THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
A simple implementation may use a thread that wakes up every unit time and do the ticking, which checks if there is any task in the bucket. This can be wasteful if requests are sparse. We want the thread to wake up only when when there is a non-empty bucket to expire. We will do so by using java.util.concurrent.DelayQueue similarly to the current implementation, but we will enqueue task buckets instead of tasks. This design has a performance advantage. The number of items in DelayQueue is capped by the number of buckets, which is usually much smaller than the number of tasks, thus the number of offer/poll operations to the priority queue inside DelayQueue will be significantly smaller.
Purge of Watcher Lists
In the current implementation, the purge operation of watcher lists is triggered by the total size if the watcher lists. The problem is that the watcher lists may exceed the threshold even when there isn't many to purge. When this happens it increases the CPU load a lot. Ideally, the purge operation should be triggered by the number of completed requests the watcher lists.
In the new design, a completed request is removed from the timer queue immediately with O(1) cost. It means that the number of requests in the timer queue is the number of pending requests exactly at any time. So, if we know the total number of distinct requests in the purgatory, which includes the sum of the number of pending request and the numbers completed but still watched requests, we can avoid unnecessary purge operations. It is not trivial to keep track of the exact number of distinct requests in the purgatory because a request may or my not be watched. In the new design, we estimate the total number of requests in the purgatory rather than trying to maintain the exactly number.
The estimate number of requests are maintained as follows. the estimated total number of requests, E, is increments whenever a new request is watched. Before starting the purge operation completes, we reset the estimated total number of requests to the size of timer queue. If no requests are added to the purgatory during purge, E is the correct number of request after purge. If some requests are added to the purgatory during purge, E is incremented to E + the number of newly watched requests, and this may be an overestimation because it is possible that some of the new requests are completed and remove from the watcher lists during the purge. We expect the chance of overestimation is small. And on average the the number of purged requests and the estimated number of request to purge become closer if overestimations constantly happens.
Parameters
- the tick size (the minimum time unit)
- the wheel size (the number of buckets per wheel)
...
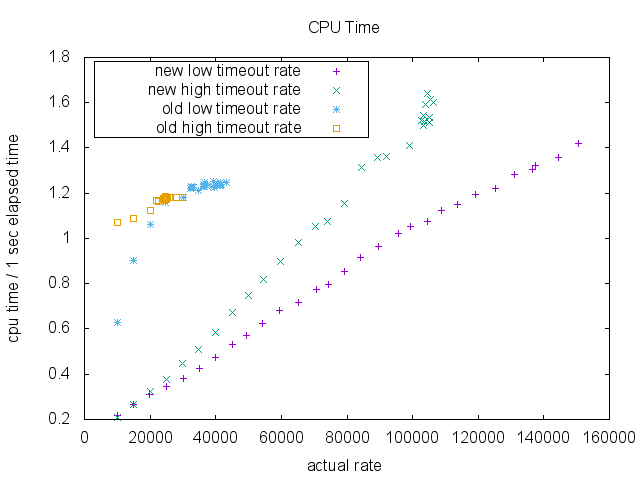
CPU usage is significantly better in the new implementation.
Finally, we measured total GC time (milliseconds) for ParNew collection and CMS collection. There isn't much difference in the old implementation and the new implementation in the region of enqueue rate that the old implementation can sustain.
...
In the new design, we use Hierarchical Timing Wheels for the timeout timer and DelayQueue of timer buckets to advance the clock on demand. The advantage is that a completed request is Completed requests are removed from the timer queue immediately and becomes GCable. When a request is completed we will immediately remove it from a timer bucket with O(1) cost. A strong reference to a request is cleared at this point. All remaining references are weak references from watcher lists, so completed requests become GCable right away. The The buckets remain in the delay queue. However, however, the number of buckets is bounded. And, in a healthy system, most of the requests are satisfied before timeout. Many , and many of the buckets become empty before pulled out of the delay queue. AlsoThus, the timer should rarely have the buckets of the lower interval. We expect a improvement in GC behavior and lower CPU usageThe advantage of this design is that the number of requests in the timer queue is the number of pending requests exactly at any time. This allows us to estimate the number of requests need to be purged. We can avoid unnecessary purge operation of the watcher lists. As the result we achieve a higher scalability in terms of request rate with much better CPU usage.