THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
A new broker configuration will be provided to block older clients from being able to fetch messages from the brokercompletely disable down-conversion on the broker to satisfy FetchRequest from client. This configuration provides an added measure to completely disable any down-conversions on the brokerthe optimizations discussed in this KIP.
- Topic-level configuration:
minimum.consumer.fetch.versiondownconversion.enabled - Broker-level configuration:
log.minimum.consumer.fetch.versiondownconversion.enabled - Type: StringBoolean
- Possible Values: "0.8.0", "0.8.1", "0.8.2", ..., "1.1" (see ApiVersion for an exhaustive list of possible values)
- Explanation: Sets the minimum
FetchRequestAPI version for consumer fetch requests. Broker sends an UnsupportedVersionException in response to aFetchRequestfrom a client running an older version. - Default Value: "0.8.0", meaning the broker will honor all
FetchRequestversions.
The configuration accepts the broker version rather than the message format version to keep it consistent with other existing configurations like like message.format.version. Even though the configuration accepts all possible broker versions, the configuration takes effect only on certain versions where the message format actually changed. For example, setting minimum.consumer.fetch.version to "0.10.0" (which introduced message format 1) will block all clients requesting message format 0.
Proposed Changes
Message Chunking
We will introduce a message chunking approach to reduce overall memory consumption during down-conversion. The idea is to lazily and incrementally down-convert messages "chunks" in a batched fashion, and send the result out to the consumer as soon as the chunk is ready. The broker continuously down-converts chunks of messages and sends them out, until it has exhausted all messages contained in the FetchResponse, or has reached some predetermined threshold. This way, we use a small, deterministic amount of memory per FetchResponse.
The diagram below shows what a FetchResponse looks like (excluding some metadata that is not relevant for this discussion). The red boxes correspond to the messages that need to be sent out for each partition. When down-conversion is not required, we simply hold an instance of FileRecords for each of these which contains pointers to the section of file we want to send out. When sending out the FetchResponse, we use zero-copy to transfer the actual data from the file to the underlying socket which means we never actually have to copy the data in userspace.
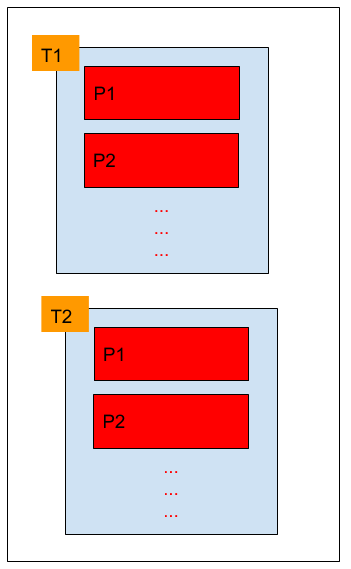
When down-conversion is required, each of the red boxes correspond to a MemoryRecords. Messages for each partition are read into JVM heap, converted to the appropriate format, and we hold on to this memory containing converted messages till the entire FetchResponse is created and subsequently sent out. There are couple of inefficiencies with this approach:
- The amount of memory we need to allocate is proportional to all the partition data in
FetchResponse. - The memory is kept referenced for an unpredictable amount of time -
FetchResponseis created in the I/O thread, queued up in theresponseQueuetill the network thread gets to it and is able to send the response out.
The idea with the chunking approach is to tackle both of these inefficiencies. We want to make the allocation predictable, both in terms of amount of memory allocated as well as the amount of time for which the memory is kept referenced. The diagram below shows what down-conversion would look like with the chunking approach. The consumer still sees a single FetchResponse which is actually being sent out in a "streaming" fashion from the broker.
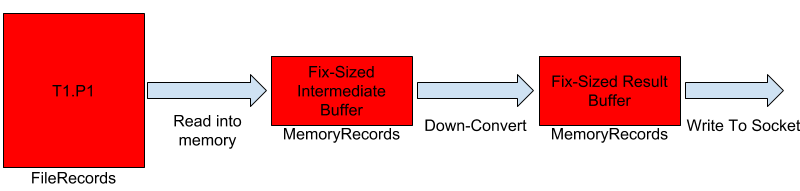
The down-conversion process works as follows:
- Read a set of message batches into memory.
- Down-convert all message batches that were read.
- Write the result buffer to the underlying socket.
- Repeat till we have sent out all the messages, or have reached a pre-determined threshold.
With this approach, we need temporary memory for to hold a batch of down-converted messages till they are completely sent out. We will limit the amount of memory required by limiting how many message batches are down-converted at a given point in time. A subtle difference also is the fact that we have managed to delay the memory allocation and the actual process of down-conversion till the network thread is actually ready to send out the results. Specifically, we can perform down-conversion when Records.writeTo is called.
Although we have increased some amount of computation and I/O for reading log segments in the network thread, this is not expected to be very significant to cause any performance degradation. We will continue performing non-blocking socket writes in the network thread, to avoid having to stall the network thread waiting for socket I/O to complete.
Messages that require lazy down-conversion are encapsulated in a new class called LazyDownConvertedRecords. LazyDownConvertedRecords#writeTo will provide implementation for down-converting messages in chunks, and writing them to the underlying socket.
- True / False
- Explanation: Controls whether down-conversion of messages is enabled to satisfy client
FetchRequest. If true, broker will down-convert messages when required. If set to false, broker will disable down-conversion of messages and will sendUnsupportedVersionExceptionin response to any clientFetchRequestthat requires down-conversion. - Default Value: True
Proposed Changes
Message Chunking
We will introduce a message chunking approach to reduce overall memory consumption during down-conversion. The idea is to lazily and incrementally down-convert messages "chunks" in a batched fashion, and send the result out to the consumer as soon as the chunk is ready. The broker continuously down-converts chunks of messages and sends them out, until it has exhausted all messages contained in the FetchResponse, or has reached some predetermined threshold. This way, we use a small, deterministic amount of memory per FetchResponse.
The diagram below shows what a FetchResponse looks like (excluding some metadata that is not relevant for this discussion). The red boxes correspond to the messages that need to be sent out for each partition. When down-conversion is not required, we simply hold an instance of FileRecords for each of these which contains pointers to the section of file we want to send out. When sending out the FetchResponse, we use zero-copy to transfer the actual data from the file to the underlying socket which means we never actually have to copy the data in userspace.
When down-conversion is required, each of the red boxes correspond to a MemoryRecords. Messages for each partition are read into JVM heap, converted to the appropriate format, and we hold on to this memory containing converted messages till the entire FetchResponse is created and subsequently sent out. There are couple of inefficiencies with this approach:
- The amount of memory we need to allocate is proportional to all the partition data in
FetchResponse. - The memory is kept referenced for an unpredictable amount of time -
FetchResponseis created in the I/O thread, queued up in theresponseQueuetill the network thread gets to it and is able to send the response out.
The idea with the chunking approach is to tackle both of these inefficiencies. We want to make the allocation predictable, both in terms of amount of memory allocated as well as the amount of time for which the memory is kept referenced. The diagram below shows what down-conversion would look like with the chunking approach. The consumer still sees a single FetchResponse which is actually being sent out in a "streaming" fashion from the broker.
The down-conversion process works as follows:
- Read a set of message batches into memory.
- Down-convert all message batches that were read.
- Write the result buffer to the underlying socket.
- Repeat till we have sent out all the messages, or have reached a pre-determined threshold.
With this approach, we need temporary memory for to hold a batch of down-converted messages till they are completely sent out. We will limit the amount of memory required by limiting how many message batches are down-converted at a given point in time. A subtle difference also is the fact that we have managed to delay the memory allocation and the actual process of down-conversion till the network thread is actually ready to send out the results. Specifically, we can perform down-conversion when Records.writeTo is called.
Although we have increased some amount of computation and I/O for reading log segments in the network thread, this is not expected to be very significant to cause any performance degradation. We will continue performing non-blocking socket writes in the network thread, to avoid having to stall the network thread waiting for socket I/O to complete.
Messages that require lazy down-conversion are encapsulated in a new class called LazyDownConvertedRecords. LazyDownConvertedRecords#writeTo will provide implementation for down-converting messages in chunks, and writing them to the underlying socket.
At a high level, At a high level, LazyDownConvertRecords looks like the following:
...
To ensure that consumer keeps making progress, Kafka makes sure that every response consists of at least one message for the first partition, even if it exceeds fetch.max.bytes and max.partition.fetch.bytes (KIP-74). When Spre < Spost (second case above), we cannot send out all the messages and need to trim message batch(es) towards the end. It is possible that we end up in a situation with a single partial batch in this case.
To prevent this from happening, we will not delay down-conversion of the first partition in the response. We will down-convert all messages of the first partition in the I/O thread (like we do today), and only delay down-conversion for subsequent partitions. This ensures that know the exact size of down-converted messages in the first partition beforehand, and can fully accomodate it in the response.
batch in this case.
To prevent this from happening, we will not delay down-conversion of the first partition in the response. We will down-convert all messages of the first partition in the I/O thread (like we do today), and only delay down-conversion for subsequent partitions. This ensures that know the exact size of down-converted messages in the first partition beforehand, and can fully accomodate it in the response.
This can be done by accepting an additional parameter doLazyConversion in KafkaApis#handleFetchRequest#convertedPartitionData which returns FetchResponse.PartitionData containing either LazyDownConvertedRecords or MemoryRecords depending on whether we want to delay down-conversion or not.
Note: To ensure consumer progress, we want to make sure that we send out at least one complete message batch. The approach above is more conservative in that it down-converts all messages in the first topic-partition. Ideally, we would only down-convert the first message batch of the first partition and delay the remaining messages to be down-converted lazily. Given that this could be a bit tricky to implement, and the fact that the maximum fetch size for one topic-partition is limited to 1MB by default, we can revisit this optimization in the futureThis can be done by accepting an additional parameter doLazyConversion in KafkaApis#handleFetchRequest#convertedPartitionData which returns FetchResponse.PartitionData containing either LazyDownConvertedRecords or MemoryRecords depending on whether we want to delay down-conversion or not.
Determining number of batches to down-convert
...