THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
Current state: "Under Discussion"
Discussion thread: here [Change the link from the KIP proposal email archive to your own email thread]
JIRA: here [Change the link from KAFKA-1 to your own ticket]
...
Note this is a joint work proposed by Xinli Shang Qichao Chu Zhifeng Chen @Yang Yang
Motivation
Kafka is typically used in conjunction with Avro, JSON, or Protobuf etc to serialize/deserialize data record by record. In the producer client, records are buffered as a segment (record batch), and compression is optionally applied to the segment. When the number of records in each segment is larger, columnar storage like Apache Parquet becomes more efficient in terms of compression ratio, as compression typically performs better on columnar storage. This results in benefits for reducing traffic throughput to brokers/consumers and saving disk space on brokers.
...
We divide consumers into two categories. Minimum change is needed for messaging consumers for reading the Parquet segment, and a new consuming method is proposed to add for ingestion consumers. The way to divide into the two categories and these terms are used solely for the purpose of this proposal.
...
For applications expecting a batch of records or even the entire segment to write to the sink (data lake), the Kafka consumer client can simply return byte buffer of the entire segment to the application, allowing it to directly dump it into the sink. The necessary change involves adding a new consumer API to return the segment byte buffer and bypass decompression.
We refer to the first type of use case as a messaging consumer and the second one as an ingestion consumer.
...
To set up the context for discussing the changes in the next section, let’s examine the current data formats in the producer, broker, and consumer, as well as the process of transformation outlined in the following diagram. We don’t anticipate changes to the broker, so we will skip discussing its format.
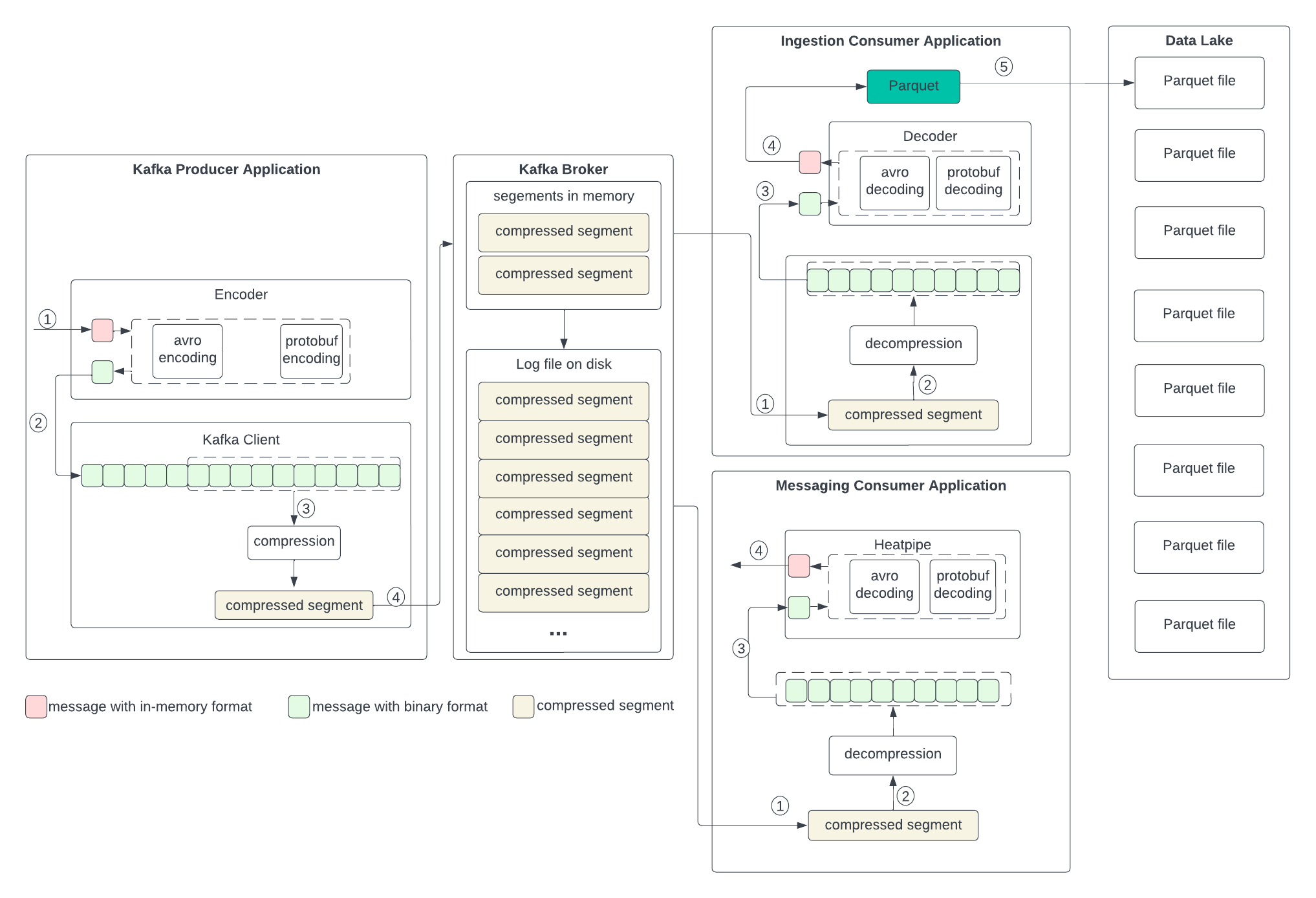
Producer
The producer writes the in-memory data structures to an encoder to serialize them to binary and then sends them to the Kafka client.
...
In the following diagram, we describe the proposed data format changes in each state and the process of the transformation. In short, we propose replacing compression with Parquet. Parquet combines encoding and compression at the segment level. The ingestion consumer is simplified by solely dumping the Parquet segment into the data lake.
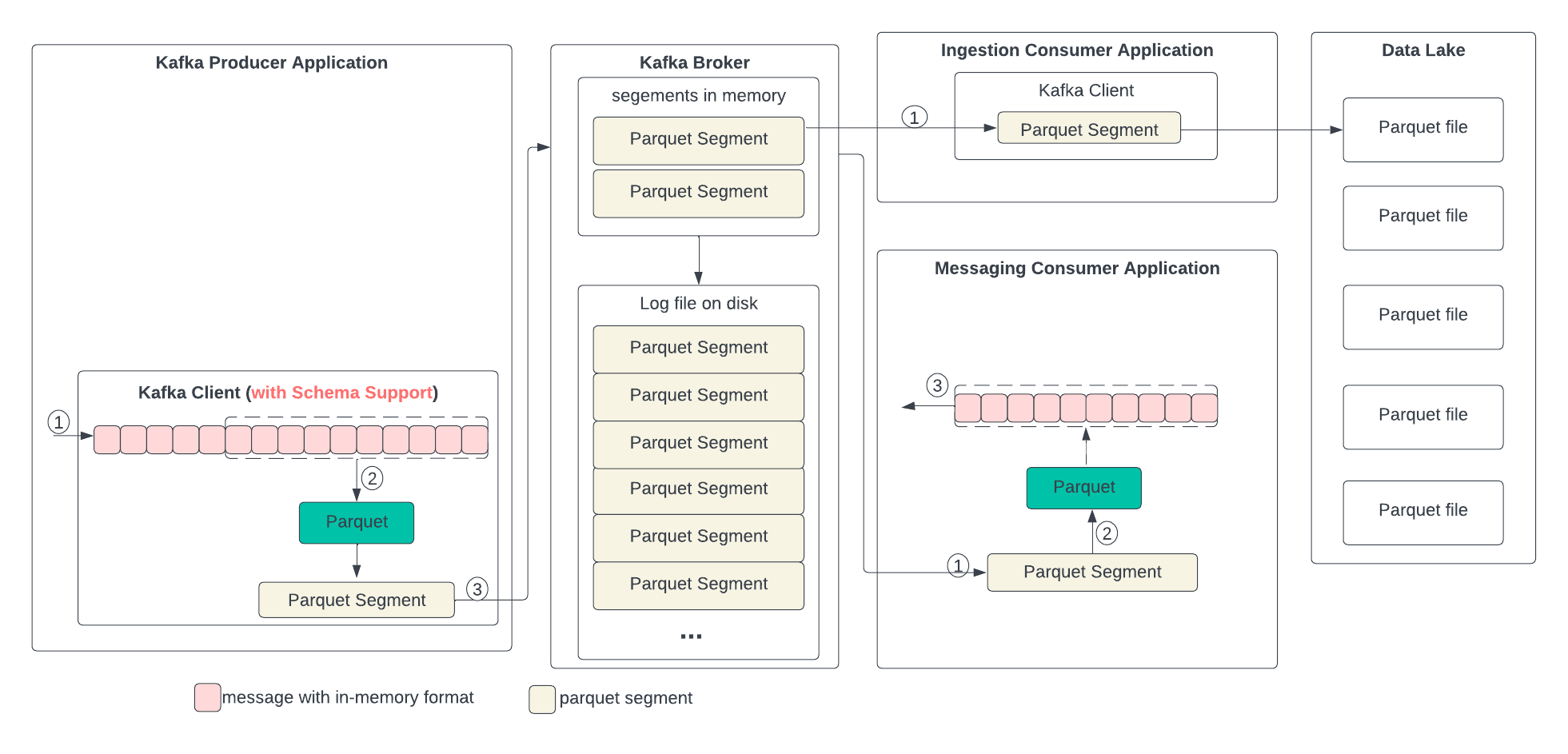
Producer
The producer writes the in-memory data structures directly to the Kafka client and encodes and compresses all together.
...
- The consumer gets the segment from the broker.
- If the segment is in Parquet format, it uses the Parquet library to decode and optionally decompress.
- The record in the in-memory format is then sent to the application.
Ingestion Consumer
- The consumer gets the segment with Parquet format from the broker and sends it directly to the data lake.
...
Type: | string |
Default: | none |
Valid Values: | [none, gzip, snappy, lz4, zstd] |
Importance: | highlow |
Compatibility, Deprecation, and Migration Plan
...
- Regression test - The configuration ‘columnar.encoding’ is set to 'none’, run all the tests in Uber staging env which includes but is not limited to read/write with different scales.
- Added feature - The configuration ‘columnar.encoding’ is set to 'parquet’.
- Verify the data is encoded as Parquet format
- The producer, broker, and consumer all work as before functionality-wide. No exceptions are expected.
- The newly added consumer API should be able to return the whole segment as Parquet format directlyconsumer fetches the data as byte buffer with 'fetch.raw.bytes' set and the data is with Parquet format.
Performance tests
Run tests for different topics that should have different data types and scale
...
- Both producer and consumer have the proposed changes
- The feature is turned off in configuration, all all regression tests should work as before.
- When the producer turns on this feature, the consumer and replicator can consume as before.
- Producer has the proposed changes, but the consumer doesn’t
- The feature is turned off in configuration, all all regression tests should work as before.
- When the producer turns on this feature, the consumer and replicator throw an exception
- Producer doesn’t have the proposed changes, but the consumer does
- All the regression tests should pass
...