THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
Contents
| Table of Contents |
|---|
Status
Current state: DraftAccepted
Discussion thread: here
JIRA:
...
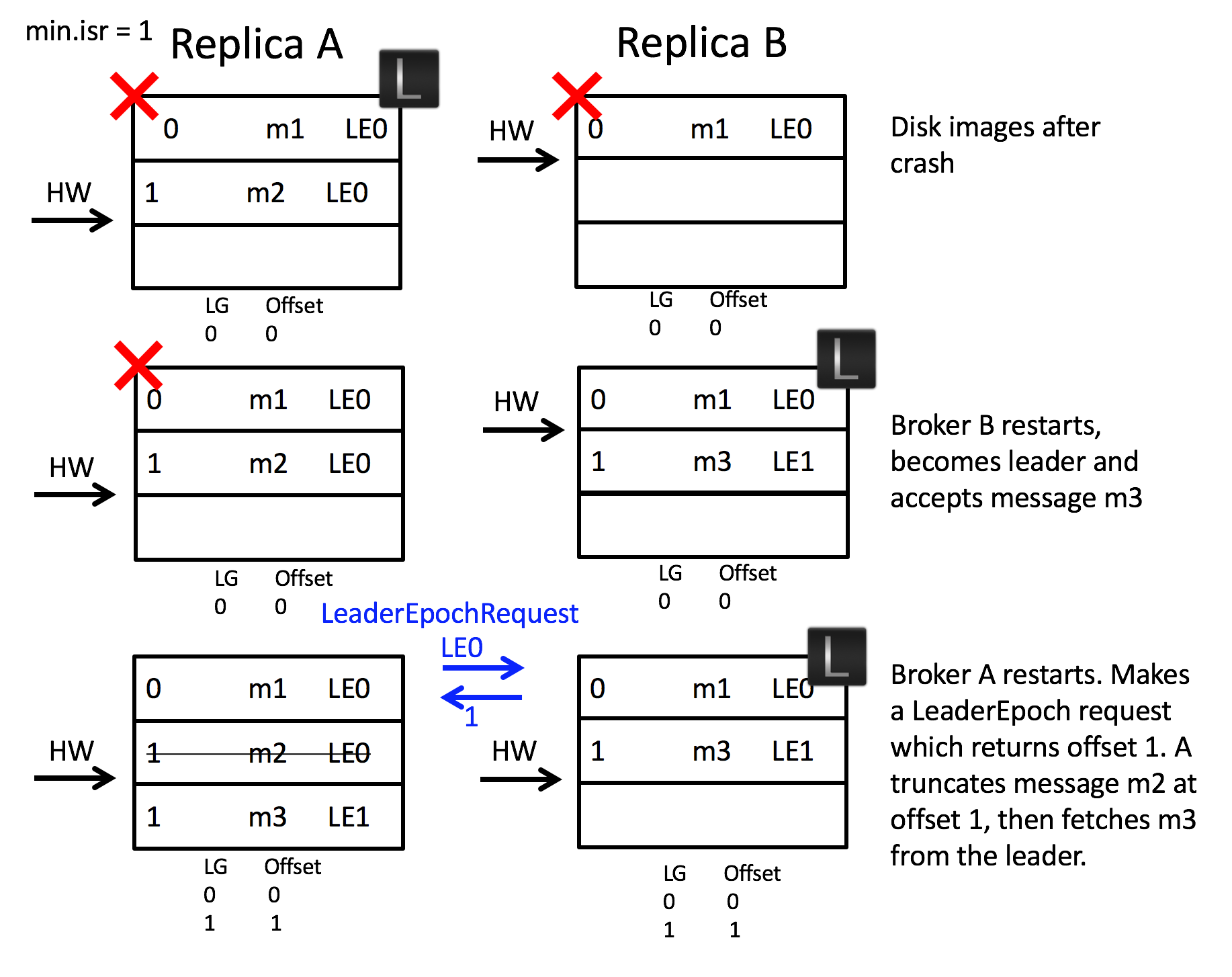
Let’s take an example. Imagine we have two brokers A & B. B is the leader initially as in the below figure. (A) fetches message m2 from the leader (B). So the follower (A) has message m2, but has not yet got confirmation from the leader (AB) that m2 has been committed (the second round of replication, which lets (A) move forward its high watermark past m2, has yet to happen). At this point the follower (A) restarts. It truncates its log to the high watermark and issues a fetch request to the leader (B). (B) then fails and A becomes the new leader. Message m2 has been lost permanently (regardless of whether B comes back or not).
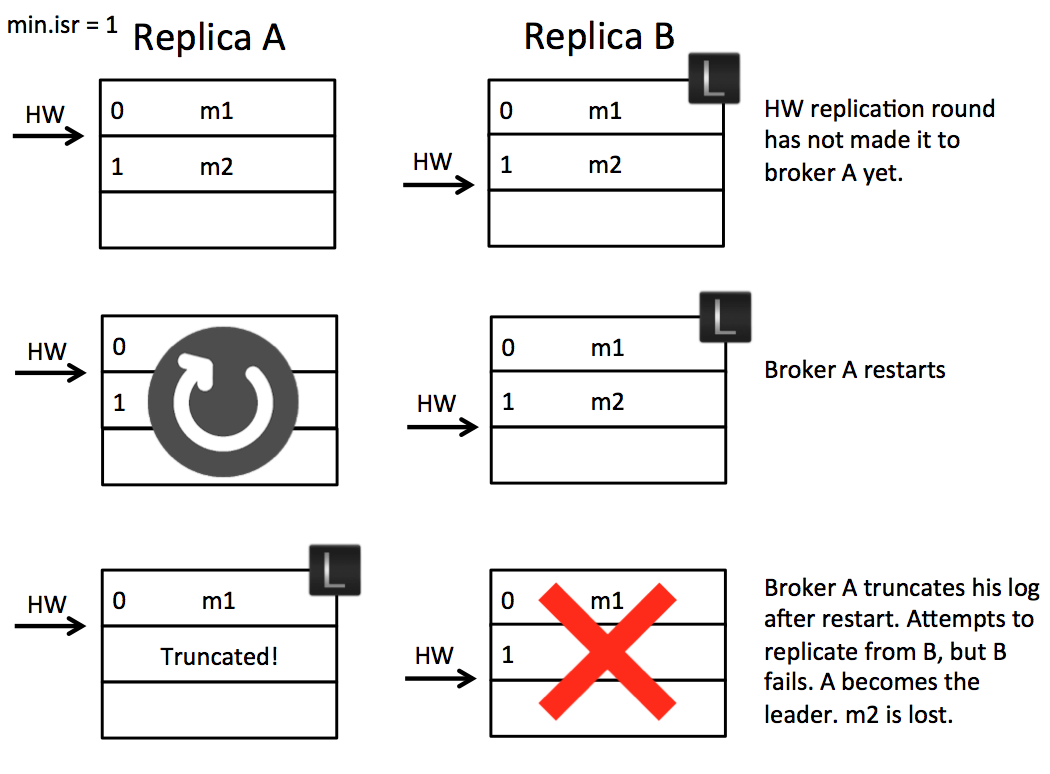

So the essence of this problem is the follower takes an extra round of RPC to update its high watermark. This gap leaves the possibility for a fast leader change to result in data loss as a committed message can be truncated by the follower. There are a couple of simple solutions to this. One is to wait for the followers to move their High Watermark before updating it on the leader. This is not ideal as it adds an extra round of RPC latency to the protocol. Another would be to not truncate on the follower until the fetch request returns from the leader. This should work, but it doesn’t address the second problem discussed below.
...
As we support compressed message sets this can, at worst, lead to an inability for replicas to make progress. This happens when the offset for a compressed message set in one replica points to the midpoint of a compressed message set in another.
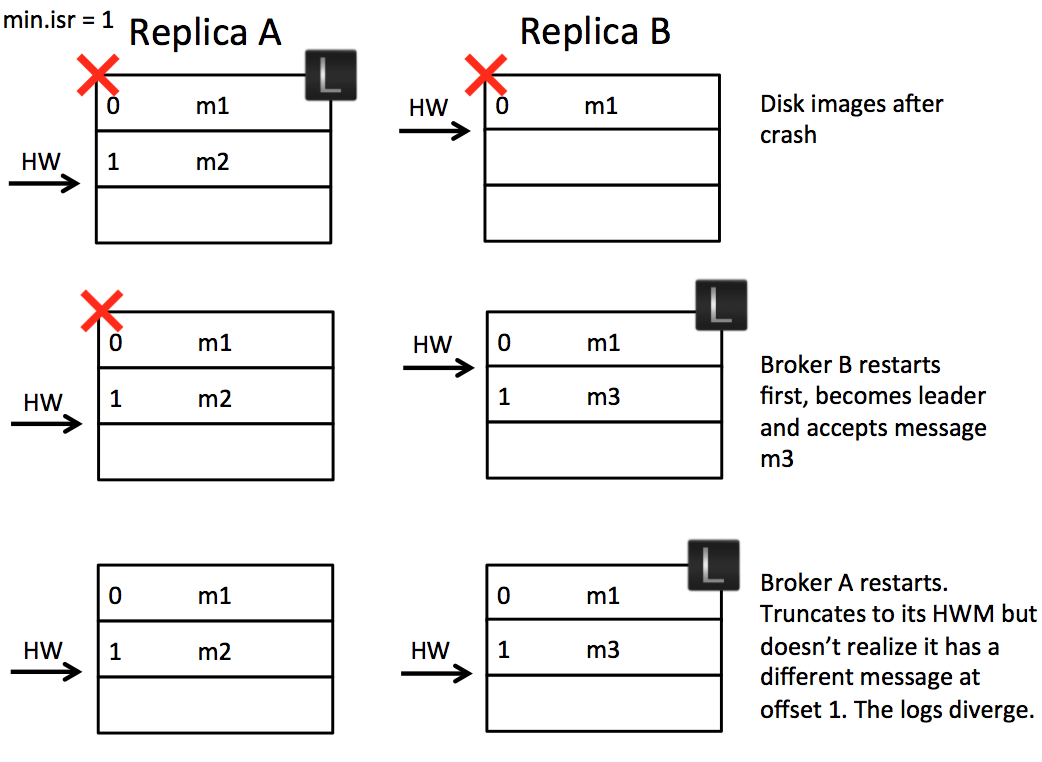

Solution
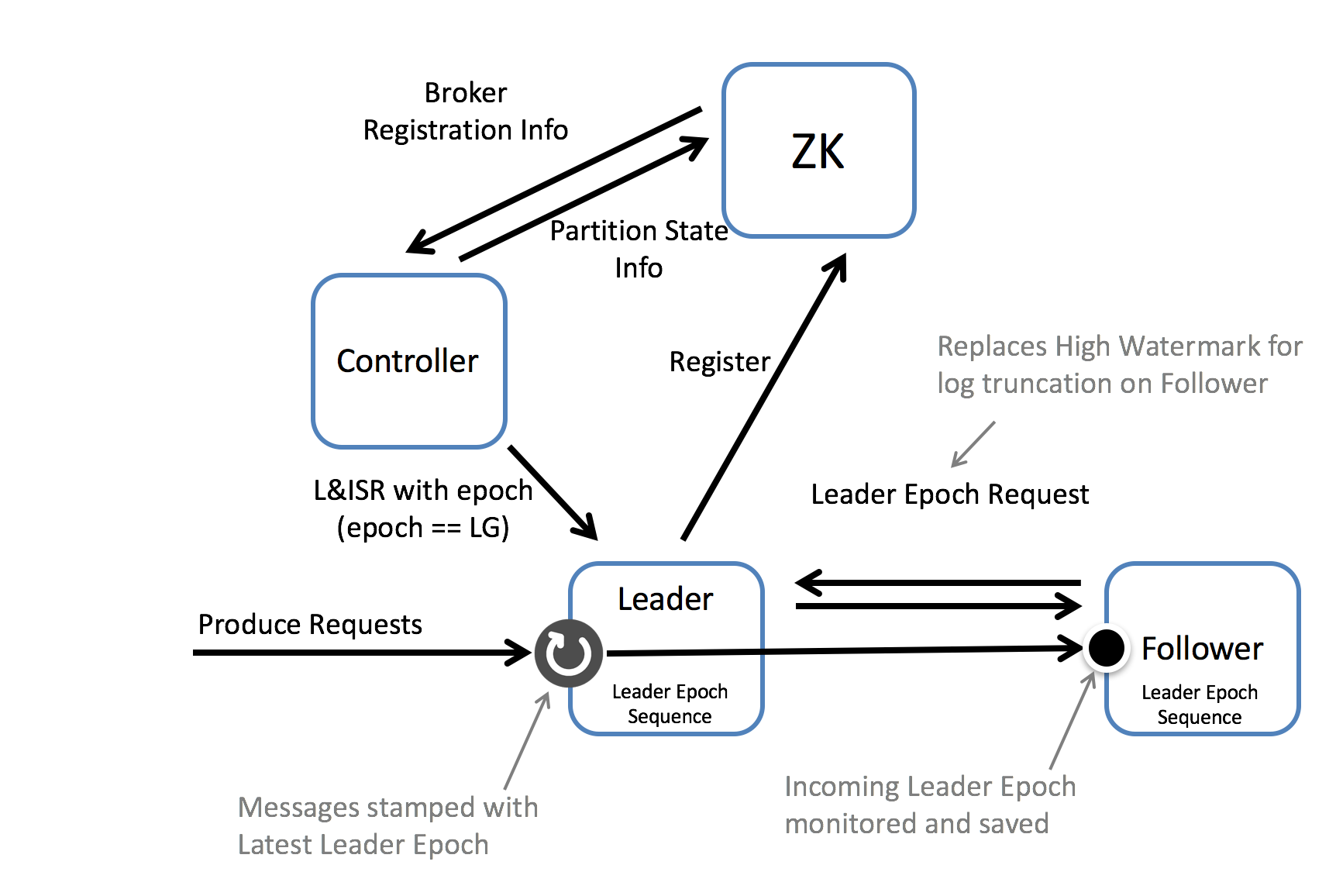
We can solve both of these issues by introducing the concept of a Leader Epoch. This allocates an identifier to a period of leadership, which is then added to each message by the leader. Each replica keeps a vector of [LeaderEpoch => StartOffset] to mark when leaders changed throughout the lineage of its log. This vector then replaces the high watermark when followers need to truncate data (and will be stored in a file for each replica). So instead of a follower truncating to the High Watermark, the follower gets the appropriate LeaderEpoch from the leader’s vector of past LeaderEpochs and uses this to truncate only messages that do not exist in the leader’s log. So the leader effectively tells the follower what offset it needs to truncate to.

We can walk through the implementation of this by addressing scenario 1:
...
In this case the LeaderEpochResponse returns offset 2. Note this is different to the high watermark which, on the follower, is offset 0. Thus the follower does not truncate any messages and hence message m2 is not lost.
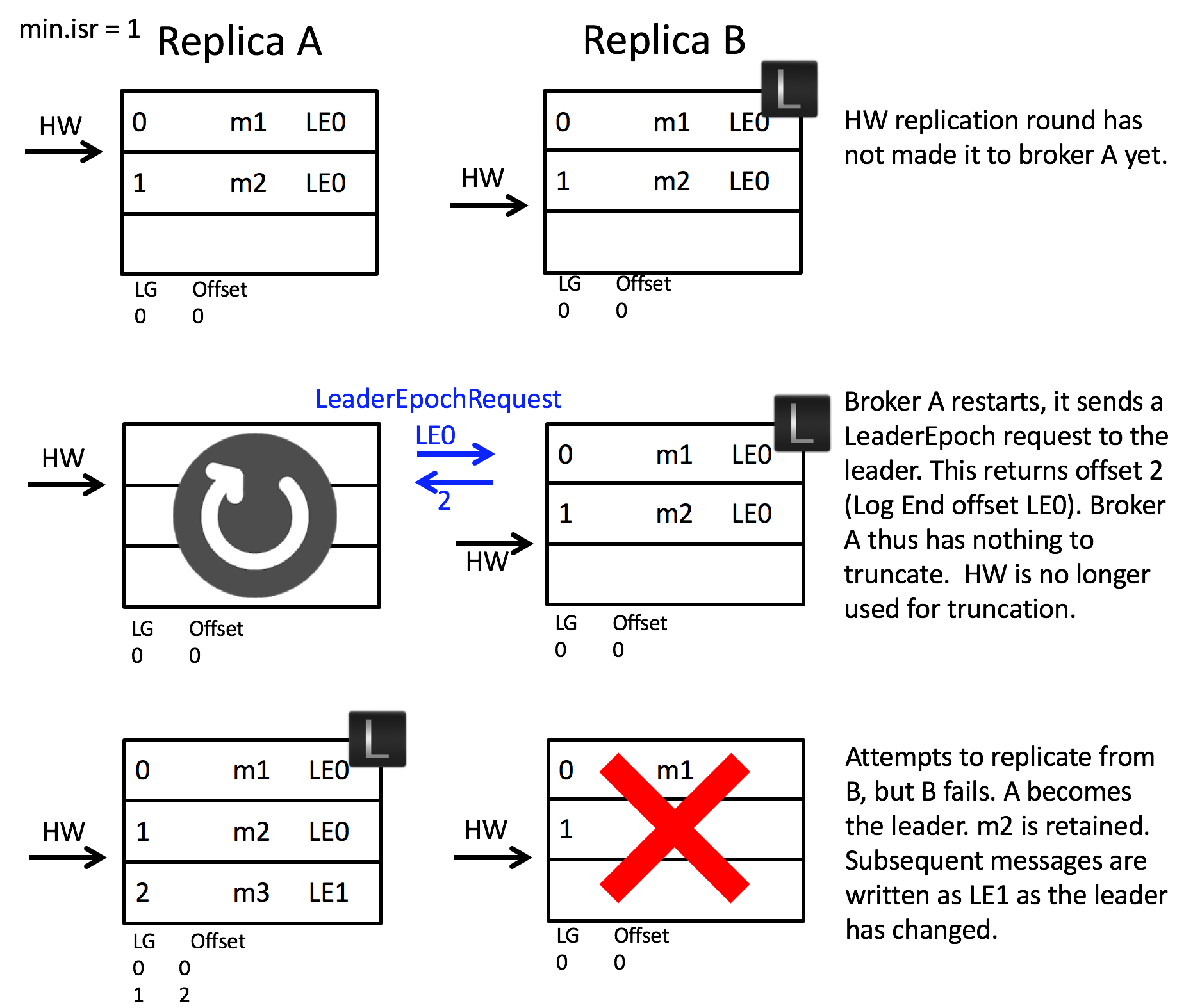

This approach also addresses scenario 2:
When the two brokers restart after a crash, broker B becomes leader. It accepts message m3 but with a new Leader Epoch, LG1LE1. Now when broker A starts, and becomes a follower, it sends a LeaderEpoch request to the leader. This returns the first offset of LG1LE1, which is offset 1. The follower knows that m2 is orphaned and truncates it. It then fetches from offset 1 and the logs are consistent.

NB: It should be noted that this proposal does not protect against log divergence for clusters that use the setting unclean.leader.election.enable=true. (See the appendix for more details.)
Proposed Changes
Leader Epoch
...
To protect against this eventuality, if the controller receives a Broker Registration it will increment the Leader Epoch and propagate that value to the broker via the Leader and ISR Request (in the normal way). This mechanism must will also be sensitive to affected by the bug: KAFKA-1120 which is not addressed directly in the initial version of this KIP. Jira
| server | ASF JIRA |
|---|---|
| serverId | 5aa69414-a9e9-3523-82ec-879b028fb15b |
| key | KAFKA-1120 |
Maintaining the LeaderEpochSequenceFile
Maintaining the LeaderEpochSequenceFile
The The Leader Epoch information will be held in files, per replica, on each broker. The files represent a commit log of LeaderEpoch changes for each replica and are cached in memory on each broker. When segments are deleted, or compacted the appropriate entries are removed from the cache & file. For deleted segments all LeaderEpoch entries for offsets less than equal to the segment log end offset are removed from the LeaderEpochSequenceFile. For compacted topics the process is slightly more involved. The LogCleaner creates a LeaderEpochSequence for every segment it cleans, which represents the earliest offset for each LeaderEpoch. Before the old segment(s) are replaced with the cleaned one(s) the LeaderEpochSequenceFile is regenerated and the cache updated.
...
After an unclean shutdown the Leader Epoch Sequence File could be ahead of the log (as the log is flushed asynchronously by default). Thus, if an unclean shutdown is detected on broker start (regardless of whether it's a leader or follower), all entries are removed from the Leader Epoch Sequence File, where the offset is greater than the log end offset.
Public Interfaces
Add API for
...
OffsetForLeaderEpochRequest/Response
| Offset For Leader Epoch Request V0 |
|---|
|
partition_leader_epoch
|
|
|
| Offset For Leader Epoch Response V0 |
|---|
|
epoch_and_offset
|
|
|
|
|
leader_epoch => INT32
|
|
| Error Codes: |
|---|
|
...
Request Semantics
The offset returned in the response will be the start offset of the first Leader Epoch larger than last_leader_epoch_num or the Log End Offset if the leader's current epoch is equal to the partition_leader_epoch from the request.
The response will only include offsets for partition IDs, supplied in the request, which are leaders on the broker the request was sent to.
...
LeaderEpoch is added to MessageSets used in Fetch Responses returned as part of the internal replication protocol
| MessageSet |
|---|
|
We bump up ProduceRequest/FetchRequest (and responses) versions to indicate the broker that this client supports new message format.
Add Leader Epoch Sequence File per Partition
A file will be used, per replica (located inside the log directory), containing the leader epoch and its corresponding start offset. This will be a text file with the schema:
| leader-epoch-sequence-file |
|---|
|
|
Compatibility, Deprecation, and Migration Plan
...