JobModel persistence layer and coordinator stream doesn’t exist in standalone landscape, it’s essential to remove this LocalityManager binding from JobModel and make JobModel immutable. It will be ideal to store task to preferred host assignment as a part of job model due to the following reasons:
Task to locality assignment information logically belongs to the JobModel itself and it makes things simpler by persisting them together.
If task to preferred host assignment and JobModel are stored separately in zookeeper in standalone, we’ll run into consistency problems between these two data sinks when performing JobModel upgrades. We’ll also lose the capability to do atomic updates of entire JobModel in zookeeper.
Any existing implementations(ClusterBasedJobCoordinator, ContainerProcessManager) which depends upon this binding for functional correctness in samza-yarn, should directly read container locality from the coordinator stream instead of getting it indirectly via JobModel.
Cleaning up ContainerModel:
ContainerModel is a data access object used in samza for holding the task to system stream partition assignments which is generated by TaskNameGrouper implementations. ContainerModel currently has two fields(processorId and containerID) used to uniquely identify a processor in a processors group. Standalone deployment model uses processorId and Yarn deployment model uses containerId field to store the unique processorId. To achieve uniformity between the two deployment models, the proposal is to remove duplicate containerId. This will not require any operational migration.
State store restoration:
Upon processor restart, nonexistent local stores will be restored following the same logic available in yarn deployment model.
Public Interfaces
Existing interface:
| Code Block | ||
|---|---|---|
| ||
public interface TaskNameGrouper {
Set<ContainerModel> group(Set<TaskModel> tasks);
default Set<ContainerModel> group(Set<TaskModel> tasks, List<String> containersIds) {
return group(tasks);
}
}
public interface BalancingTaskNameGrouper extends TaskNameGrouper {
Set<ContainerModel> balance(Set<TaskModel> tasks, LocalityManager localityManager);
}
public class ContainerModel {
@Deprecated
private final int containerId;
private final String processorId;
private final Map<TaskName, TaskModel> tasks; |
Proposed changes:
Container to physical host assignment:
When assigning tasks to a stream processor in a run, the stream processor to which the task was assigned in the previous run will be preferred. If the stream processor to which task was assigned in previous run is unavailable in the current run, the stream processors running on physical host of previous run will be given higher priority and favored. If both of the above two conditions are not met, then the task will be assigned to any stream processor available in the processor group.
Public Interfaces
| Code Block | ||
|---|---|---|
| ||
// '+' denotes addition, '-' deletion.
| ||
| Code Block | ||
public interface TaskNameGrouper {
+ @deprecated
Set<ContainerModel> group(Set<TaskModel> tasks);
+ @deprecated
default Set<ContainerModel> group(Set<TaskModel> tasks, List<String> containersIds) {
return group(tasks);
}
+ Set<ContainerModel> group(Set<TaskModel> currentGenerationTaskModels, List<String> currentGenerationContainerIds, Set<ContainerModel> previousGenerationContainerModels);
}
public interface BalancingTaskNameGrouper extends TaskNameGrouper {
+ @deprecated
Set<ContainerModel> balance(Set<TaskModel> tasks, LocalityManager localityManager);
}
public class ContainerModel {
//- ContainerId@Deprecated
field is- deleted.
private final Stringint processorIdcontainerId;
private final Map<TaskName, TaskModel> tasks;
// New field added denoting the physical hostname.String processorId;
private final Map<TaskName, StringTaskModel> hostName; |
Here are few reasons supporting the modification of TaskNameGrouper interface and removing LocalityManager from interface methods:
Any TaskNameGrouper implementation should be usable in both yarn and standalone deployment models. However, TaskNameGrouper interface definition has an explicit and tight binding with CoordinatorStream through LocalityManager and existing TaskNameGrouper implementations employs LocalityManager to read/write locality mapping from and to Coordinator stream. Coordinator stream doesn’t exist in standalone landscape and this prohibits usage of some TaskNameGrouper implementations in standalone.
Multiple group methods in TaskNameGrouper interface and additional balance method in BalancingTaskNameGrouper are logically synonymous to each other and exists to generate ContainerModels based upon the input task models and past locality assignments. It’s sensible to combine them into one interface method with adequate parameters and simplify things.
Any future TaskNameGrouper implementation could hold references to LocalityManager(a live object) and create object hierarchies based upon that reference. This will clutter the ownership of LocalityManager and could potentially create an unintentional resource leak.
Number of processors is a static configuration in yarn deployment model and a job restart is required to change the number of processors. However, an addition/deletion of a processor to a processors group in standalone is quite common and an expected behavior. Existing generators discard the task to physical host assignment when generating the JobModel. However, for standalone it’s essential to consider this detail(task to physical host assignment) between successive job model generations to accomplish optimal task to processor assignment. For instance, let’s assume stream processors P1, P2 runs on host H1 and processor P3 runs on host H3. If P1 dies, it is optimal to assign some of the tasks processed by P1 to P2. If previous task to physical host assignment is not taken into account when generating JobModel, this cannot be achieved.
Logically, a TaskNameGrouper implementation would just require the previous generation container models(to get previous task to preferred host mapping, previous task to systemstreampartition mapping) which can be passed in through the interface method to generate new mapping. Any modifications to existing assignments should be done outside of TaskNameGrouper implementation. This will make any implementation as a pure function simply operating on the passed in data.
After this change, we will have one method in TaskNameGrouper interface clearly defining the contract and all other methods in TaskNameGrouper will be deprecated(eventually removed). Host aware task to stream processors assignment in standalone will be housed in a TaskNameGrouper implementation which will be used to support this feature.
Implementation and Test Plan
Modify the existing interfaces and classes as per the proposed solution.
Add unit tests to test and validate compatibility and functional correctness.
Add a integration test in samza standalone samples to verify the host affinity feature.
Verify compatibility - Jackson, a java serialization/deserialization library is used to convert data model objects in samza into JSON and back. After removing containerId field from ContainerModel, it should be verified that deserialization of old ContainerModel data with new ContainerModel spec works.
Some TaskNameGrouper implementations assumes the comparability of integer containerId present in ContainerModel(for instance - GroupByContainerCount, a TaskNameGrouper implementation). Modify existing TaskNameGrouper implementations to take in collection of string processorId’s, as opposed to assuming that containerId is integer and lies within [0, N-1] interval(without incurring any change in functionality).
Rejected Alternatives
Approach 1
This contains all the changes mentioned in proposed solution with a differing interface changes as listed below.
Existing interfaces:
| Code Block | ||
|---|---|---|
| ||
public interface TaskNameGrouper {
Set<ContainerModel> group(Set<TaskModel> tasks);
default Set<ContainerModel> group(Set<TaskModel> tasks, List<String> containerIds) {
return group(tasks);
}
}
public interface BalancingTaskNameGrouper extends TaskNameGrouper {
Set<ContainerModel> balance(Set<TaskModel> tasks, LocalityManager localityManager);
} |
tasks;
+ // New field added denoting the physical hostname.
+ private final String hostName; |
Here are few reasons supporting the modification of TaskNameGrouper interface and removing LocalityManager from interface methods:
Any TaskNameGrouper implementation should be usable in both yarn and standalone deployment models. However, TaskNameGrouper interface definition has an explicit and tight binding with CoordinatorStream through LocalityManager and existing TaskNameGrouper implementations employs LocalityManager to read/write locality mapping from and to Coordinator stream. Coordinator stream doesn’t exist in standalone landscape and this prohibits usage of some TaskNameGrouper implementations in standalone.
Multiple group methods in TaskNameGrouper interface and additional balance method in BalancingTaskNameGrouper are logically synonymous to each other and exists to generate ContainerModels based upon the input task models and past locality assignments. It’s sensible to combine them into one interface method with adequate parameters and simplify things.
Any future TaskNameGrouper implementation could hold references to LocalityManager(a live object) and create object hierarchies based upon that reference. This will clutter the ownership of LocalityManager and could potentially create an unintentional resource leak.
Number of processors is a static configuration in yarn deployment model and a job restart is required to change the number of processors. However, an addition/deletion of a processor to a processors group in standalone is quite common and an expected behavior. Existing generators discard the task to physical host assignment when generating the JobModel. However, for standalone it’s essential to consider this detail(task to physical host assignment) between successive job model generations to accomplish optimal task to processor assignment. For instance, let’s assume stream processors P1, P2 runs on host H1 and processor P3 runs on host H3. If P1 dies, it is optimal to assign some of the tasks processed by P1 to P2. If previous task to physical host assignment is not taken into account when generating JobModel, this cannot be achieved.
Logically, a TaskNameGrouper implementation would just require the previous generation container models(to get previous task to preferred host mapping, previous task to systemstreampartition mapping) which can be passed in through the interface method to generate new mapping. Any modifications to existing assignments should be done outside of TaskNameGrouper implementation. This will make any implementation as a pure function simply operating on the passed in data.
After this change, we will have one method in TaskNameGrouper interface clearly defining the contract and all other methods in TaskNameGrouper will be deprecated(eventually removed). Host aware task to stream processors assignment in standalone will be housed in a TaskNameGrouper implementation which will be used to support this feature.
Implementation and Test Plan
Modify the existing interfaces and classes as per the proposed solution.
Add unit tests to test and validate compatibility and functional correctness.
Add a integration test in samza standalone samples to verify the host affinity feature.
Verify compatibility - Jackson, a java serialization/deserialization library is used to convert data model objects in samza into JSON and back. After removing containerId field from ContainerModel, it should be verified that deserialization of old ContainerModel data with new ContainerModel spec works.
Some TaskNameGrouper implementations assumes the comparability of integer containerId present in ContainerModel(for instance - GroupByContainerCount, a TaskNameGrouper implementation). Modify existing TaskNameGrouper implementations to take in collection of string processorId’s, as opposed to assuming that containerId is integer and lies within [0, N-1] interval(without incurring any change in functionality).
Rejected Alternatives
Approach 1
This contains all the changes mentioned in proposed solution with a differing interface changes as listed below.Proposed changes:
| Code Block | ||
|---|---|---|
| ||
public interface TaskNameGrouper {
+ @deprecated
Set<ContainerModel> group(Set<TaskModel> tasks);
+ @deprecated
default Set<ContainerModel> group(Set<TaskModel> tasks, List<String> containerIds) {
return group(tasks);
}
+ Set<ContainerModel> group(Set<TaskModel> taskModels, List<String> containerIds, LocalityManager localityManager);
}
public interface BalancingTaskNameGrouper extends TaskNameGrouper {
+ @deprecated
Set<ContainerModel> balance(Set<TaskModel> tasks, LocalityManager localityManager);
} |
...