THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
- The common layer between yarn and standalone model is the TaskNameGrouper abstraction(which is part of JobModel generation phase) which will encapsulate the host aware task assignment to processors.
- Deprecate different flavors of existing TaskNameGrouper implementations(each one of them primarily grouping TaskModel into containers) and provide a single unified contract which is agnostic and supported in different deployment models(standalone/yarn).
- Introduction of MetaDataStore abstraction to store and retrieve processor and task locality for different deployment models in appropriate storage layers. Kafka be will be used as locality storage layer for yarn and zookeeper will be used as storage layer for standalone.
- In the existing implementation, only the processor locality will be used to generate task to processor assignments. In the new model, both the last reported task locality and processor locality of a stream application will be used when generating task to processor assignments in both the yarn and standalone models.
If the leader of the stateful processors group generates an optimal, host-aware task assignment to processors within the JobModel, each follower will pick up their appropriate assignments from the JobModel and begin the processing after the rebalance phase(similar to non-stateful jobs). The goal is to guarantee that the task assignment to processors is optimal and minimizing the tasks movement between the processors.
- A new abstraction LocationIdProvider is introduced as a part of this change to generate locationId for a physical execution environment. Here’re few reasons for introducing a new abstraction to generate locationId rather than using processorID as locationId.
- LocationId denotes the physical execution environment required to run a stream processor. LocationId is used to uniquely identify a environment amongst all available physical execution environments. ProcessorId is used to uniquely identify a stream processor in a processors group. ProcessorId and localityId are two different, logically orthogonal concepts which cannot be unified.
- Standalone model supports running multiple stream processors from a single JVM on a physical host. If a stream processor(P1) running a physical host(H) dies, it’s optimal to redistribute the tasks of the dead processor(P1) to the other processors running on the host(H). If processorId is used as localityId, this optimal generation cannot be achieved(since task to localityId association is not maintained).
- In case of LinkedIn execution environment, locationId will be a composite key comprised of sliceID and sliceInstanceId. In case of kubernetes, locationId will be containerId(which will be obtained through POD API).
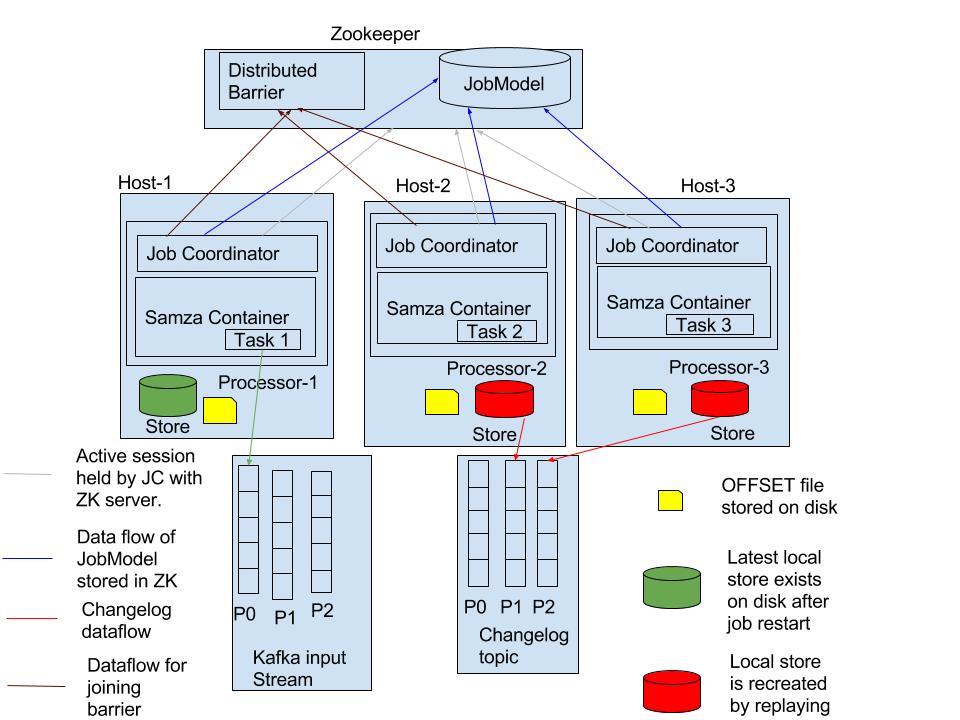


ZK Data Model to support host affinity:
...