THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
| Table of Contents |
|---|
Kafka currently provides at-least-once messaging guarantees. Duplicates can arise due to either producer retries or consumer restarts after failure. One way to provide exactly-once messaging semantics is to implement an idempotent producer. This has been covered at length in the proposal for an Idempotent Producer. An alternative and more general approach is to support transactional messaging. This can enable use-cases such as replicated logging for transactional data services in addition to the classic idempotent producer use-cases.
...
(Assuming no failures at each step.)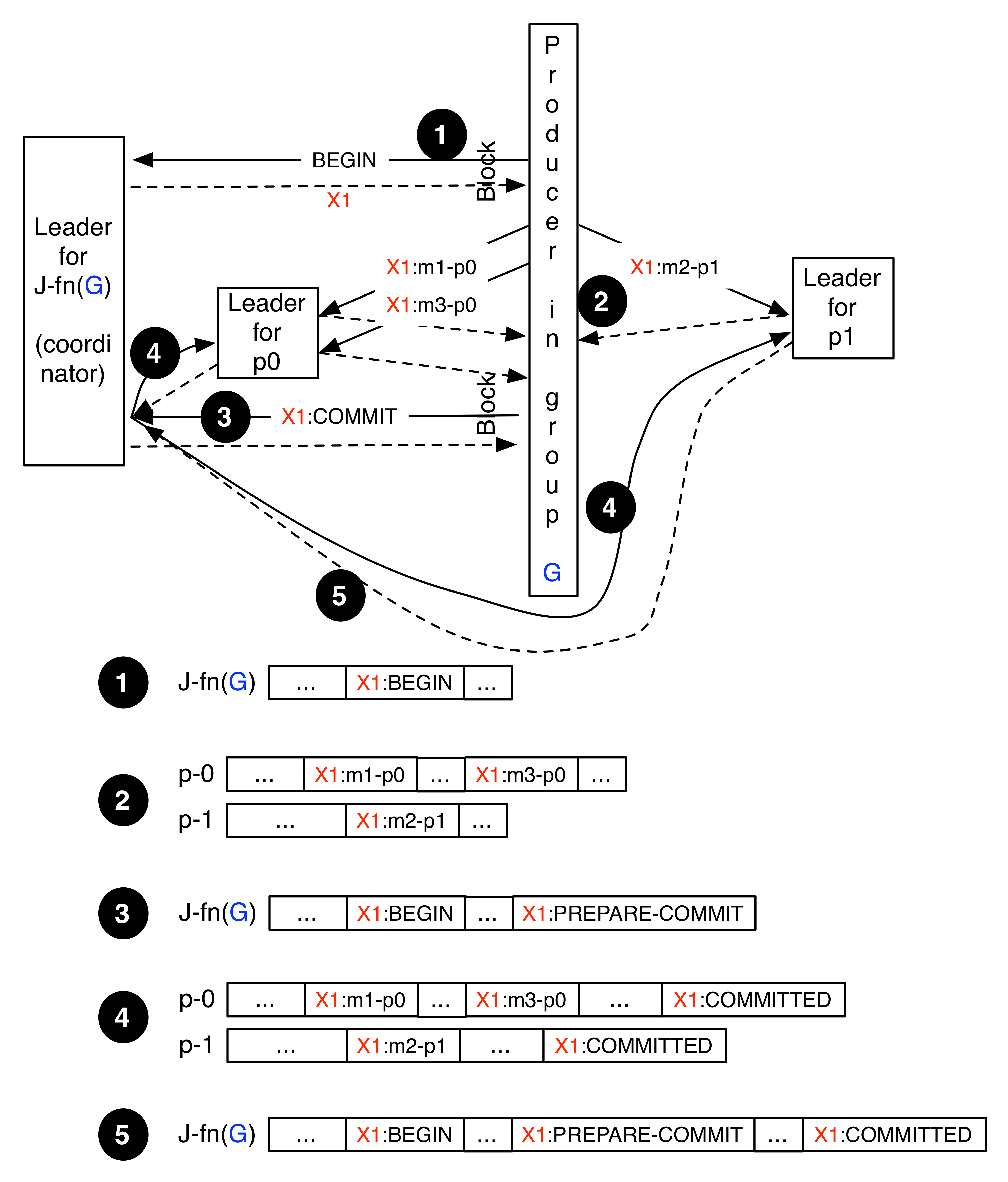
InitPhase
(Step 1 in the figure.)
- Producer: Determine which broker is the coordinator for its group.
- - Producer: Send a BeginTransaction(producerId, generation, partitions... ) request to the coordinator and await response. We could provide a variation of this API that that also includes a time-out. If the producer needs to commit its consumer state as part of the transaction it will need to include the relevant partition of the __consumer_offsets topic in the BeginTransaction request.
- Broker: Generate a TxId.
- Coordinator: Append a BEGIN(TxId, producerId, generation, partitions...) record to the journal log and send response.
- Producer: Read back response (which will include the TxId).
- Coordinator (and followers): Update in-memory state of in-flight transactions and data partitions of the transaction.
SendPhase
(Step 2 in the figure.)
Producer: Send transaction payloads (i.e., records) to the leader brokers of the data partitions. Each record will contain the TxId and TxCtl fields. The TxCtl is really only required to mark the final commit (or abort). The producer request envelope will include the producer ID and generation as well, but these will not be appended to the data logs.
EndPhase (When the producer is ready to commit a transaction,)
(Steps 3, 4, 5 in the figure.)
- Producer: Send an OffsetCommitRequest to commit the input state associated with the end of that transaction (i.e., input for start of next transaction).
- Producer: Send a CommitTransaction(TxId, producerId, generation) request to the coordinator and await response. (A non-error response indicates to the producer that the transaction will be committed.)
- Coordinator: Append the PREPARE_COMMIT(TxId) request to the journal log and then send a response to the producer.
- Coordinator: Send a CommitTransaction(TxId, partitions...) request to every leader broker (for records in the transaction payload).
- Leader brokers:
- If this is a leader for a partition of a topic other than __consumer_offsets: Upon receiving a CommitTransaction(TxId, partition1, partition2, ...) request it will append an empty (null) record (i.e., no key/value) to the respective partition and set the TxId and TxCtl (to COMMITTED) fields of the record. The leader broker will then respond to the coordinator.
- If this is a leader for a partition of __consumer_offsets: append a record to the partition with key set to G-LAST-COMMIT, value set to TxId. It should also set the TxId and TxCtl fields of the record. The broker will then respond to the coordinator.
- Coordinator: Append a COMMITTED(TxId) request to the journal log.
- Coordinator (and followers): Advance HW if possible (see above for details of the HW).
...
- Timeout or error response when producer sends BeginTransaction(TxId): producer simply retries (with same TxId).
- Broker-side error while the producer is sending the data: The producer should abort (and subsequently redo) the transaction (with a new TxId). If the producer does not abort the transaction, the coordinator will abort the transaction after the transaction's timeout period. Redoing the transaction is required only in the case of an error for which the request data may have been appended and replicated to the follower. For example, a producer request timeout would require a redo while a NotLeaderForPartitionException does not require a redo.
- Timeout or error response when producer sends CommitTransaction(TxId): producer simply retries the transaction (with same TxId). (However, see section on idempotence further down.)
- Producer failure while a transaction is pending: if the coordinator is in a position to detect a closed socket (when it sends the response to the BeginTransactionRequest) then it can proactively abort the transaction. Otherwise the transaction will be aborted after its timeout period.
- Coordinator failure: i.e., when the coordinator moves to another broker (i.e., leadership of a journal partition moves). The coordinator will scan the log from the last checkpointed HW. If there are any transactions that were in PREPARE_COMMIT or PREPARE_ABORT, the new coordinator will redo the COMMIT and ABORT. Note that transactions that are in-flight when a coordinator goes down don't necessarily need to be aborted - i.e., the producer can just send its CommitTransactionRequest to the new coordinator.
...
One nuance to this is when a producer is starting up for the first time and obtains its group state which will be empty and therefore sets its generation to zero. If it soft-fails at that point and a fail-over producer repeats the same process, we could end up with two producers with the same ID and generation. I think this can be addressed simply by having the transaction coordinator ensure that for a given producerId-generation combination, there can be only one producer connection. If it detects this condition, it can close both connections and abort any transaction that may have been initiated. (The leader brokers should also keep track of in-flight flight transactions, their associated producerIDs-generations and do the same. Since the abort from the coordinator can arrive before the producer actually stops sending data, the broker needs to reject those producer requests since it does not correspond to any valid pending transaction.)
...
- Consumer configuration will specify whether or not it will consume in READ_COMMITTED or READ_UNCOMMITTED mode.
- READ_UNCOMMITTED: The only change is that the consumer should ignore the transactional control messages.
- - In order to support READ_COMMITTED, the consumer will need to maintain a PendingTransactionMap [TxId-Partition] -> messages. This map buffers messages for each transaction/partition combination. It should ideally have the capability of (seamlessly) spilling to disk if it hits a (configurable) memory limit.-
- The consumer will maintain an internal iterator to iterate over messages as they arrive. It will buffer messages as long as they are part of a pending transaction but but will expose them to the application iterator as soon as it reads a COMMIT for the transaction (or discard them if it reads an ABORT).
- READ_COMMMITTED:
- When the consumer iterator implementation encounters a transactional control message for a partition, it does not return the message to the application. Instead, it begins to buffer those messages in the PendingTransactionMap.
- Offset management: The consumer's offset state for each partition will now be an offset tuple. The first offset is the start offset of the earliest pending transaction in that partition. The second offset is the offset of the internal iterator.
- We may want to maintain one more offset - which is the internal offset of the transaction that we are currently processing. This may be required with long transactions - i.e., a consumer may be in the middle of processing a transaction and fail to call poll in time.)
- Consumer failure
- If a consumer fails it can delete any state that spilt over to disk (if applicable) and start with a new map.
- If the previous check-pointed state was (o1, o2) it will resume fetching from o1 and ignore any committed transactions between o1 and o2.
...
Transaction support should be sufficient to achieve idempotence. However, a producer will need to buffer messages of the transaction until it receives the commit response for that transaction. We can avoid this need to buffer by incorporating sequence numbers in the message header and incorporating pieces of the original idempotent producer proposal. In fact, we would probably want to have some form of the idempotent producer to be available (stand-alone) to avoid aborting long-running transactions that run into (say) a temporary network glitch during the data send phase.