THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
S1 in the below diagram
| Table of Contents |
|---|
Status
Current state: Under DiscussionImplementing
Discussion thread: https://lists.apache.org/thread/pqj9f1r3rk83oqtxxtg6y5h7m7cf56r2
JIRA:
| Jira | ||||||
|---|---|---|---|---|---|---|
|
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
...
This KIP will go over scenarios where we might expect disruptive servers and discuss how Pre-Vote (as originally detailed in the extended Raft paper and in KIP-650) along with Followers rejecting Pre-Vote Requests can ensure correctness when it comes to network partitions.
Pre-Vote is the idea of “canvasing” “canvassing” the cluster to check if it would receive a majority of votes - if yes it increases its epoch and sends a disruptive vote request. If not, it does not increase its epoch and does not send a vote request.
...
{
"apiKey": 52,
"type": "request",
"listeners": ["controller"],
"name": "VoteRequest",
"validVersions": "0-1",
"flexibleVersions": "0+",
"fields": [
{ "name": "ClusterId", "type": "string", "versions": "0+",
"nullableVersions": "0+", "default": "null"},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "ReplicaEpoch", "type": "int32", "versions": "0+",
"about": "The epoch of the prospective or candidate sending the request"},
{ "name": "ReplicaId", "type": "int32", "versions": "0+", "entityType": "brokerId",
"about": "The ID of the voter sending the request"},
{ "name": "LastOffsetEpoch", "type": "int32", "versions": "0+",
"about": "The epoch of the last record written to the metadata log"},
{ "name": "LastOffset", "type": "int64", "versions": "0+",
"about": "The offset of the last record written to the metadata log"},
{ "name": "PreVote", "type": "booleanbool", "versions": "1+",
"about": "Whether the request is a PreVote request (no epoch increase) or not."}
...
}...
{
"apiKey": 52,
"type": "response",
"name": "VoteResponse",
"validVersions": "0-1",
"flexibleVersions": "0+",
"fields": [
{ "name": "ErrorCode", "type": "int16", "versions": "0+",
"about": "The top level error code."},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "ErrorCode", "type": "int16", "versions": "0+"},
{ "name": "LeaderId", "type": "int32", "versions": "0+", "entityType": "brokerId",
"about": "The ID of the current leader or -1 if the leader is unknown."},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The latest known leader epoch"},
{ "name": "VoteGranted", "type": "bool", "versions": "0+",
"about": "True if the vote was granted and false otherwise"},
{ "name": "PreVote", "type": "booleanbool", "versions": "1+",
"about": "Whether the response is a PreVote response or not."}
...
}...
| Section | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
We add a new quorum state
|
A follower will now transition to Prospective instead of Candidate when its fetch timeout expires. Servers will only be able to transition to Candidate state from the Prospective state.
A Prospective server will send a VoteRequest with the The Prospective server will send a VoteRequest with the PreVote field set to true and ReplicaEpoch set set to its current, unbumped epoch. If [majority - 1] of VoteResponse grant the vote, the server will transition to Candidate and will then bump its epoch up and send a VoteRequest with PreVote set to false (which is the original behavior).
When servers receive VoteRequests with the PreVote field set to true, they will respond with VoteGranted set to
...
false(standard vote) if the server has received [majority - 1] VoteResponses withVoteGrantedset totruewithin [election.timeout.ms + a little randomness]true(another Pre-Vote) if the server receives [majority] VoteResponse withVoteGrantedset tofalsewithin [election.timeout.ms + a little randomness]trueif the server receives less than [majority] VoteResponse withVoteGrantedset tofalsedoes not receive enough votes (granted or rejected) within [election.timeout.ms + a little randomness] and the first bullet point does not applyExplanation for why we don't send a standard vote at this point is explained in rejected alternatives.
If a server happens to receive multiple VoteResponses from another server for a particular VoteRequest, it can take the first and ignore the rest. We could also choose to take the last, but taking the first is simpler. A server does not need to worry about persisting its election state for a Pre-Vote response like we currently do for VoteResponses because the direct result of the Pre-Vote phase does not elect leaders.
Also, if a Candidate is unable to be elected (transition to Leader) before its election timeout expires, it will transition back to Prospective. This will handle the case if a network partition occurs while the server is in Candidate state and prevent unnecessary loss of leadership.
How does this prevent unnecessary leadership loss?
We prevent servers from increasing their epoch prior to establishing they can win an election.
Can this prevent necessary elections?Pre-Vote prevent a quorum from electing a leader?
Yes, Pre-Vote needs an additional safeguard to prevent scenarios where eligible leaders cannot be elected.
If a leader is unable to send FETCH responses to [majority - 1] of servers, no new metadata can be committed and we will need a new leader to make progress. We may need the minority of servers which Yes. If a leader is unable to receive fetch responses from a majority of servers, it can impede followers that are able to communicate with it from voting in an eligible leader that the leader to grant their vote to prospectives which can communicate with a majority of the cluster. This Without Pre-Vote, the epoch bump would have forced servers to participate in the election. With Pre-Vote, the minority of servers which are connected to the leader will not grant Pre-Vote requests. This is the reason why an additional "Check Quorum" safeguard is needed which is what KAFKA-15489 implements. Check Quorum ensures a leader steps down if it is unable to receive fetch send FETCH responses from to a majority of servers. This will free up all servers to grant their votes to eligible prospectives.
Why do we need Followers to reject Pre-Vote requests? Shouldn't the Pre-Vote and Check Quorum mechanism be enough to prevent disruptive servers?
...
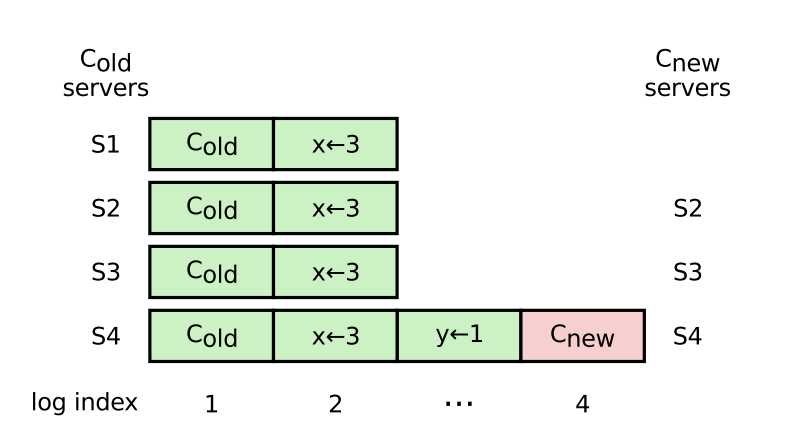
- Scenario B: A server in an old configuration (e.g. S1 in the below diagram, pg 41 of Raft paper) starts a “pre-vote” when the leader is temporarily unavailable, and is elected because it is as up-to-date as the majority of the quorum. We can not technically rely on the original leader replicating fast enough to remove S1 from the quorum - we can imagine some bug/limitation with quorum reconfiguration causes S1 to continuously try to start elections when the leader is trying to remove it from the quorum. This scenario will be covered by KIP-853: KRaft Controller Membership Changes or future work if not covered here.
The logic now looks like the following for servers receiving VoteRequests with PreVote set to true:
When servers receive VoteRequests with the PreVote field set to true, they will respond with VoteGranted set to
trueif they are not a Follower and the epoch and offsets in the Pre-Vote request satisfy the same requirements as a standard votefalseif they are a Follower or the epoch and end offsets in the Pre-Vote request do not satisfy the requirements
Compatibility
Compatibility
We currently use ApiVersions to gate new/newer versions of Raft APIs from being used before all servers can support it. This is useful in the upgrade scenario for Pre-Vote - if a We currently use ApiVersions to gate new/newer versions of Raft APIs from being used before all servers can support it. This is useful in the upgrade scenario for Pre-Vote - if a server attempts to send out a Pre-Vote request while any other server in the quorum does not understand it, it will get back an UnsupportedVersionException from the network client and knows to default back to the old behavior. Specifically, the server will transition from Prospective immediately to Candidate state, and will send standard votes instead which can be understood by servers on older software versions.
...
Time | Server 1 | Server 2 | Server 3 |
|---|---|---|---|
T0 | Leader with majority of quorum (Server 1, Server 3) caught up with its committed data | Lagging follower | Follower |
T1 | Disk failure | ||
T2 | Leader → Unattached state | Follower → Unattached state | Comes back up w/ new disk, triggers an election before catching up on replication |
Will not be elected | |||
T4 | Election ms times out and starts an election | ||
T5 | Votes for Server 2 | Votes for Server 2 | |
T6 | Elected as leader leading to data loss |
Sending Standard Votes after failure to win Pre-Vote
...