THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
| Table of Contents |
|---|
Over several years of usage we have run into a number of complaints about the scala client. This is a proposal for addressing these complaints.
...
As today we will have a single background thread that does message collation, serialization, and compression. However this thread will now run an event loop to simultaneously send requests and receive responses from all brokers.
Consumer API
Here is an example of the proposed consumer API:
| Code Block |
|---|
Consumer consumer = new Consumer(props);
consumer.addTopic("my-topic"); // consume dynamically assigned partitions
consumer.addTopic("my-other-topic", 3); //
long timeout = 1000;
while(true) {
List<MessageAndOffset> messages = consumer.poll(timeout);
process(messages);
consumer.commit(); // alternately consumer.commit(topic) or consumer.commit(topic, partition)
}
|
As before the consumer group is set in the properties and for simplicity each consumer can belong to only one group.
addTopic is used to change the set of topics the consumer consumes. If the user gives only the topic name it will automatically be assigned a set of partitions based on the group membership protocol below. If the user specifies a partition they will be statically assigned that partition.
The actual partition assignment can be made pluggable (see the proposal on group membership below) by setting an assignment strategy in the properties.
This api allows alternative methods for managing offsets as today by simply disabling autocommit and not calling commit().
Implementation
The client would be entirely single threaded.
The poll() method executes the network event loop, which includes the following:
- Checks for group membership changes
- Sends a heartbeat to the controller if needed
- Issues a fetch request to all brokers for which the consumer currently is consuming
- Reads any available fetch responses
- Issues metadata requests when requests fail to get the new cluster topology
The timeout the user specifies will be purely to ensure we have a mechanism to give control back to the user even when no messages are delivered. It is up to the user to ensure poll() is called again within the heartbeat frequency set for the consumer group. Internally the timeout on our select() may uses a shorter timeout to ensure the heartbeat frequency is met even when no messages are delivered.
Consumer Group Membership Protocol
We will introduce a set of RPC apis for managing partition assignment on the consumer side. This will be based on the prototype here. This set of APIs is orthogonal to the APIs for producing and consuming data, it is responsible for group membership.
My proposal would be to actually not handle partition assignment at all. The only facility we need to offer is a group membership facility. If all consumers agree on who exists the consumer client implementation can implement any partition assignment it likes.
api | sender | fields | returns | description | issue to |
|---|---|---|---|---|---|
list_groups | client | group_name (optional) | group_name | Returns metadata for one or more groups. If issued with a group_name it returns metadata for just that group. If no group_name is given it returns metadata for all active groups. This request can be issued to any server. | any server |
create_group | client | group_name | group_name | Create a new group with the given name and the specified minimum heartbeat frequency. Return the id/host/port of the server acting as the controller for that group. | any server |
delete_group | client | group_name | ack | Deletes a non-emphemeral group (but only if it has no members) | controller |
join_group | client | group_name | no response | Ask to join the given group | controller |
im_alive | client | group_generation | no response | This heartbeat message must be sent by the consumer to the controller with an SLA specified in the create_group command. The client can and should issues these more frequently to avoid accidentally timing out. | controller |
The use of this protocol would be as follows:
On startup or when co-ordinator heartbeat fails -
- on startup the consumer issues a list_groups(my_group) to a random broker to find out the location of the controller for its group (each server is the controller for some groups)
- knowing where the controller is, it connects and issues a RegisterConsumer RPC, then it awaits a RegisterConsumerResponse
- on receiving the RegisterConsumer request the server sends an error code in the HeartbeatResponse to all alive group members and waits for a new RegisterConsumer request from each consumer, except the one that sent the initial RegisterConsumer.
- on receiving an error code in the HeartbeatResponse, all consumers stop fetching, commit offsets, re-discover the controller through list_groups(my_group) and send a RegisterConsumer request to the controller
- on receiving RegisterConsumer from all consumers of the group membership change, the controller sends the RegisterConsumerResponse to all the new group members, with the partitions and the respective offsets to restart consumption from
- on receiving the RegisterConsumerResponse the consumer is now able to start consuming its partitions and must now start sending heartbeat messages back to the controller with the current generation id.
When new partitions are added to existing topics or new topics are created -
In 0.8, the producer throughput is limited due to the synchronous interaction of the producer with the broker. At a time, there can only be one request in flight per broker and that hurts the throughput of the producer severely. The problem with this approach also is that it doesn't take advantage of parallelism on the broker where requests for different partitions can be handled by different request handler threads on the broker, thereby increasing the throughput seen by the producer.
Key idea behind the design
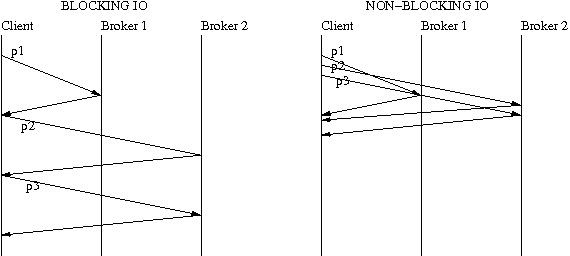
Request pipelining allows multiple requests to the same broker to be in flight. The idea is to do I/O multiplexing using select(), epoll(), wait() and wait for at least one readable or writable socket instead of doing blocking reads and writes. So if a producer sends data to 3 partitions on 2 brokers, the difference between blocking sends/receives and pipelined sends/receives can be understood by looking at the following picture
Design requirements
- Ordering should be maintained per partition, if there are no retries.
- Existing producer API should remain completely asynchronous.
- No APIs changes are necessary to roll this out.
Proposed design
There are 2 threads, depending on how metadata requests are handled.
- Client thread - partitions
- Send thread - refreshes metadata, serializes, collates, batches, sends data and receives acknowledgments
Event Queuing
There are 2 choices here -
One queue per partition
There will be one queue with partition "-1" per topic. The events with null key will enter this queue. There will be on "undesignated" partition queue per topic. This is done to prevent fetching metadata on the client thread when the producer sends the first message for a new topic.
Pros:
- More isolation within a topic. Keys that are high traffic will not affect keys that are lower traffic within a topic. This will protect important low throughput topics like audit data.
- Easier to handle the most common error which is leader transition. It is easier with one queue per partition since you can just ignore the queues for partitions that don't have leaders yet.
Cons:
- More queues means more memory overhead, especially for tools like MirrorMaker.
- Handling time based event expiration per partition queue complicates the code to some extent.
One queue for all topics and partitions.
Pros:
Less memory overhead since there is only one queue data structure for all events
Cons:
- Less isolation. One high throughput topic or partition can cause data for other topics to be dropped. This especially hurts audit data and can be easily avoided by having multiple queues.
- Complicates batching since you will have to find a way to skip over partitions that don't have leaders and avoid dequeueing their data until a leader can be discovered.
Partitioning
Partitioning can happen before the event enters the queue. The advantage is that the event does not require re-queuing if one queue per partition approach is used. Events with null key will be queued to the <topic>-"-1" queue.
Metadata discovery
When a producer sends the first message for a new topic, it enters the <topic>-undesignated queue. The metadata fetch happens on the event thread. There are 2 choices on how the metadata fetch request will work -
The metadata fetch is a synchronous request in the event loop.
Pros:
Simplicity of code
Cons:
If leaders only for a subset of partitions have changed, a synchronous metadata request can potentially hurt the throughput for other topics/partitions.
Metadata fetch is non blocking
Pros:
More isolation, better overall throughput
Serialization
One option is doing this before the event enters the queue and after partitioning. Downside is potentially slowing down the client thread if compression or serialization takes long. Another option is to just do this in the send thread, which seems like a better choice.
Batching and Collation
Producer maintains a map of broker to list of partitions that the broker leads. Batch size is per partition. For each broker, if the key is in write state, the producer's send thread will poll the queues for the partitions that the broker leads. Once the batch is full, it will create a ProducerRequest with the partitions and data, compress the data, and writes the request on the socket. This happens in the event thread while handing new requests. The collation logic gets a little complicated if there is only one queue for all topics/partitions.
Compression
When the producer send thread polls each partition's queue, it compresses the batch of messages that it dequeues.
Event loop
| Code Block |
|---|
while(isRunning)
{
// configure any new broker connections
// select readable keys
// handle responses
// select writable keys
// handle topic metadata requests, if there are non-zero partitions in error
// handle incomplete requests
// handle retries, if any
// handle new requests
}
|
Consumer API
Here is an example of the proposed consumer API:
| Code Block |
|---|
Consumer consumer = new Consumer(props);
consumer.addTopic("my-topic"); // consume dynamically assigned partitions
consumer.addTopic("my-other-topic", 3); //
long timeout = 1000;
while(true) {
List<MessageAndOffset> messages = consumer.poll(timeout);
process(messages);
consumer.commit(); // alternately consumer.commit(topic) or consumer.commit(topic, partition)
}
|
As before the consumer group is set in the properties and for simplicity each consumer can belong to only one group.
addTopic is used to change the set of topics the consumer consumes. If the user gives only the topic name it will automatically be assigned a set of partitions based on the group membership protocol below. If the user specifies a partition they will be statically assigned that partition.
The actual partition assignment can be made pluggable (see the proposal on group membership below) by setting an assignment strategy in the properties.
This api allows alternative methods for managing offsets as today by simply disabling autocommit and not calling commit().
Implementation
The client would be entirely single threaded.
The poll() method executes the network event loop, which includes the following:
- Checks for group membership changes
- Sends a heartbeat to the controller if needed
- Issues a fetch request to all brokers for which the consumer currently is consuming
- Reads any available fetch responses
- Issues metadata requests when requests fail to get the new cluster topology
The timeout the user specifies will be purely to ensure we have a mechanism to give control back to the user even when no messages are delivered. It is up to the user to ensure poll() is called again within the heartbeat frequency set for the consumer group. Internally the timeout on our select() may uses a shorter timeout to ensure the heartbeat frequency is met even when no messages are delivered.
Consumer Group Membership APIs
We will introduce a set of RPC apis for managing partition assignment on the consumer side. This will be based on the prototype here. This set of APIs is orthogonal to the APIs for producing and consuming data, it is responsible for group membership.
api | sender | description | issue to |
|---|---|---|---|
ListGroups | client | Returns metadata for one or more groups. If issued with a list of GroupName it returns metadata for just those groups. If no GroupName is given it returns metadata for all active groups. This request can be issued to any server. | any server |
CreateGroup | client | Create a new group with the given name and the specified minimum heartbeat frequency. Return the id/host/port of the server acting as the controller for that group. | any server |
DeleteGroup | client | Deletes a non-emphemeral group (but only if it has no members) | controller |
RegisterConsumer | client | Ask to join the given group. This happens as part of the event loop that gets invoked when the consumer uses the poll() API | controller |
Heartbeat | client | This heartbeat message must be sent by the consumer to the controller with an SLA specified in the CreateGroup command. The client can and should issues these more frequently to avoid accidentally timing out. | controller |
Heartbeat
| Code Block |
|---|
Heartbeat
Version => int16
CorrelationId => int64
ClientId => string
SessionTimeout => int64
|
HeartbeatResponse
| Code Block |
|---|
Version => int16
CorrelationId => int64
ControllerGeneration => int64
ErrorCode => int16 // error code is non zero if the group change is to be initiated
|
CreateGroup
| Code Block |
|---|
Version => int16
CorrelationId => int64
ClientId => string
ConsumerGroup => string
SessionTimeout => int64
Topics => [string]
|
CreateGroupResponse
| Code Block |
|---|
Version => int16
CorrelationId => int64
ConsumerGroup => string
ErrorCode => int16
|
DeleteGroup
| Code Block |
|---|
Version => int16
CorrelationId => int64
ClientId => string
ConsumerGroup => [string]
|
DeleteGroupResponse
| Code Block |
|---|
Version => int16
CorrelationId => int64
DeletedConsumerGroups => [string]
ErrorCode => int16
|
RegisterConsumer
| Code Block |
|---|
Version => int16
CorrelationId => int64
ClientId => string
ConsumerGroup => string
ConsumerId => string
|
RegisterConsumerResponse
| Code Block |
|---|
Version => int16
CorrelationId => int64
ClientId => string
ConsumerGroup => string
PartitionsToOwn => [{Topic Partition Offset}]
Topic => string
Partition => int16
Offset => int64
ErrorCode => int16
|
ListGroups
| Code Block |
|---|
Version => int16
CorrelationId => int64
ClientId => string
ConsumerGroups => [string]
|
ListGroupsResponse
| Code Block |
|---|
Version => int16
CorrelationId => int64
ClientId => string
GroupsInfo => [{GroupName, GroupMembers, Topics, ControllerBroker, SessionTimeout}]
GroupName => string
GroupMembers => [string]
Topics => [string]
ControllerBroker => Broker
Broker => BrokerId Host Port
BrokerId => int32
Host => string
Port => int16
ErrorCode => int16
|
RewindConsumer
| Code Block |
|---|
Version => int16
CorrelationId => int64
ClientId => string
ConsumerGroup => string
NewOffsets => [{Topic Partition Offset}]
Topic => string
Partition => int16
Offset => int64
|
RewindConsumerResponse
| Code Block |
|---|
Version => int16
CorrelationId => int64
ConsumerGroup => string
ActualOffsets => [{Topic Partition Offset}]
Topic => string
Partition => int16
Offset => int64
ErrorCode => int16
|
Consumer Group Membership Protocol
The use of this protocol would be as follows:
On startup or when co-ordinator heartbeat fails -
- on startup the consumer issues a list_groups(my_group) to a random broker to find out the location of the controller for its group (each server is the controller for some groups)
- knowing where the controller is, it connects and issues a RegisterConsumer RPC, then it awaits a RegisterConsumerResponse
- on receiving the RegisterConsumer request the server sends an error code in the HeartbeatResponse to all alive group members and waits for a new RegisterConsumer request from each consumer, except the one that sent the initial RegisterConsumer.
- on receiving an error code in the HeartbeatResponse, all consumers stop fetching, commit offsets, re-discover the controller through list_groups(my_group) and send a RegisterConsumer request to the controller
- on receiving RegisterConsumer from all consumers of the group membership change, the controller sends the RegisterConsumerResponse to all the new group members, with the partitions and the respective offsets to restart consumption from. If there are no previous offsets for the consumer group, -1 is returned. The consumer starts fetching from earliest or latest, depending on consumer configuration
- on receiving the RegisterConsumerResponse the consumer is now able to start consuming its partitions and must now start sending heartbeat messages back to the controller with the current generation id.
When new partitions are added to existing topics or new topics are created -
- on discovering newly created topics or newly added partitions to existing topics, the controller sends an error code in the HeartbeatResponse to all alive group members and waits for a new RegisterConsumer request from each consumer, except the one that sent the initial RegisterConsumer.
- on receiving an error code in the HeartbeatResponse, all consumers stop fetching, commit offsets, re-discover the controller through list_groups(my_group) and send a RegisterConsumer request to the controller
- on receiving RegisterConsumer from all consumers of the group membership change, the controller sends the RegisterConsumerResponse to all the new group members, with the new partitions and the respective offsets to restart consumption from. For newly added partitions and topics, the offset is set to smallest (0L).
- on receiving the RegisterConsumerResponse the consumer is now able to start consuming its partitions and must now start sending heartbeat messages back to the controller with the current generation id.
Offset Rewind
| Code Block |
|---|
while(true) {
List<MessageAndMetadata> messages = consumer.poll(timeout);
process(messages);
if(rewind_required) {
List<PartitionOffset> partitionOffsets = new ArrayList<PartitionOffset>();
partitionOffsets.add(new PartitionOffset(topic, partition, offset));
rewind_offsets(partitionOffsets);
}
}
|
- the consumer stops fetching data, sends a RewindConsumer request to the controller and awaits a RewindConsumerResponse
- on receiving a RewindConsumer request, the controller sends an error code in the HeartbeatResponse to the current owners of the rewound partitionson discovering newly created topics or newly added partitions to existing topics, the controller sends an error code in the HeartbeatResponse to all alive group members and waits for a new RegisterConsumer request from each consumer, except the one that sent the initial RegisterConsumer.
- on receiving an error code in the HeartbeatResponse, all the affected consumers stop fetching, commit offsets , re-discover the controller through list_groups(my_group) and send a the RegisterConsumer request to the controller
- on receiving a RegisterConsumer request from all consumers the affected members of the group membership change, the controller sends records the RegisterConsumerResponse to all the new group members, with the new new offsets for the specified partitions and sends the respective new offsets to restart consumption from. For newly added partitions and topics, the offset is set to smallest (0L).the respective consumers
- on receiving the a RegisterConsumerResponse, the consumer is now able to start consuming its partitions and must now start sending heartbeat messages back to the controller with the current generation id.consumers start fetching data from the specified offsets
Low-level RPC API
TBD we need to design an underlying client network abstraction that can be used to send requests. This should ideally handle metadata and addressing by broker id, multiplex over multiple connections, and support both blocking and non-blocking operations.
...