THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
- In the embedded samza library model, users are expected to perform manual garbage collection of unused local state stores(to reduce the disk footprint) on nodes.
Proposed Changes
Overall idea intent behind this approach is to encapsulate the host aware task assignment to processors logic as a part of JobModel generation(specifically as a part of TaskNameGrouper implementation) in standalone. With existing host affinity implementation in samza-yarn, this happens outside of the JobModel generation(specifically in a ContainerAllocator implementation). The trouble with replicating this outside of JobModel generation in standalone(in the leader layer) is that, it creates an abstraction boundary spill over to the higher level layer which shouldn’t concern itself with intricacies/details of the task assignment to stream processors.
In the existing setup, host affinity in yarn is accomplished via two phases:
A. Job model generation phase which generates an optimal processor to task assignment.
B. ContainerAllocator phase which requests resources from the cluster manager for each container.
Existing model in standalone uses zookeeper for coordination amongst processors in a group. Amongst all the available processors of a stream application, a single processor will be chosen as a leader. The leader will generate the JobModel and propagate the JobModel to all other processors in the group. Distributed barrier in zookeeper will be used to block processing until the recent JobModel is picked by all the processors in the group.
Here’re the list of important and notable differences in processor and JobModel generator semantics between yarn and standalone deployment model:
- Number of processors is a static configuration in yarn deployment model and a job restart is required to change the number of processors. However, an addition/deletion of a processor to a processors group in standalone is quite common and an expected behavior.
- Existing generators discard the task to physical host assignment when generating the JobModel. However, for standalone it’s essential to consider this detail(task to physical host assignment) between successive job model generations to accomplish optimal task to processor assignment. For instance, let’s assume stream processors P1, P2 runs on host H1 and processor P3 runs on host H3. If P1 dies, it is optimal to assign some of the tasks processed by P1 to P2. If previous task to physical host assignment is not taken into account when generating JobModel, this cannot be achieved.
- Processor is assigned a physical host to run after the JobModel generation in yarn. Physical host in which processor is going to run from is known before JobModel generation phase in standalone.
- In an ideal world, any TaskNameGrouper implementation should be usable interchangeably between yarn and standalone deployment models. However, in existing setup some TaskNameGrouper’s are supported in standalone and some in yarn.
The common layer between yarn and standalone model is the TaskNameGrouper abstraction(which is part of JobModel generation phase) in which the host aware task assignment to processors will be encapsulated. If an optimal assignment for each task to a particular processor is generated in the JobModel as part of the leader in a stateful processors group, each follower will just pick up their assignments from job model after the rebalance phase and start processing(similar to non-stateful jobs). The goal is to guarantee that the optimal assignment happens which minimizes the task movement between the processors. Local state of the tasks will be persisted in a directory(local.store.dir) provided through configuration by each processor.
...
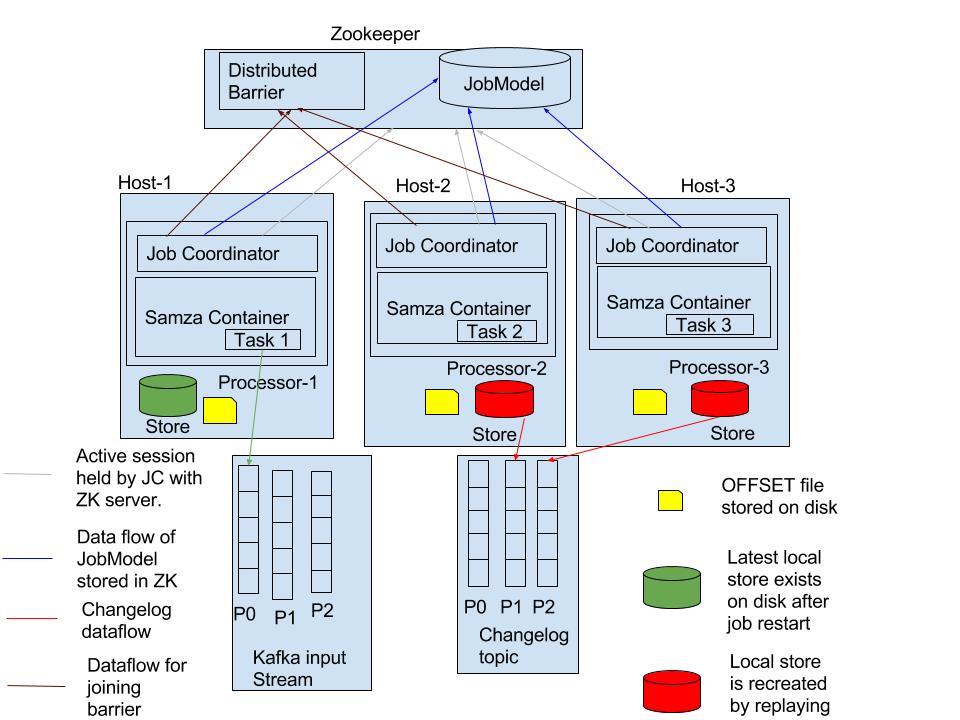


ZK Data Model to support host affinity:
...