THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
| Table of Contents |
|---|
Goals
The main goal of this project is to have a thin consumer client design that can be easily adopted/reimplemented in non-Java languages. To achieve this we have decided to:
- Move the group member management and offset management from the client side to the server side with a centralized coordination mechanism. By doing so we can completely remove ZK-dependency from the consumer clients. General design proposal can be found here, here and here.
- Make the consumer client single-threaded with non-blocking API. Some discussions about this can be found here.
Besides this main goal we also want to add some new feature supports that we have seen while operating 0.8 and older versions. An in-comprehensive list below:
- Manual partition assignment: instead of going through the centralized coordination process to get assigned consuming partitions, the consumers should be able to simply specify their target partitions and start consume right away without any group membership management.
- Manual offset management: instead of using Kafka commit() call to manage the consumed offsets, consumers should be able to store/load their offsets outside Kafka clients and simply specify the starting offsets when consuming.
- Note that pre-0.9, we support both of these use cases by providing a simple consumer and a zookeeper consumer (i.e. high-level consumer) interface, and users need to choose all-or-none for the functionalities; in 0.9 we will combine these two into one interface with more flexibility.
Consumer API
Here is the proposed consumer API interface:
| Code Block |
|---|
Consumer (Properties) {
// Subscribe to a list of topics, return immediately.
// Throws an exception if the new subscription is not valid with existing subscriptions.
void subscribe(String...) throws SubscriptionNotValidException;
// Subscribe to a specified topic partition, return immediately.
// Throws an exception if the new subscription is not valid with existing subscriptions.
void subscribe(String, Int) throws SubscriptionNotValidException;
// Subscribe to a specified topic partition at the given offset, return immediately.
// Throws an exception if the new subscription is not valid with existing subscriptions.
void subscribe(String, Int, Long) throws SubscriptionNotValidException;
// Try to fetch messages from the topic/partitions it subscribed to.
// Return whatever messages are available to be fetched or empty after specified timeout.
List<Records> poll(Long) throws SubscriptionIsEmptyException, ConsumeInitOffsetNotKnownException;
// Commit latest offsets for all partitions currently consuming from.
// If the sync flag is set to true, commit call will be sync and blocking.
// Otherwise the commit call will be async and best-effort.
void commit(Boolean) throws SubscriptionIsEmptyException;
// Commit the specified offset for the specified topic/partition.
// If the sync flag is set to true, commit call will be sync and blocking.
// Otherwise the commit call will be async and best-effort.
// Throws an exception if the partitions specified are not currently consuming from.
void commit(List[(String, Int, Long)], Boolean) throws InvalidPartitionsToCommitOffsetException;
// Specify the fetch starting offset for the specified topic/partition.
void pos(List[(String, Int, Long)])
// Get the currently consuming partitions.
// Block wait if the current partitions are not known yet.
List[(String, Int)] getPartitions() throws SubscriptionIsEmptyException;
// Get the last committed offsets of the partitions currently consuming.
// Block wait if the current partitions are not known yet.
Map[(String, Int), Long] getOffsets() throws SubscriptionIsEmptyException;
// Get the last committed offsets of the specified topic/partition.
Long getOffset(String, Int) throws SubscriptionIsEmptyException, InvalidPartitionsToGetOffsetException;
// --------- Call-back Below, not part of API ------------ //
// Call-back function upon partition de-assignment.
// Default implementation will commit offset depending on auto.commit config.
void onPartitionDeassigned(List[(String, Int)]);
// Call-back function upon partition re-assignment.
// Default implementation is No-Op.
void onPartitionAssigned(List[(String, Int)])
// --------- Optional Call-back Below ------------ //
// Call-back function upon partition reassignment given the group member list and the subscribed topic partition info.
// Return the partitions that would like to consume, and need to make sure each partition is covered by just one member in the group.
List[(String, Int)] partitionsToConsume(List[String], List[TopicPartition]);
} |
The poll() function call returns MessageAndMetadata not just MessageAndOffset because of G6.b. This would also help removing the decompression/recompression in mirror maker (details can be found in KAFKA-1011).
Consumer Coordinator Overview
Each broker will have a consumer coordinator responsible for group management of one or more consumer groups, including membership management and offset management. Management of consumer groups will be distributed across all brokers' coordinators.
For each consumer group, the coordinator stores the following information:
- Consumer groups it currently serve, containing
- The consumer list along with their subscribed topic/partition.
- Partition ownership for each consumer within the group.
- List of subscribed groups for each topic.
- List of groups subscribed to wildcards.
- Latest offsets for each consumed topic/partition.
The coordinator also have the following functionalities:
- handleNewConsumerGroup: this is called when the coordinator starts to serve a new consumer group.
- handleAddedConsumer: this is called when a new consumer is registered into a existing consumer group.
- handleConsumerFailure: this is called when the coordinator thinks a consumer has failed and hence kick it out of the group.
- handleTopicChange: this is called when the coordinator detects a topic change from ZK.
- handleTopicPartitionChange: this is called when the coordinator detects a topic partition change from ZK.
- handleCommitOffset: this this called for committing offset for certain partitions.
- handleConsumerGroupRebalance: this is called when the partition ownership needs to be re-assigned within a group.
The coordinator also maintain the following information in ZK:
- Partition ownership of the subscribed topic/partition. This can now be written in a single path with a Json string instead of into multiple paths, one for each partition.
- [Optional] Coordinators for each consumer groups.
The coordinator also holds the following modules:
- A threadpool of rebalancer threads executing rebalance process of single consumer groups.
- [Optional] A socket server for both receiving and send requests and sending responses.
- [Optional] A delayed scheduler along with a request purgatory for sending heartbeat requests.
- [Optional] A ZK based elector for assigning consumer groups to coordinators.
Design Proposal
For consumer implementation, we have two main proposals: single-threaded consumer of multi-threaded consumer.
Single-threaded Consumer
API Implementation
| Code Block |
|---|
subscribe:
1. Check if the new subscription is valid with the old subscription:
1.1. If yes change the subscription and return.
1.2. Otherwise throw SubscriptionNotValidException. |
| Code Block |
|---|
poll:
1. Check if the subscription list is empty, if yes throw SubscriptionIsEmptyException
2. Check if the subscription list has changed and is topic-based:
2.1. If not, check if the subscription is topic-based:
2.1.1. If not, call fetch() // no need to talk to coordinator
2.1.2. If yes, call coordinate() and call fetch() // may need to heartbeat coordinator
2.2. If yes, call coordinate() and call fetch() |
| Code Block |
|---|
commit:
1. Call coordinate().
2. Send commit offset to coordinator, based on sync param block wait on response or not. |
| Code Block |
|---|
getPartition:
1. Check if the subscription list is empty, if yes throw SubscriptionIsEmptyException
2. If the partition info is not known, call coordinate()
3. Return partitions info.
getOffset(s):
1. Check if the subscription list is empty, if yes throw SubscriptionIsEmptyException
2. If the partition info is not known, call coordinate()
3. If the offset info is not known, based on kafka.offset.manage send getOffset to coordinator or throw InvalidPartitionsToGetOffsetException |
| Code Block |
|---|
fetch:
1. If the partition metadata is not know, send metadata request and block wait on response and setup channels to partition leaders.
2. Immediate-select readable channels if there is any, return data.
3. If there is no readable channels, check if the offset is known.
3.1. If not throw ConsumeInitOffsetNotKnownException.
3.2. Otherwise send the fetch request to leader and timeout-select. |
| Code Block |
|---|
coordinate:
1. Check if the coordinator channel has been setup and not closed, and if subscription list has not changed. If not:
1.1. Block wait on getting the coordinator metadata.
1.2. call onPartitionDeassignment().
1.3. Send the registerConsumer to coordinator, set up the channel and block wait on registry response.
1.3.a.1 The registerConsumer response contain member info and partition info, call partitionsToConsume to get the owned partitions.
1.3.a.2 Send the partitions to consume info and get confirmed from the coordinator. // two round trips
1.3.b. The registerConsumer response contain partition assignment from the coordinator. // one round trip
1.4. and call onPartitionAssigned().
2. If yes, check if heartbeat period has reached, if yes, send a ping to coordinator. |
...
WARN: This is an obsolete design. The design that's implemented in Kafka 0.9.0 is described in this wiki.
Motivation
The motivation for moving to a new set of consumer client APIs with broker side co-ordination is laid out here.
Consumer API
The proposed consumer APIs are here. Several API usage examples are documented here.
Consumer HowTo
This wiki has design details on the new consumer. This level of detail may be too verbose for people who are just trying to write a non-java consumer client using the new protocol. This wiki provides a step by step guide for writing a non-java 0.9 client.
Group management protocol
Rebalancing is the process where a group of consumer instances (belonging to the same group) co-ordinate to own a mutually exclusive set of partitions of topics that the group is subscribed to. At the end of a successful rebalance operation for a consumer group, every partition for all subscribed topics will be owned by a single consumer instance within the group. The way rebalancing works is as follows. Every broker is elected as the coordinator for a subset of the consumer groups. The co-ordinator broker for a group is responsible for orchestrating a rebalance operation on consumer group membership changes or partition changes for the subscribed topics. It is also responsible for communicating the resulting partition ownership configuration to all consumers of the group undergoing a rebalance operation.
Consumer
- On startup or on co-ordinator failover, the consumer sends a ConsumerMetadataRequest to any of the brokers in the bootstrap.brokers list. In the ConsumerMetadataResponse, it receives the location of the co-ordinator for it's group.
- The consumer connects to the co-ordinator and sends a HeartbeatRequest. If an IllegalGeneration error code is returned in the HeartbeatResponse, it indicates that the co-ordinator has initiated a rebalance. The consumer then stops fetching data, commits offsets and sends a JoinGroupRequest to it's co-ordinator broker. In the JoinGroupResponse, it receives the list of topic partitions that it should own and the new generation id for it's group. At this time, group management is done and the consumer starts fetching data and (optionally) committing offsets for the list of partitions it owns.
- If no error is returned in the HeartbeatResponse, the consumer continues fetching data, for the list of partitions it last owned, without interruption.
Co-ordinator
- In steady state, the co-ordinator tracks the health of each consumer in every group through it's failure detection protocol.
- Upon election or startup, the co-ordinator reads the list of groups it manages and their membership information from zookeeper. If there is no previous group membership information, it does nothing until the first consumer in some group registers with it.
- Until the co-ordinator finishes loading the group membership information for all groups that it is responsible for, it returns the CoordinatorStartupNotComplete error code in the responses of HearbeatRequests, OffsetCommitRequests and JoinGroupRequests. The consumer then retries the request after some backoff.
- Upon election or startup, the co-ordinator also starts failure detection for all consumers in a group. Consumers that are marked dead by the co-ordinator's failure detection protocol are removed from the group and the co-ordinator triggers a rebalance operation for the consumer's group.
- Rebalance is triggered by returning the IllegalGeneration error code in the HeartbeatResponse. Once all alive consumers re-register with the co-ordinator via JoinGroupRequests, it communicates the new partition ownership to each of the consumers in the JoinGroupResponse, thereby completing the rebalance operation.
- The co-ordinator tracks the changes to topic partition changes for all topics that any consumer group has registered interest for. If it detects a new partition for any topic, it triggers a rebalance operation (as described in #5 above). It is currently not possible to reduce the number of partitions for a topic. The creation of new topics can also trigger a rebalance operation as consumers can register for topics before they are created.
Failure detection protocol
The consumer specifies a session timeout in the JoinGroupRequest that it sends to the co-ordinator in order to join a consumer group. When the consumer has successfully joined a group, the failure detection process starts on the consumer as well as the co-ordinator. The consumer initiates periodic heartbeats (HeartbeatRequest), every session.timeout.ms/heartbeat.frequency to the co-ordinator and waits for a response. If the co-ordinator does not receive a HeartbeatRequest from a consumer for session.timeout.ms, it marks the consumer dead. Similarly, if the consumer does not receive the HeartbeatResponse within session.timeout.ms, it assumes the co-ordinator is dead and starts the co-ordinator rediscovery process. The heartbeat.frequency is a consumer side config that determins the interval at which the consumer sends a heartbeat to the co-ordinator. The heartbeat.frequency puts a lower bound on the rebalance latency since the co-ordinator notifies a consumer regarding a rebalance operation through the heartbeat response. So, it is important to set it to a reasonably high value especially if the session.timeout.ms is relatively large. At the same time, care should be taken to not set the heartbeat.frequency too high since that would cause overhead due to request overload on the brokers. Here is the protocol in more detail -
- After receiving a ConsumerMetadataResponse or a JoinGroupResponse, a consumer periodically sends a HeartbeatRequest to the coordinator every session.timeout.ms/heartbeat.frequency milliseconds.
- Upon receiving the HeartbeatRequest, coordinator checks the generation number, the consumer id and the consumer group. If the consumer specifies an invalid or stale generation id, it send an IllegalGeneration error code in the HeartbeatResponse.
- If the coordinator does not receive a HeartbeatRequest from a consumer at least once in session.timeout.ms, it marks the consumer dead and triggers a rebalance process for the group.
- If the consumer does not receive a HeartbeatResponse from the coordinator after session.timeout.ms or finds the socket channel to the coordinator to be closed, it treats the coordinator as failed and triggers the co-ordinator re-discovery process.
Note that on coordinator failover, the consumers may discover the new coordinator before or after the new coordinator has finished the failover process including loading the consumer group metadata from ZK, etc. In the latter case, the new coordinator will just accept its heartbeat request as normal; in the former case, the new coordinator may reject its request, causing it to re-dicover the co-ordinator and re-connect again, which is fine. Also, if the consumer connects to the new coordinator too late, the co-ordinator may have marked the consumer dead and will be treat the consumer like a new consumer and trigger a rebalance.
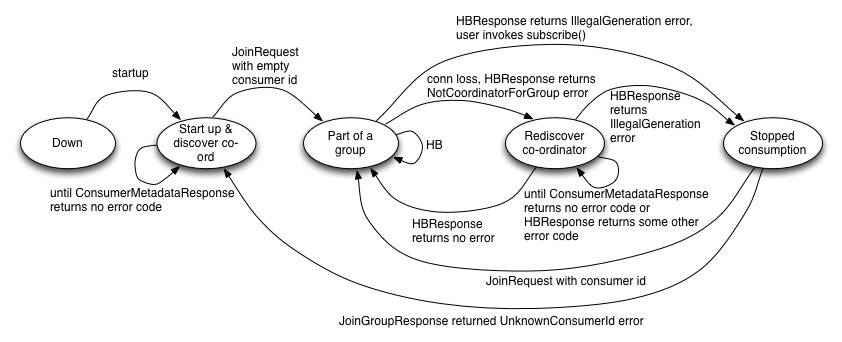
State diagram
Consumer
Here is a description of the states -
Down - The consumer process is down
Startup up & discover co-ordinator - In this state, the consumer discovers the co-ordinator for it's group. The consumer sends a JoinGroupRequest (with no consumer id) once it discovers the co-ordinator. The JoinGroupRequest can receive InconsistentPartitioningStrategy error code if some consumers in the same group specify conflicting partition assignment strategies. It can receive an UnknownPartitioningStrategy error code if the friendly name of the strategy in the JoinGroupRequest is unknown to the brokers. In this case, the consumer is unable to join a group.
Part of a group - In this state, the consumer is part of a group if it receives a JoinGroupResponse with no error code, a consumer id and the generation id for it's group. In this state, the consumer sends a HeartbeatRequest. Depending on the error code received, it either stays in this state or moves to Stopped Consumption or Rediscover co-ordinator.
Re-discover co-ord - In this state, the consumer does not stop consumption but tries to re-discover the co-ordinator by sending a ConsumerMetadataRequest and waiting for a response as long as it gets one with no error code.
Stopped consumption - In this state, the consumer stops consumption and commits offsets, until it joins the group again
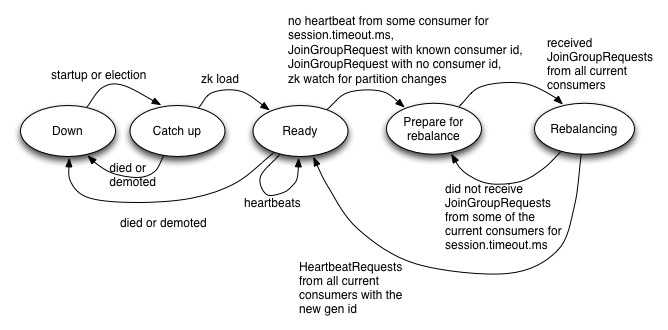
Co-ordinator
Following is a state diagram that describes the state changes on the co-ordinator for a particular group.
Here is a description of the states -
Down - The co-ordinator is dead or demoted
Catch up - In this state, the co-ordinator is elected but not ready to serve requests
Ready - In this state, the newly elected co-ordinator has finished loading the group metadata for all groups that it is responsible for
Prepare for rebalance - In this state, the co-ordinator sends the IllegalGeneration error in the HeartbeatResponse for all consumers in the group and waits for the consumers to send it a JoinGroupRequest
Rebalancing - In this state, the co-ordinator has received a JoinGroupRequest from the consumers in the current generation and it increments the group generation id, assigns consumer ids where required and does the partition assignment
Steady - In the steady state, the co-ordinator accepts OffsetCommitRequests and heartbeats from all consumers in every group
Consumer id assignment
- After startup, a consumer learns it's consumer id in the very first JoinGroupResponse it receives from the co-ordinator. From that point onwards, the consumer must include this consumer id in every HeartbeatRequest and OffsetCommitRequest it sends to the co-ordinator. If the co-ordinator receives a HeartbeatRequest or an OffsetCommitRequest with a consumer id that is different from the ones in the group, it sends an UnknownConsumer error code in the corresponding responses.
- The co-ordinator assigns a consumer id to a consumer on a successful rebalance and sends it in the JoinGroupResponse. The consumer can choose to include this id in every subsequent JoinGroupRequest as well until it is shutdown or dies. The advantage of including the consumer id in subsequent JoinGroupRequests is a lower latency on rebalance operations. When a rebalance is triggered, the co-ordinator waits for all consumers in the previous generation to send it a JoinGroupRequest. The way it identifies a consumer is by it's consumer id. If the consumer chooses to send JoinGroupRequest with empty consumer id, the co-ordinator waits a full session.timeout.ms before it proceeds with the rest of the rebalance operation. It does this since there is no way to map the incoming JoinGroupRequest with a consumer in the absence of a consumer id. This puts a lower bound on the rebalance latency (session.timeout.ms). On the other hand, if the consumer sends it's consumer id on subsequent JoinGroupRequests, the co-ordinator can immediately identify the consumers and proceed with a rebalance once all the known consumers have sent a JoinGroupRequest.
- The co-ordinator does consumer id assignment after it has received a JoinGroupRequest from all existing consumers in a group. At this point, it assigns a new id <group>-<uuid> to every consumer that did not have a consumer id in the JoinGroupRequest. The assumption is that such consumers are either newly started up or choose to not send the previously assigned consumer id.
- If a consumer id is specified in the JoinGroupRequest but it does not match the ids in the current group membership, the co-ordinator sends an UnknownConsumer error code in the JoinGroupResponse and prevents the consumer from joining the group. This does not cause a rebalance operation for the rest of the consumers in the group, but also does not allow such a consumer to join an existing group.
Memory management
TBD
Request formats
For each consumer group, the coordinator stores the following information:
1) For each consumer group, the group metadata containing:
- List of topics the group subscribes to
- Group configs, including session timeout, etc.
- Consumer metadata for each consumer in the group. Consumer metadata includes hostname and consumer id.
- Current offsets for each consumed topic/partition.
- Partition ownership metadata, including the consumer-assigned-partitions map.
2) For each existing topic, a list of consumer groups that are currently subscribing to it.
It is assumed that all the following requests and responses have the common header. So the fields mentioned exclude the ones in the header.
ConsumerMetadataRequest
| Code Block |
|---|
{
GroupId => String
}
|
ConsumerMetadataResponse
| Code Block |
|---|
{
ErrorCode => int16
Coordinator => Broker
} |
JoinGroupRequest
| Code Block |
|---|
{
GroupId => String
SessionTimeout => int32
Topics => [String]
ConsumerId => String
PartitionAssignmentStrategy => String
} |
JoinGroupResponse
| Code Block |
|---|
{
ErrorCode => int16
GroupGenerationId => int32
ConsumerId => String
PartitionsToOwn => [TopicName [Partition]]
}
TopicName => String
Partition => int32 |
HeartbeatRequest
| Code Block |
|---|
{
GroupId => String
GroupGenerationId => int32
ConsumerId => String
} |
HeartbeatResponse
| Code Block |
|---|
{
ErrorCode => int16
} |
OffsetCommitRequest (v1)
| Code Block |
|---|
OffsetCommitRequest => ConsumerGroup GroupGenerationId ConsumerId [TopicName [Partition Offset TimeStamp Metadata]]
ConsumerGroup => string
GroupGenerationId => int32
ConsumerId => String
TopicName => string
Partition => int32
Offset => int64
TimeStamp => int64
Metadata => string |
Configs
Server side configs
This list is still in progress
max.session.timeout - The session timeout for any group should not be higher than this value to reduce overhead on the brokers. If it does, the broker sends a SessionTimeoutTooHigh error code in the JoinGroupResponse
partition.assignment.strategies - Comma separated list of properties that map the strategy's friendly name to the class that implements the strategy. This is used for any strategy implemented by the user and released to the Kafka cluster. By default, Kafka will include a set of strategies that can be used by the consumer. The consumer specifies a partitioning strategy in the JoinGroupRequest. It must use the friendly name of the strategy or it will receive an UnknownPartitionAssignmentStrategyException
Client side configs
The client side configs can be found here
Wildcard Subscription
With wildcard subscription (for example, whitelist and blacklist), the consumers are responsible to discover matching topics through topic metadata request. That is, its topic metadata request will contain an empty topic list, whose response then will return the partition info of all topics, it will then filter the topics that match its wildcard expression, and then update the subscription list using the subscribe() API. Again, if the subscription list has changed from the previous value, it will trigger rebalance for the consumer group by sending the JoinGroupRequest during the next poll().
Interesting scenarios to consider
Co-ordinator failover or connection loss to the co-ordinator
- On co-ordinator failover, the controller elects a new leader for a subset of the consumer groups affected due to the co-ordinator failure. As part of becoming the leader for a subset of the offset topic partitions, the co-ordinator reads metadata for each group that it is responsible for, from zookeeper. The metadata includes the group's consumer ids, the generation id and the subscribed list of topics. Until the co-ordinator has read all metadata from zookeeper, it returns the CoordinatorStartupNotComplete error code in HeartbeatResponse. It is illegal for a consumer to send a JoinGroupRequest during this time, so the error code returned to such a consumer is different (probably IllegalProtocolState).
- If a consumer sends a ConsumerMetadataRequest to a broker before the broker has received the updated group metadata through the UpdateMetadataRequest from the controlller, the ConsumerMetadataResponse will return stale information about the co-ordinator. The consumer will receive NotCoordinatorForGroup error code on the heartbeat/commit offset responses. On receiving the NotCoordinatorForGroup error code, the consumer backs off and resends the ConsumerMetadataRequest.
- The consumer does not stop fetching data during the co-ordinator failover and re-discovery process.
Partition changes for subscribed topics
- The co-ordinator for a group detects changes to the number of partitions for the subscribed list of topics.
- The co-ordinator then marks the group ready for rebalance and sends the IllegalGeneration error code in the HeartbeatResponse. The consumer then stops fetching data, commits offsets and sends a JoinGroupRequest to the co-ordinator.
- The co-ordinator waits for all consumers to send it the JoinGroupRequest for the group. Once it receives all expected JoinGroupRequests, it increments the group's generation id in zookeeper, computes the new partition assignment and returns the updated assignment and the new generation id in the JoinGroupResponse. Note that the generation id is incremented even if the group membership does not change.
- On receiving the JoinGroupResponse, the consumer stores the new generation id and consumer id locally and starts fetching data for the returned set of partitions. The subsequent requests sent by the consumer to the co-ordinator will use the new generation id and consumer id returned by the last JoinGroupResponse.
Offset commits during rebalance
- If a consumer receives an IllegalGeneration error code, it stops fetching and commits existing offsets before sending a JoinGroupRequest to the co-ordinator.
- The co-ordinator checks the generation id in the OffsetCommitRequest and rejects it if the generation id in the request is higher than the generation id on the co-ordinator. This indicates a bug in the consumer code.
- The co-ordinator does not allow offset commit requests with generation ids older than the current group generation id in zookeeper either. This constraint is not a problem during a rebalance since until all consumers have sent a JoinGroupRequest, the co-ordinator does not increment the group's generation id. And from that point until the point the co-ordinator sends a JoinGroupResponse, it does not expect to receive any OffsetCommitRequests from any of the consumers in the group in the current generation. So the generation id on every OffsetCommitRequest sent by the consumer should always match the current generation id on the co-ordinator.
- Another case worth discussing is when a consumer goes through a soft failure e.g. a long GC pause during a rebalance. If a consumer pauses for more than session.timeout.ms, the co-ordinator will not receive a JoinGroupRequest from such a consumer within session.timeout.ms. The co-ordinator marks the consumer dead and completes the rebalance operation by including the consumers that sent the JoinGroupRequest in the new generation.
Heartbeats during rebalance
- Consumer periodically sends a HeartbeatRequest to the coordinator every session.timeout.ms/hearbeat.frequency milliseconds. If the consumer receives the IllegalGeneration error code in the HeartbeatResponse, it stops fetching, commits offsets and sends a JoinGroupRequest to the co-ordinator. Until the consumer receives a JoinGroupResponse, it does not send any more HearbeatRequests to the co-ordinator.
- A higher heartbeat.frequency ensures lower latency on a rebalance operation since the co-ordinator notifies a consumer of the need to rebalance only on a HeartbeatResponse.
- The co-ordinator pauses failure detection for a consumer that has sent a JoinGroupRequest until a JoinGroupResponse is sent out. It restarts the hearbeat timer once the JoinGroupResponse is sent out and marks a consumer dead if it does not receive a HeartbeatRequest from that time for another session.timeout.ms milliseconds. The reason the co-ordinator stops depending on heartbeats to detect failures during a rebalance is due to a design decision on the broker's socket server - Kafka only allows the broker to read and process one outstanding request per client. This is done to make it simpler to reason about ordering. This prevents the consumer and broker from processing a heartbeat request at the same time as a join group request for the same client. Marking failures based on JoinGroupRequest prevents the co-ordinator from marking a consumer dead during a rebalance operation. Note that this does not prevent the rebalance operation from finishing if a consumer goes through a soft failure during a rebalance operation. If the consumer pauses before it sends a JoinGroupRequest, the co-ordinator will mark it dead during the rebalance and complete the rebalance operation by including the rest of the consumers in the new generation. If a consumer pauses after it sends a JoinGroupRequest, the co-ordinator will send it the JoinGroupResponse assuming the rebalance completed successfully and will restart it's heartbeat timer. If the consumer resumes before session.timeout.ms, consumption starts normally. If the consumer pauses for session.timeout.ms after that, then it is marked dead by the co-ordinator and it will trigger a rebalance operation.
- The co-ordinator returns the new generation id and consumer id only in the JoinGroupResponse. Once the consumer receives a JoinGroupResponse, it sends the next HeartbeatRequest with the new generation id and consumer id.
Co-ordinator failure during rebalance
A rebalance operation goes through several phases -
- Co-ordinator receives notification of a rebalance - either a zookeeper watch fires for a topic/partition change or a new consumer registers or an existing consumer dies.
- Co-ordinator initiates a rebalance operation by sending an IllegalGeneration error code in the HeartbeatResponse
- Consumers send a JoinGroupRequest
- Co-ordinator increments the group's generation id in zookeeper and writes the new partition ownership in zookeeper
- Co-ordinator sends a JoinGroupResponse
Co-ordinator can fail at any of the above phases during a rebalance operation. This section discusses how the failover handles each of these scenarios.
- If the co-ordinator fails at step #1 after receiving a notification but not getting a chance to act on it, the new co-ordinator has to be able to detect the need for a rebalance operation on completing the failover. As part of failover, the co-ordinator reads a group's metadata from zookeeper, including the list of topics the group has subscribed to and the previous partition ownership decision. If the # of topics or # of partitions for the subscribed topics are different from the ones in the previous partition ownership decision, the new co-ordinator detects the need for a rebalance and initiates one for the group. Similarly if the consumers that connect to the new co-ordinator are different from the ones in the group's generation metadata in zookeeper, it initiates a rebalance for the group.
- If the co-ordinator fails at step #2, it might send a HeartbeatResponse with the error code to some consumers but not all. Similar to failure #1 above, the co-ordinator will detect the need for rebalance after failover and initiate a rebalance again. If a rebalance was initiated due to a consumer failure and the consumer recovers before the co-ordinator failover completes, the co-ordinator will not initiate a rebalance. However, if any consumer (with an empty or unknown consumer id) sends it a JoinGroupRequest, it will initiate a rebalance for the entire group.
- If a co-ordinator fails at step #3, it might receive JoinGroupRequests from only a subset of consumers in the group. After failover, the co-ordinator might receive a HeartbeatRequest from all alive consumers OR JoinGroupRequests from some. Similar to #1, it will trigger a rebalance for the group.
- If a co-ordinator fails at step #4, it might fail after writing the new generation id and group membership in zookeeper. The generation id and membership information is written in one atomic zookeeper write operation. After failover, the consumer will send HeartbeatRequests to the new co-ordinator with an older generation id. The co-ordinator triggers a rebalance by returning an IllegalGeneration error code in the response that causes the consumer to send it a JoinGroupRequest. Note that this is the reason why it is worth sending both the generation id as well as the consumer id in the HeartbeatRequest and OffsetCommitRequest
- If a co-ordinator fails at step #5, it might send the JoinGroupResponse to only a subset of the consumers in a group. A consumer that received a JoinGroupResponse will detect the failed co-ordinator while sending a heartbeat or committing offsets. At this point, it will discover the new co-ordinator and send it a heartbeat with the new generation id. The co-ordinator will send it a HeartbeatResponse with no error code at this point. A consumer that did not receive a JoinGroupResponse will discover the new co-ordinator and send it a JoinGroupRequest. This will cause the co-ordinator to trigger a rebalance for the group.
Slow consumers
Slow consumers can be removed from the group by the co-ordinator if it does not receive a heartbeat request for session.timeout.ms. Typically, consumers can be slow if their message processing is slower than session.timeout.ms, causing the interval between poll() invocations to be longer than session.timeout.ms. Since a heartbeat is only sent during the poll() invocation, this can cause the co-ordinator to mark a slow consumer dead. Here is how the co-ordinator handles a slow consumer -
- If the co-ordinator does not receive a heartbeat for session.timeout.ms, it marks the consumer dead and breaks the socket connection to it.
- At the same time, it triggers a rebalance by sending the IllegalGeneration error code in the HeartbeatResponse to the rest of the consumers in the group.
- If the slow consumer sends a HeartbeatRequest before the co-ordinator receives a HeartbeatRequest from any of the rest of the consumers, it cancels the rebalance attempt and sends the HeartbeatResponses with no error code
- If not, the co-ordinator proceeds with the rebalance and sends the slow consumer the IllegalGeneration error code as well.
- Since the co-ordinator only waits for JoinGroupRequest from the "alive" consumers, it calls the rebalance complete once it receives join requests from the other consumers. If the slow consumer also happens to send a JoinGroupRequest, the co-ordinator includes it in the current generation if it has not already sent a JoinGroupResponse excluding this slow consumer.
- If the co-ordinator has already sent a JoinGroupResponse, it let's the current rebalance round complete before triggering another rebalance attempt right after.
- If the current round takes long, the slow consumer's JoinGroupResponse times out and it re-discovers the co-ordinator and resends the JoinGroupRequest to the co-ordinator.
Multi-threaded Consumer
----- Deprecated below -----
There are two key open questions about the rewrite design, which are more or less orthogonal to each other. so we will propose different designs for each of these open issues in the following:
1. Consumer and Coordinator Communication
Without the coordinator, the consumer already needs to communicate with the broker for the following purposes:
- Send fetch requests and get messages as responses.
- Send topic metadata requests to refresh local metadata cache.
With the coordinator, there are a few more communication patterns:
- Consumer-side coordinator failure detection and vice versa via heartbeat protocol.
- Offset management: consumers need to commit/fetch offsets to/from the coordinator.
- Group management: coordinator needs to notify consumers regarding consumer group changes and consumed topic/partition changes (e.g. rebalancing).
Among them, fetching messages, refreshing topic metdata and offset management has to be consumer-initiated, while heartbeat-based failure detection and group management can be either consumer-initiated or coordinator initiated. So the choices really are 1) who should initiate the heartbeat for failure detection, and 2) who should initiate the rebalance.
In addition, fetching requests and topic metadata requests are currently received via broker's socket server and handled by the broker's request handling threads. We can also either make the other requests received by the broker as well and pass them to the coordinator or let coordinator communicate directly with the consumers for these type of requests. I think the second option of keeping a separate channel is better since channel these requests should not be delayed by other fetch/produce requests.
Option 1.a: Consumer-Initiated Heartbeat and Consumer-Reregistration-Upon-Rebalance
If we want to support G4, then all the communication patterns must be done as consumer-initiated. Then the coordinator only needs the threadpool of rebalancers and probably its own socket server, and nothing else.
One proposed implementation following this direction can be found here. A brief summary:
- Consumer-initiated heart beat in the poll() function for controller-end consumer failure detection.
- Controller acks the heart beat if it still have the requested consumer in the group.
- Upon receiving heart beat ack consumer send fetch request and block wait for responses, and return.
- If the controller does not have the consumer in the group, kicks a rebalance process:
- Add an error message in all the heart beat requests from the consumers in the group.
- Wait until all the consumers' re-issued register consumer request.
- Send the register consumer response with the owned partition/offset info
- If the consumer does not hear the ack back after timeout or receive an error response:
- Send a metadata request to any brokers to get the new controller
- Send the register consumer request to the new controller
- Re-start from step 1.
The communication pattern would be:
<-- (register) -- Consumer (on startup or subscription change or coordinator failover)
Coordinator <-- (register) -- Consumer (on startup or subscription change or coordinator failover)
<-- (register) -- Consumer (on startup or subscription change or coordinator failover)
-----------------------------------------------------------------------------------------------------------------
Coordinator (if there is at least one consumer already in the group, send error code to their ping requests, so that they will also resend register)
Coordinator -- (error in reply) --> Consumer (rest of consumers already in the group)
Coordinator <-- (register) -- Consumer (rest of consumers already in the group)
-----------------------------------------------------------------------------------------------------------------
Now everyone in the group have sent the coordinator a register request
(record metadata) (confirm) --> Consumer (successfully received the registration response which contains the assigned partition)
Coordinator (record metadata) (confirm) -X-> Consumer (consumer did not receive the confrontation or failed during the process, will try to reconnect to the coordinator and register again)
(reject) --> Consumer (register failed due to some invalid meta info, try to reconnect to the coordinator and register again)
------------------------------- consumer registration ---------------------------------------------
After that the consumer will send one ping request every time it calls send():
Consumer.send()
Coordinator <-- (ping) -- Consumer
<-- (ping) -- Consumer
Coordinator -- (ping) --> Consumer
-- (ping) --> Consumer
Broker <–(fetch)-- Consumer (if the socket is set to writable; if it is set to readable then the consumer can directly read data, skipping this step)
Broker --(response)–> Consumer
return response // if the timeout is reached before response is returned, the empty set will return to the caller, and responses returned later will be used in the next send call.
--------------------------------------------------------------------------------------------------------------
Coordinator (failed) -- X --> Consumer (have not heard from coordinator for some time, stop fetcher and try to reconnect to the new coordinator)
-- X --> Consumer (have not heard from coordinator for some time, stop fetcher try to reconnect to the new coordinator)
Coordinator <-- (register) -- Consumer (will contain current consumed offset)
<-- (register) -- Consumer (will contain current consumed offset)
Coordinator (update the offset by max-of-them)
– (confirm) --> Consumer (contains the assigned partition)
– (confirm) --> Consumer (contains the assigned partition)
----------------------------------------------------------------------------------------------
If the coordinator have not heard from a consumer, start re-balancing by setting error to the ping reply to all other consumers
---------------------------- failure detection ----------------------------------------
The pros of this design would be having single-threaded consumer (G4) with simplified consumer-coordinator communication pattern (coordinator simply listens on each channel, receive requests and send responses).
The cons are:
- Rebalance latency is determined by the longest heart beat timeout among all the consumers.
- Hard for consumer clients to configure the heart beat timeout since it is based on its poll() function calling partition.
- Rebalance will cause all consumers to re-issue metadata requests unnecessarily.
- If a re-registration is required, poll() function may take longer than timeout.
Option 1.b: Coordinator-Initiated Heartbeat and Coordinator-Initiated Rebalance
An alternative approach is to let coordinator issue heartbeat and group management requests once the consumers have established the connection with it. Then the coordinator needs the threadpool of rebalancers, the delayed scheduler and the purgatory for heartbeat.
In this case, the consumer only needs to actively establish the connection to the coordinator on startup or coordinator failover.
<-- (register) -- Consumer (on startup or subscription change or coordinator failover)
Coordinator <-- (register) -- Consumer (on startup or subscription change or coordinator failover)
<-- (register) -- Consumer (on startup or subscription change or coordinator failover)
-----------------------------------------------------------------------------------------------------------------
(record metadata) (confirm) --> Consumer (successfully received the registration response, block reading for coordinator requests such as heartbeat, stop-fetcher, start-fetcher)
Coordinator (record metadata) (confirm) -X-> Consumer (consumer did not receive the confrontation or failed during the process, will try to reconnect to the coordinator and register again)
(reject) --> Consumer (register failed due to some invalid meta info, try to reconnect to the coordinator and register again)
------------------------------- consumer registration ---------------------------------------------
After that the consumer will just listen on the socket for coordinator requests and respond accordingly.
Coordinator (failed) -- X --> Consumer (have not heard from coordinator for some time, try to reconnect to the new coordinator)
-- X --> Consumer (have not heard from coordinator for some time, try to reconnect to the new coordinator)
----------------------------------------------------------------------------------------------
Coordinator -- (ping) --> Consumer (alive)
-- (ping) --> Consumer (failed)
----------------------------------------------------------------------------------------------
Coordinator (record offset) <-- (reply) -- Consumer (alive)
(rebalance) time out... Consumer (failed)
---------------------------- failure detection ----------------------------------------
If coordinator detects a consumer has failed or new consumer added to the group, or a topic/partition change that the group is subscribing to, issue a rebalance in two phases 1) first ask consumers to stop fetching with latest committed offset, and 2) then ask consumers to resume fetching with new ownership info.
Coordinator -- (stop-fetcher) --> Consumer (alive)
-- (stop-fetcher) --> Consumer (alive)
----------------------------------------------------------------------------------------------
Coordinator (commit offset) <-- (reply) -- Consumer (alive)
(commit offset) <-- (reply) -- Consumer (alive)
----------------------------------------------------------------------------------------------
Coordinator (compute new assignment) -- (start-fetcher) --> Consumer (alive)
-- (start-fetcher) --> Consumer (become failed)
----------------------------------------------------------------------------------------------
Coordinator <-- (reply) -- Consumer (alive)
(rebalance failed) time out... Consumer (failed)
Consumer Registration
For consumer's subscribe() function call, similar to Option 1.a we just update its subscribed topic/partitions.
The consumer's poll() function will be simply polling data from the fetching queue. It will use another fetcher thread to fetch the data. A single fetch queue will be used for the fetcher thread to append data and the poll() function call to get the data.
The fetch thread will check if it has registered with a coordinator or not, or if its subscribed topic/partitions have changed or not. If either case is true the consumer will try to register it self. If we only allow subscribe function to be called once, then the second check can be skipped.
In addition, when the consumer detects the current coordinator has failed (will talk about consumer-side coordinator failure detection later), it will also try to re-register itself with the new coordinator. Note that this registration process is blocking and will only return after it gets response.
Once the registration succeed a coordination thread will be created to just keep listening on the established socket for coordination-side requests.
| Code Block |
|---|
Boolean Consumer : registerConsumer()
1. Compute the partition id for the "offset" topic
2. Send a TopicMetadataRequest to any brokers from the list to get the leader host from the response.
3. Send a RegisterConsumerRequest to the coordinator host with the specific coordinator port and wait for the response.
4. If a non-error response is received within timeout:
4.1. Get the session timeout info from the RegisterConsumerResponse.
4.2. Start the CoordinationThread listening on the socket for coordinator-side requests.
5. If failed in step 2/3 restart from step 1.
6. If specified number of restart has failed return false.
List<MessageAndMetadata> Consumer : poll(Long timeout)
1. Poll data from the fetching queue.
2. De-serialize data into list of messages and return
ConsumerFetcherThread : doWork()
1. Check whether the coordinator is unknown or the subscribed topic/partitions have changed, if yes:
1.1. If the coordinator is known, call commitOffset(). // blocking call
1.2. Call registerConsumer(). // blocking call
2. If owned partition/offset information is unknown wait on the condition.
3. Send FetchRequest to the brokers with partition/offset information and wait for response.
4. Decompress fetched messages if necessary, and append them to the fetching queue. |
RegisterConsumerRequest
| Code Block |
|---|
{
Version => int16
CorrelationId => int64
GroupId => String
ConsumerId => String
SessionTimeout => int64
Subscribing => [<TopicPartitions>]
Topic => String
PartitionIds => [int16] // -1 indicates "any partitions"
}
|
RegisterConsumerResponse
| Code Block |
|---|
{
Version => int16
CorrelationId => int64
ErrorCode => int16
GroupId => String
ConsumerId => String
} |
Handling RegisterConsumerRequest
The coordinator, on the other hand, will only serve on behalf of a certain consumer group when it receives the RegisterConsumerRequest from some consumers of the group.
The coordinator keeps
In addition, it needs to check if the subscribed topic/partitions are "valid". This is actually an open question I think and will get back to this point later.
It uses a delayed scheduler extended background thread to send out heartbeat requests and rebalance requests (we will talk about the details later).
| Code Block |
|---|
Coordinator : handleRegisterConsumer(request : RegisterConsumerRequest)
1. Checks if its host broker is the leader of the corresponding "offset" topic partition. If yes:
1.1. If request.groupId is not in the cached consumer group list yet, call this.handleNewConsumerGroup(request.groupId, request.subscribing)
1.2. If this consumer is not in the group yet call this.handleAddedConsumer(request.consumerId, request.subscribing).
2. Otherwise send back RegisterConsumerResponse directly with errorCode "Not Coordinator". |
Handling New Consumer Group
| Code Block |
|---|
Coordinator : handleNewConsumerGroup(groupId : Int, subscribing : List[TopicAndPartition])
1. Create a new group registry with zero consumer members in coordinator
2. Check the subscribing info:
2.1. If it is a wildcard topic/count subscription, then add its group to the list of groups with wildcard topic subscriptions.
2.2. Otherwise for each topic that it subscribed to, add its group to the list of groups that has subscribed to the topic. |
Handling Added Consumer
| Code Block |
|---|
Coordinator : handleAddedConsumer(consumer : ConsumerInfo)
1. Add the heartbeat request task for this consumer to the scheduler.
2. Add the consumer registry to the group registry's member consumer registry list.
3. Validate if its subscribed topic/partitions. If not, reject the consumer by letting the caller handleRegisterConsumer to send back RegisterConsumerResponse with errorCode "Topic/Partition Not Valid".
4. Validate the session timeout value; If not, reject the consumer by letting the caller handleRegisterConsumer to send back RegisterConsumerResponse with errorCode "Session timeout Not Valid".
5. Try to rebalance by calling handleConsumerGroupRebalance() |
Coordinator-side Consumer Failure Detection
The coordinator keeps its own socket server and a background delayed-scheduler thread to send heartbeat requests and also requests to handle rebalances (will talk a little bit more on the latter).
The coordinator also keeps a HeartbeatPurgatory for bookkeeping ongoing consumer heartbeat requests.
| Code Block |
|---|
CoordinatorScheduler extends DelayedScheduler : HeartbeatTask()
1. Sends the Heartbeat Request via coordinator's SocketServer
2. Set the timeout watcher in HeartbeatRequestPurgatory for the consumer
3. this.scheduleTask(HeartbeatTask) with schedule time + session_timeout time // Add the heartbeat request task back to the queue |
Handling Consumer Failure
When the heartbeat request has been expired by the purgatory, the coordinator will set the consumer as failed by calling handleConsumerFailure (we can set the number of expired heartbeat requests until when the consumer will be treated as failed).
Also if a broken pipe is thrown for the established connection, the coordinator also treats the consumer as dead.
| Code Block |
|---|
Coordinator: handleConsumerFailure(consumer : ConsumerInfo)
1. Remove its heartbeat request task from the scheduler.
2. Close its corresponding socket from the coordinator's SocketServer.
3. Remove its registry from its group's member consumer registry list.
4. If there is an ongoing rebalance procedure by some of the rebalance handlers, let it fail directly.
5. If the group still has some member consumers, call handleConsumerGroupRebalance() |
Consumer-side Coordinator Failure Detection
If a consumer has not heard any request from the coordinator after the timeout has elapsed, it will suspects that the coordinator is dead (again we can set a number of sesstion timeout until when the coordinator will be treated as failed):
| Code Block |
|---|
ConsumerCoordinationThread : doWork
1. Listen on the established socket for requests.
2. If HeartbeatRequest is received, send out HeartbeatResponse
3. If timed out without any request received, call Consumer.onCoordinatorFailure()
Consumer : onCoordinatorFailure()
1. Close the connection to the previous coordinator.
2. Re-call registerConsumer() to discover the new coordinator. |
Handling Topic/Partition Change
This should be fairly straight-forward with coordinator registered listener to Zookeeper. The only tricky part is that when the ZK wachers are fired notifying topic partition changes, the coordinator needs to decide which consumer groups are affected by this change and hence need rebalancing.
For the algorithm described below I am only considering topic-addition, partition-deletion (due to broker down) and partition-addition. If we allow topic-deletion we need to add some more logic, but still should be straight-forward.
| Code Block |
|---|
Coordinator.handleTopicChange
1. Get the newly added topic (since /brokers/topics are persistent nodes, no topics should be deleted even if there is no consumers any more inside the group)
2. For each newly added topic:
2.1 Subscribe TopicPartitionChangeListener to /brokers/topics/topic
2.2 For groups that have wildcard interests, check whether any group is interested in the newly added topics; if yes, add the group to the interested group list of this topic
2.3 Get the set of groups that are interested in this topic, call handleGroupRebalance
Coordinator.handleTopicPartitionChange
1. Get the set of groups that are interested in this topic, and if the group's rebalance bit is not set, set it and try to rebalance the group |
Handling Consumer Group Rebalance
The rebalancing logic is handled by another type of rebalance threads, and the coordinator itself will keep a pool of the rebalance threads and assign consumer group rebalance tasks to them accordingly.
The reason of doing so is that the rebalance needs two blocking round trips between the coordinator and the consumers, and hence would be better done in a asynchronous way so that they will not interfere with or block each other. However, to avoid concurrent rebalancing of the same group by two different rebalancer threads, we need to enforce assigning the task to the same handler's queue if it is already assigned to that rebalancer.
There are cases that can cause a rebalance procedure: 1) added consumer, 2) consumer failure, 3) topic change, 4) partition change. The rebalance thread will receive a case code as well as the group id from the coordinator, and use this to decide if further actions are needed if no rebalance is required.
In addition the coordinator will keep a rebalance bit for each group it manages, indicating if the group is under rebalance procedure now. This is to avoid unnecessary rebalances.
Also we will not retry to rebalance failures any more since if any failure happens they will be very likely fatal.
| Code Block |
|---|
Coordinator : handleGroupRebalance(group : GroupInfo)
1. Check whether the group's rebalance bit is not set. If yes:
2. Set the bit and assign a rebalance task to a rebalancer's working queue (in a load balanced manner).
CoordinatorRebalancer : doWork()
1. Dequeue the next group to be rebalanced from its working queue and reset the group's bit.
2. Get the topics that are interested by the group. For each topic:
2.1. Get the number of partitions by reading from ZK
2.2. Get the number of consumers for each topic/partition from the meta information of consumers in the group it kept in memory
2.3. Compute the new ownership assignment for the topic, if no such assignment can be found then fail the task directly.
3. Check if a rebalance is necessary by trying to get the current ownership from ZK for each topic.
3.1 If there is no registered ownership info in ZK, rebalance is necessary
3.2 If some partitions are not owned by any threads, rebalance is necessary
3.3 If some partitions registered in the ownership map do not exist any longer, rebalance is necessary
3.4 If ownership map do not match with the newly computed one, rebalance is necessary
3.5 Otherwise rebalance is not necessary
4. If the rebalance is not necessary, returns immediately.
5. If rebalance is necessary, do the following:
5.1 For each consumer in the group, send the StopFetcherRequest to the SocketServer
5.2 Then wait until SocketServer has reported that all the StopFetcherResponse have been received or a timeout has expired
5.3 Commit the consumed offsets extracted from the StopFetcherResponse // this will be done as appending to local logs
5.4 For each consumer in the group, send the StartFetcherRequest to the SocketServer
5.5 Then wait until SocketServer has reported that all the StartFetcherReponse have been received or a timeout has expired
5.6 Update the new assignment of partitions to consumers in the Zookeeper // this could be just one json string in one path
6. If a timeout signal is received in either 4.2 or 4.5 from the socket server, fail the rebalance.
|
Another note is that when Stop/StartFetcherResponse is received, the purgatory can also clear all the expiration watchers for that consumer.
StopFetcherRequest
| Code Block |
|---|
{
Version => int16
CorrelationId => int64
ConsumerId => String
} |
StopFetcherResponse
| Code Block |
|---|
{
Version => int16
CorrelationId => int64
ErrorCode => int16
ConsumerId => String
ConsumedSoFar => [<PartitionAndOffset>]
} |
Consumer Handling StopFetcherRequest
| Code Block |
|---|
Consumer : handleStopFetcherRequest
1. Clear the partition ownership information (except the current consumed offsets).
2. Send the response, attach the current consumed offsets.
3. Clear the corresponding expiration watcher in StopFetcherRequestPurgatory, and if all the watchers have been cleared notify the rebalance handler. |
StartFetcherRequest
| Code Block |
|---|
{
Version => int16
CorrelationId => int64
ConsumerId => String
PartitionsToOwn => [<PartitionAndOffset>]
} |
StartFetcherResponse
| Code Block |
|---|
{
Version => int16
CorrelationId => int64
ErrorCode => int16
ConsumerId => String
} |
Consumer Handling StartFetcherRequest
| Code Block |
|---|
Consumer : handleStartFetcherRequest
1. Cache the assigned partitions along with offsets
2. Send back the StartFetcherResponse
3. call onPartitionAssigned() |
Option 1.c: Consumer-Initiated Heartbeat and Coordinator-Initiated Rebalance
A third approach would be to let consumer initiate heartbeat while coordinator initiate rebalance, and as a result consumers need to both read and write the socket established with the coordinator.
Then we do not need the HeartbeatRequestPurgatory and the Scheduler thread from the coordinator. And the failure detection mechanism would be changed to:
Coordinator (failed) <-- (ping) -- Consumer (ping timed out, try to reconnect to the new coordinator)
-- X -->
<-- (ping) -- Consumer (ping timed out, try to reconnect to the new coordinator)
-- X -->
----------------------------------------------------------------------------------------------
Coordinator <-- (ping) -- Consumer 1 (alive)
-- (response) -->
(Have not heard from consumer 2, rebalance) Consumer 2 (failed)
---------------------------- failure detection ----------------------------------------
Changes in Consumer Handling Coordinator Requests
In addition, the consumer's coordination thread logic need to be greatly changed:
| Code Block |
|---|
ConsumerCoordinationThread : doWork
1. Send HeartbeatRequest to the coordinator and put the request into the HeartbeatRequestPurgatory.
2. Listen on the established socket for requests.
2.1. If HeartbeatResponse is received, clear the expiration watcher in the purgatory.
2.2. If StopFetcherRequest is received, clear the expiration watcher in the purgatory and call handleStopFetcherRequest()
2.3. If StartFetcherRequest is received, clear the expiration watcher in the purgatory and call handleStartFetcherRequest()
3. If timed out without any request received, call Consumer.onCoordinatorFailure() |
Compared with 1.b, the heartbeat direction seems more natural, however the consumer client would be more complicated.
2. Consumer-Group Assignment and Migration
As described before each broker will have a coordinator which is responsible for a set of consumer groups. Hence we need to decide which consumer groups are assigned to each coordinator in order to 1) balance load, and 2) easy to be migrated in case of coordinator failure.
Since the coordinator is responsible for the offset management of the consumer group, and since the offsets will be stored as a special topic on the broker side (details can be found here), we can make the assignment of consumer groups to coordinators tied up with the partition leader election of the offset topic. The advantage of doing so would be easy automatic reassignment of consumer groups upon coordinator failures, but it might be not optimal for load balance (think of two groups, one with 1 consumer and another with 100). Another way would be assigning consumer groups to coordinators in a load balanced, and decoupling the offset partition leader from the coordinator of the consumers.
Option 2.a: GroupId-based Coordinator Assignment
The first approach is to treat the "offset" topic just as other topics to have an initial number of partitions (of course this number of partitions can be increased later by the add-partitions tool as other topics). Thus a set of consumer group ids would be assigned to one broker's coordinator in a fixed manner.
The pros of this approach is that coordinator assignment logic is quite simple.
The cons is that the assignment is purely based on group names, and hence could be suboptimal for load balancing. Also the migration of consumer groups would be coarsen-grained this this set of consumer groups must be migrated all to the same coordinator in a coordinator failover.
Coordinator Startup and Failover
Every server will create a coordinator object as its member upon startup.
| Code Block |
|---|
Coordinator : onStartup()
1. Register session expiration listener
2. Read all the topics from ZK
3. Initialize 1) consumer group set, 2) set of subscribed groups for each topic and 3) set of groups having wildcard subscriptions.
4. Register listeners for topics and their partition changes
5. Start up the offset manager with latest offset read from logs and cached
6. Create the threadpool of rebalancers, and heartbeat scheduler if following 1.b)
7. Create and start the SocketServer to start accepting consumer registrations. // this step must wait until tasks like offset loading have completed |
And again as we have described before the coordinators will start serving a consumer group only if it received a RegisterConsumerRequest from an unknown group's consumer. Hence the coordinator failover is done automatically and coordinators themselves are agnostic.
Offset Management
When the consumer calls "commit", a OffsetCommitRequest will be sent to the coordinator associated with the [topic/partition, offset] information. The commit function call is blocking and will only return either after it has received the response from the coordinator or timeout has reached.
The coordiantor, on the other hand, upon receiving the OffsetCommitRequest via's socket server, will call handleCommitOffset:
| Code Block |
|---|
Coordinator : handleCommitOffset (request: CommitOffsetRequest)
1. Transform offsets in the request as messages and append to the log of the "offset" topic.
2. Wait for the replicas have confirmed the committed messages. // for this topic we may config ack=-1
2. Update its offset cache.
3. Send back the CommitOffsetResponse |
OffsetCommitRequest
| Code Block |
|---|
{
Version => int16
CorrelationId => int64
ConsumerId => String
OffsetInfo => [<PartitionAndOffset>]
Topic => String
Partition => int16
Offset => int64
} |
OffsetCommitResponse
| Code Block |
|---|
{
Version => int16
CorrelationId => int64
ErrorCode => int16
} |
Option 2.b: Random Coordinator Assignment
An alternative approach is random coordinator assignment. The rationale behind this idea is load balancing: by randomly distributing consumer groups, hopefully the groups of large number of consumer will be evenly distributed to the consumers. In order to do so we would prefer to decouple the coordinator with the leader of the "offset" topic partitions.
Changes in Consumer Registration
Since now each new consumer group will be randomly assigned to a coordinator and not necessarily the one for offset management, we need coordinators to form a consensus on those decisions, and the way of doing it is via ZK.
In some more details:
- We add one more path in the root as /coordinators/[consumer_group_name]
- The node /coordinators/consumer_group_name stores the coordinator's broker id for the consumer group
- Each coordinator will have a ZK-based elector on this path.
- Each coordinator keeps a cache of the coordinators for each consumer group.
| Code Block |
|---|
Boolean Consumer : registerConsumer()
1. Send a CoordinatorMetadataRequest to any brokers from the list to get the leader host from the response.
2. Send a RegisterConsumerRequest to the coordinator host with the specific coordinator port and wait for the response.
3. Same as before..
Coordinator : handleCoordinatorMetadataRequest(request : CoordinatorMetadataRequest)
1. If the coordinator of the consumer group is in the cache, returns directly the response.
2. Otherwise try to write to /coordinators/request.consumerGroupName
2.1. If succeed, register the session timeout listener on the path, return itself as the coordinator in CoordinatorMetadataRequest
2.2. If failed:
2.2.1 Read the path to get the coordinator information and update the coordinator metadata cache.
2.2.2. Register data change listener on the path.
2.2.3. Return the read coordinator information in CoordinatorMetadataRequest |
Then on data deletion change, all the coordinators will try to re-elect as the new coordinator of the consumer group, and update the cache accordingly.
CoordinatorMetadataRequest
| Code Block |
|---|
{
Version => int16
CorrelationId => int64
ConsumerId => String
GroupId => String
} |
CoordinatorMetadataResponse
| Code Block |
|---|
{
Version => int16
CorrelationId => int64
ErrorCode => int16
CoordinatorInfo => <Broker>
Host => String
Port => int16
} |
Changes in Offset Management
Since we are not decoupling offset management from coordinator, we will keep a offset manager as described here in each broker which is parallel to the coordinator and migrates as the partition leaders.The coordinators themselves just cache the latest offset upon receiving CommitOffsetRequest.
Also upon creating the new consumer group, the coordinator would send FetchOffsetRequest to the corresponding offset manager to update its cache.
| Code Block |
|---|
Coordinator : handleNewConsumerGroup(groupId : Int, subscribing : List[TopicAndPartition])
1. Same steps as before
2. Send FetchOffsetRequest to the corresponding offset manager and wait on the response to update its offset cache. // This can be done asynchronously
Coordinator : handleCommitOffset (request: CommitOffsetRequest)
1. Update its offset cache.
2. Transform offsets in the request as messages and send a ProduceRequest to the corresponding partition leader.
3. Wait for the ack before send back the CommitOffsetResponse. |
The pros of this approach is better load balancing for coordinators, however it complicates logic quite a bit by decoupling the offset management with the coordinator.
Open Questions
Apart with the above proposal, we still have some open questions that worth discuss:
- Should coordinator use its own socket server or use broker's socket server? Although the proposal suggests former we can think about this more.
- Should we allow consumers from the same group to have different session timeout? If yes when do we reject a consumer registration because of its proposed session timeout?
- Should we allow consumers from the same group have specific fixed subscribing topic partitions (G5)? If yes when do we reject a consumer registration with its subscribed topic partitions?
- Should we provide tools to delete topics? If yes, how will this affect coordinator's topic change logic?
- Should we do de-serialization/compression in fetcher thread or user thread? Although the proposal suggests de-serialization in user thread and de-compression in fetcher thread (or deserialization/compression all in client thread if we are following Option 1.a) we can still think about this more.
- Do we allow to call subscribe multiple times during its life time? This is related to G5.a
- Do we allow users to specify the offsets in commit() function call, and explicitly get last committed offset? This is related to G6.a
- Would we still keep a zookeeper string in consumer properties for consumer to read the bootstrap broker list as an alternative to the broker list property?
- Shall we try to avoid unnecessary rebalances on coordinator failover? In the current proposal upon coordinator failover the consumers will re-issue registration requests to the new coordinator, causing the new coordinator to trigger rebalance that is unnecessary.
- Shall we restrict commit offset request to only for the client's own assigned partitions? For some use cases such as clients managing their offsets themselves and only want to call commit offset once on startup, this might be useful.
- Shall we avoid request forwarding for option 2.b? One way to do that is let consumer remember two coordinators, and upon receiving stop fetching from group management coordinator, send a commit offset request to offset management coordinator and wait on response, and then respond to the stop fetching request.
...