THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
We can solve both of these issues by introducing the concept of a Leader Epoch. This allocates an identifier to a period of leadership, which is then added to each message by the leader. Each replica keeps a vector of [LeaderEpoch => StartOffset] to mark when leaders changed throughout the lineage of its log. This vector then replaces the high watermark when followers need to truncate data (and will be stored in a file for each replica). So instead of a follower truncating to the High Watermark, the follower gets the appropriate LeaderEpoch from the leader’s vector of past LeaderEpochs and uses this to truncate only messages that do not exist in the leader’s log. So the leader effectively tells the follower what offset it needs to truncate to.
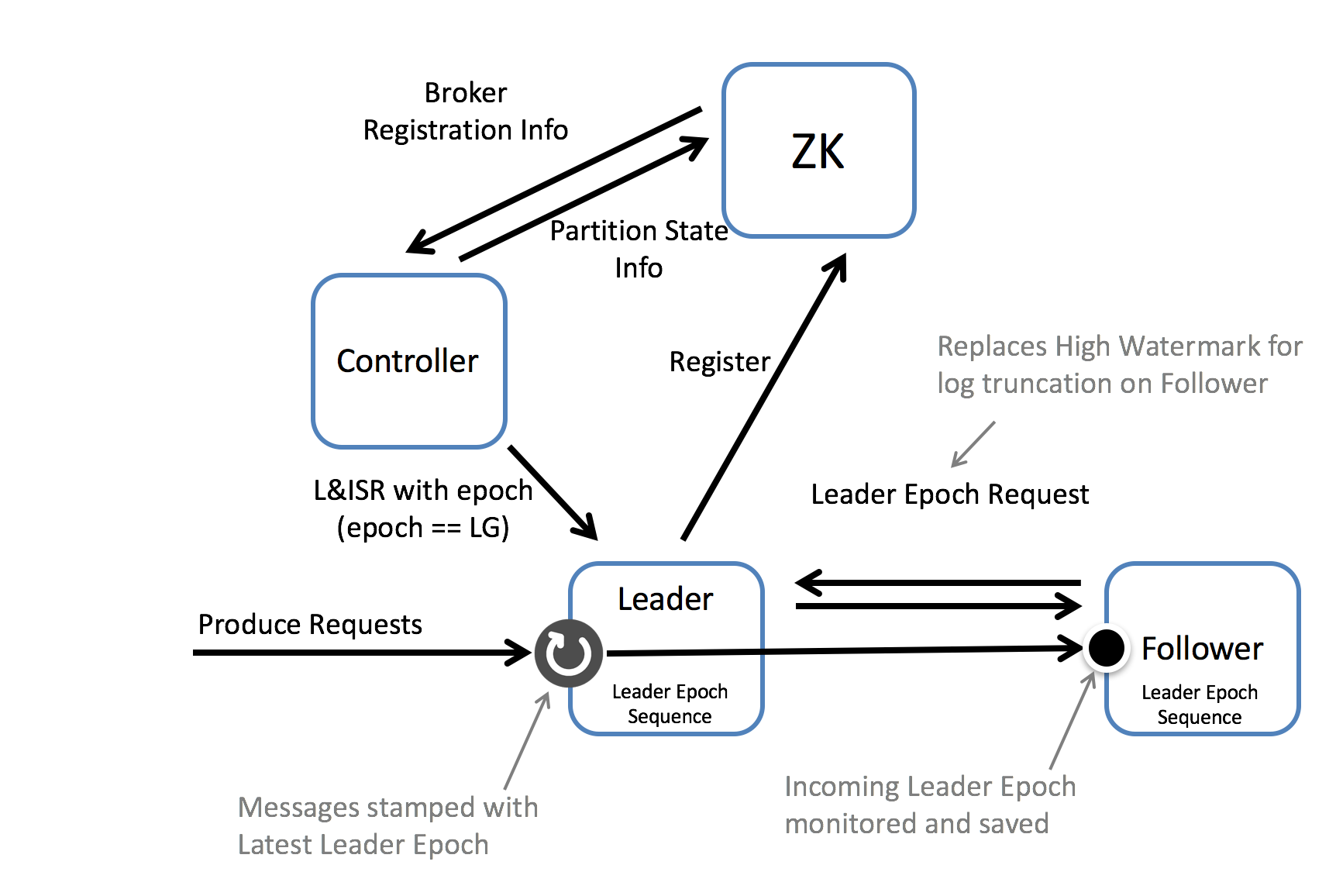

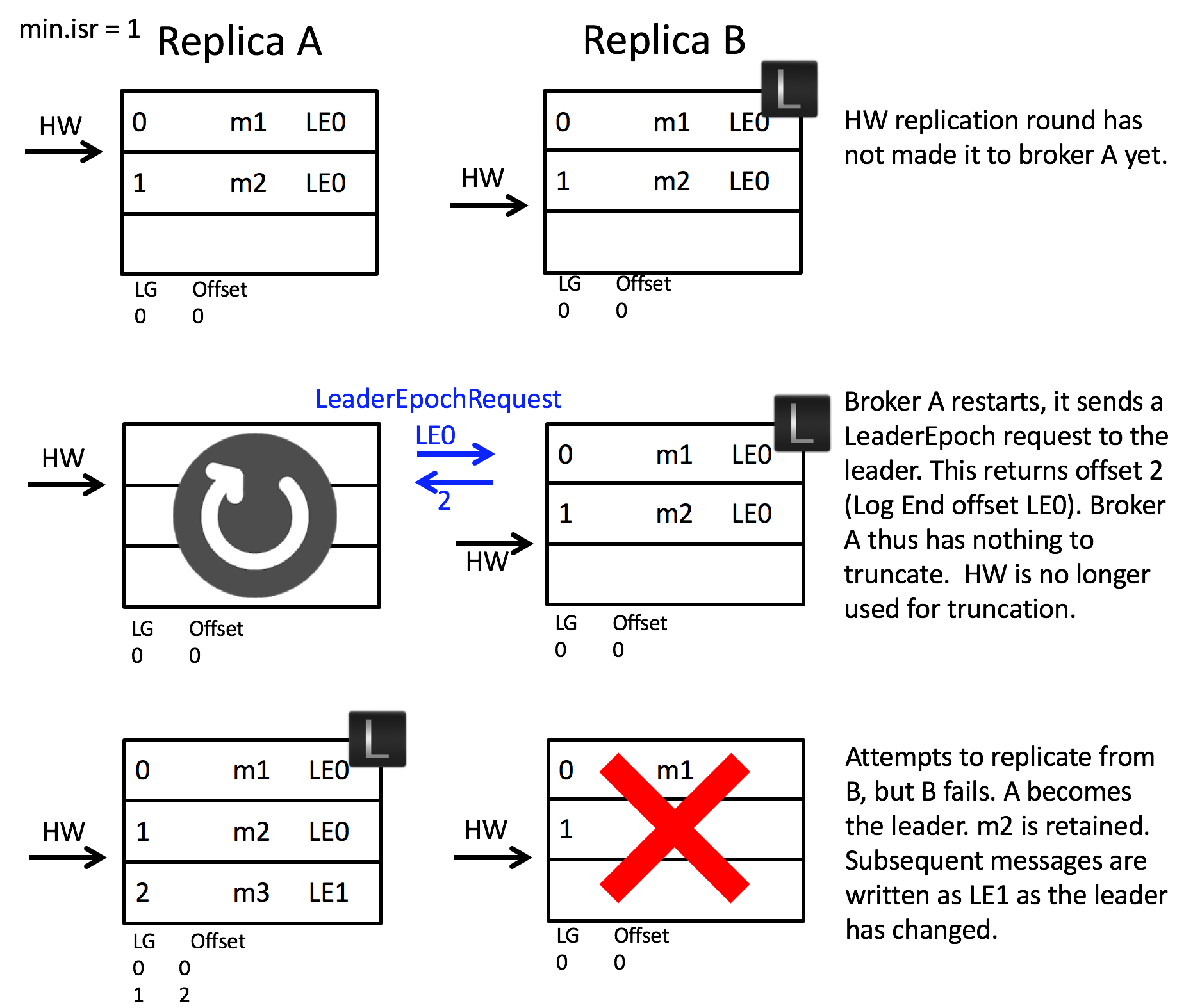
We can walk through the implementation of this by addressing scenario 1:
...
In this case the LeaderEpochResponse returns offset 2. Note this is different to the high watermark which, on the follower, is offset 0. Thus the follower does not truncate any messages and hence message m2 is not lost.

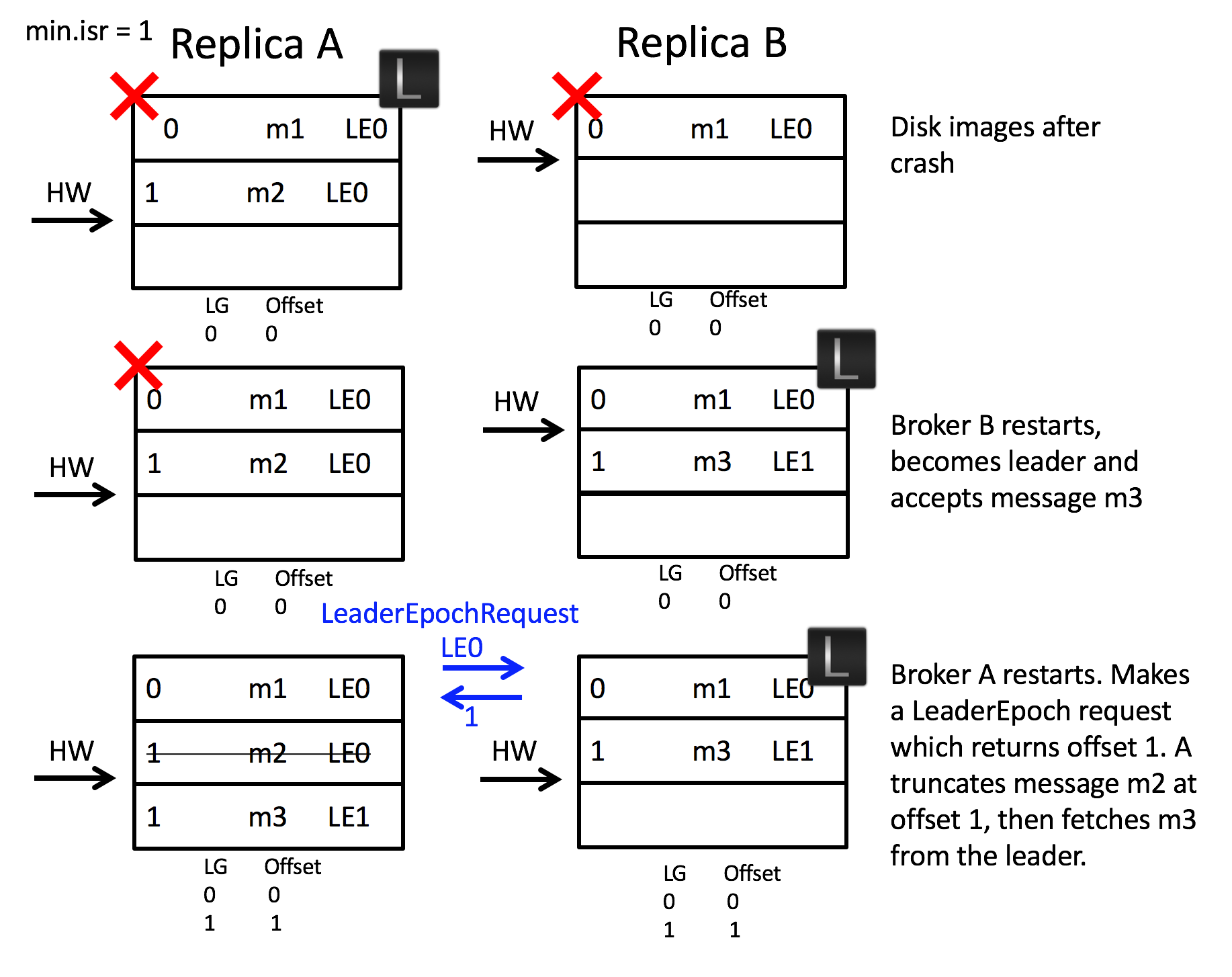
This approach also addresses scenario 2:
When the two brokers restart after a crash, broker B becomes leader. It accepts message m3 but with a new Leader Epoch, LG1LE1. Now when broker A starts, and becomes a follower, it sends a LeaderEpoch request to the leader. This returns the first offset of LG1LE1, which is offset 1. The follower knows that m2 is orphaned and truncates it. It then fetches from offset 1 and the logs are consistent.

NB: It should be noted that this proposal does not protect against log divergence for clusters that use the setting unclean.leader.election.enable=true. (See the appendix for more details.)
...