THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
| Page properties | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Document the state by adding a label to the FLIP page with one of "discussion", "accepted", "released", "rejected".
|
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
...
When Kafka partitions are increased, users want to be able to dynamically discover new partitions without having to restart the Flink job. Although Flink already provides the ability of dynamic partition discovery, there are still two some problems:
- Dynamic partition discovery is disabled by default, and users have to specify the interval of discovery in order to turn it on.
- The strategy used for new partitions is same as the initial offset strategy, instead of the earliest strategy. According to the semantics, if the startup strategy is latest, the consumed data should include all data from the moment of startup, which also includes all messages from new created partitions. However, the latest strategy currently maybe used for new partitions, leading to the loss of some data (thinking a new partition is created and might be discovered by Kafka source several minutes later, and the message produced into the partition within the gap might be dropped if we use for example "latest" as the initial offset strategy).if the data from all new partitions is not read, it does not meet the user's expectations. Other ploblems see final Section:
User specifies OffsetsInitializer for new partition. - Current JavaDoc does not display the whole behavior of OffsetsInitializers. There will be a different offset strategy when the partition does not meet the condition.(See final Section:
User specifies OffsetsInitializer for new partition.).
Therefore, this Flip has two there main objectives:
- Enable partition discovery by default.
- Use earliest as the offset
Provide a EARLIEST strategy for
new partitions after the first discovery , regardless of the startup offset strategy. Except for the first partition discovered during a clean startup, which uses the user-specified startup strategy, all subsequent partitions (including newly added partitions after a failure restart) should use earliest.
later discovered partitions.
- Organize the code logic of the current built-in OffsetsInitializer, then modify the JavaDoc to let users know.
Public Interfaces
JavaDoc of SpecifiedOffsetsInitializer
add this: "Use Specified offset for specified partitions while use commit offset or Earliest for unspecified partitions. Specified partition offset should be less than the latest offset, otherwise it will start from the earliest. "
JavaDoc of TimestampOffsetsInitializer
add this: "Initialize the offsets based on a timestamp. If the message meeting the requirement of the timestamp have not been produced to Kafka yet, just use the latest offset"
...
Kafka table source (Table / SQL API)
...
Both negative and zero will be interpreted as disabling the feature.
KafkaSourceEnumerator
Add variable attributes unAssignedInitialPartitons and initialPartitionDone to attributes unassignedInitialPartitons and initialDiscoveryFinished to KafkaSourceEnumerator, which will be explained in the Proposed Changes section.
| Code Block | ||||
|---|---|---|---|---|
| ||||
public KafkaSourceEnumerator(
KafkaSubscriber subscriber,
OffsetsInitializer startingOffsetInitializer,
OffsetsInitializer stoppingOffsetInitializer,
Properties properties,
SplitEnumeratorContext<KafkaPartitionSplit> context,
Boundedness boundedness,
Set<TopicPartition> assignedPartitions,
Set<TopicPartition> unAssignedInitialPartitonsunassignedInitialPartitons,
boolean noDiscovery
initialDiscoveryFinished ) {
}
public KafkaSourceEnumerator(
KafkaSubscriber subscriber,
OffsetsInitializer startingOffsetInitializer,
OffsetsInitializer stoppingOffsetInitializer,
Properties properties,
SplitEnumeratorContext<KafkaPartitionSplit> context,
Boundedness boundedness) {
this(
subscriber,
startingOffsetInitializer,
stoppingOffsetInitializer,
properties,
context,
boundedness,
Collections.emptySet(),
Collections.emptySet(),
falsetrue
);
}
|
KafkaSourceEnumState
Depends on the proposed changes.
| Code Block |
|---|
public class KafkaSourceEnumState {
private final Set<KafkaPartitionWithAssignStatus> assignedAndInitialPartitions;
private final boolean initialDiscoveryFinished;
}
class KafkaPartitionWithAssignStatus {
private final TopicPartition topicPartition;
private int assignStatus;
}
enum KafkaPartitionSplitAssignStatus{
ASSIGNED,
UNASSIGNED_INITIAL
}
|
Proposed Changes
Main Idea
...
Note: The current design only applies to cases where all existing partitions can be discovered at once. If all old partitions cannot be discovered at once, the subsequent old partitions discovered will be treated as new partitions, leading to message duplication. Therefore, this point needs to be particularly noted.
Add
...
unassignedInitialPartitons and
...
initialDiscoveryFinished to snapshot state
Add the unAssignedInitialPartitonsunassignedInitialPartitons(collection) and firstDiscoveryDone initialDiscoveryFinished(boolean) to the snapshot state. unAssignedInitialPartitonsunassignedInitialPartitons represents the collection of first-discovered partitions that have not yet been assigned. firstDiscoveryDone represents whether the first-discovery has been done.
The reason for these two attributes is explained below:
Why do we need the unAssignedInitialPartitonsunassignedInitialPartitons collection? Because we cannot guarantee that all first-discovery partitions will be assigned before checkpointing. After a restart, all partitions will be re-discovered, but only whether the partition has been assigned can be determined now, not whether the unassigned partition is a first-discovered partition or a new partition. Therefore, unAssignedInitialPartitonsunassignedInitialPartitons is needed to represent the first-discovered partitions that have not been assigned, which should be an empty set during normal operation and will not take up much storage.
Why do we need firstDiscoveryDone initialDiscoveryFinished? Only relying on the unAssignedInitialPartitonsunassignedInitialPartitons attribute cannot distinguish between the following two cases (which often occur in pattern mode):
- The first partition discovery is so slow, before which the checkpoint is executed and then job is restarted . At this time, the restored
unAssignedInitialPartitonsunassignedInitialPartitonsis an empty set, which means non-discovery. The next discovery will be treated as first discovery. - The first time the partition is discovered is empty, and new partitions can only be found after multiple partition discoveries. If a restart occurs between this period, the restored
unAssignedInitialPartitonsunassignedInitialPartitonsis also an empty set, which means empty-discovery.The next discovery will be treated as new discovery.
Now that the partitions must be greater than 0 when creating topics, when the second case will occur? There are three ways to specify partitions in Kafka: by topic, by partition, and by matching the topic with a regular expression. Currently, if the initial partition number is 0, an error will occur for the first two methods. However, when using a regular expression to match topics, it is allowed to have 0 matched topics.
The following is a modification of KafkaSourceEnumState:
| Code Block | ||
|---|---|---|
| ||
public class KafkaSourceEnumState {
private final Set<TopicPartition> assignedPartitions;
private final Set<TopicPartition> unAssignedInitialPartitonsunassignedInitialPartitons;
private final boolean firstDiscoveryDoneinitialDiscoveryFinished;
} |
Merge assignedPartitions and
...
unassignedInitialPartitons collections
Following the previous plan, the snapshot state needs to save both assignedPartitions and unAssignedInitialPartitonsunassignedInitialPartitons collections. Item of both collections are TopicPartition, but with different status. Therefore, we can use one collection to pull all them in.
Adding a status would make it easier to extend the process of partitions discovery through additional rules in the future.
Every Kafka partition in the Kafka snapshot state will have a "type" attribute indicating whether it is assigned or initial:
- assigned: the partition has already been assigned to the reader , which can be restored as
assignedPartition. - unassignedInitial: unassigned part of the first-discovered partition, which can be restored as
unAssignedInitialPartitions.
The following is a modification of KafkaSourceEnumState:
| Code Block | ||
|---|---|---|
| ||
public class KafkaSourceEnumState {
private final Set<KafkaPartitionWithAssignStatus> assignedAndInitialPartitions;
private final boolean firstDiscoveryDoneinitialDiscoveryFinished;
}
class KafkaPartitionWithAssignStatus {
private final TopicPartition topicPartition;
private int assignStatus;
}
enum KafkaPartitionSplitAssignStatus{
ASSIGNED,
UNASSIGNED_INITIAL
}
|
...
Changing KafkaSourceEnumState also requires changing the corresponding serialization and deserialization methods. Compatibility issues should be taken into consideration during deserializing. Thus, pay attentions to KafkaSourceEnumStateSerializer.
Test Plan
This feature will be guarded by unit tests and integration tests in the Kafka connector's source code.
...
Disadvantage: The partition discovery, partition assignment, and checkpoint operation are coupled together. if the partition is not assigned before checkpointing, the SourceCoordinator's event-loop thread will be blocked, but partition assignment also requires the event-loop thread to execute, which will cause thread self-locking. Therefore, the existing thread model needs to be changed, which is more complicated.

Alternative to the
...
initialDiscoveryFinished variable
As mentioned before, the reason for introducing firstDiscoveryDone is that, after restarting, if the unAssignedInitialPartitions in the snapshot state is empty, it cannot be determined whether it’s because of non-discovery or empty-discovery.
...
However, this method is only to reduce one boolean variable in the snapshot state, but the event-loop thread will be blocked for this purpose, which is not worth it. Partition discovery can be a heavily time-consuming operation, especially when pattern matching a large number of topics. In this case, the SourceCoordinator cannot process other event operations during the waiting period, such as Reader registration.

User specifies OffsetsInitializer for new partition
Plan
The Add the OffsetsInitializer for the newly discovered partition. Its default value is EARLIEST. If the user needs to, they can adopt different strategies.
| Code Block | ||||
|---|---|---|---|---|
| ||||
public class KafkaSourceBuilder<OUT> {
public KafkaSourceBuilder<OUT> setNewDiscoveryOffsets(
OffsetsInitializer newDiscoveryOffsetsInitializer) {
this.newDiscoveryOffsetsInitializer = newDiscoveryOffsetsInitializer;
return this;
}
} |
Reject Reason
SpecifiedOffsetsInitializer
First, let's take a look at what happens in the current SpecifiedOffsetsInitializer. When use SpecifiedOffsetsInitializer, the following strategy is adopted for unspecified partitions(See SpecifiedOffsetsInitializer#getPartitionOffsets):
- Use committed offset first.However, new partitions don’t have committed offsets.
- If there is no committed offset, use Kafka's OffsetResetStrategy. Currently, Kafka's OffsetResetStrategy is set to Earliest. (See KafkaDynamicSource#createKafkaSource -> OffsetsInitializer#offsets)

That is, for specified partitions, use Specified offset, and for unspecified partitions, use Earliest.
For continuous streaming jobs, unspecified partitions are more common.
The problem of specified partitions is that the latest offset of a new partition is generally 0 or a small value when discovery, which is very unpredictable and unreasonable. If the specified offset is greater than that value, Kafka Client will consume according to the OffsetResetStrategy, that is EARLIEST (See org.apache.kafka.clients.consumer.internals.Fetcher#handleOffsetOutOfRange).
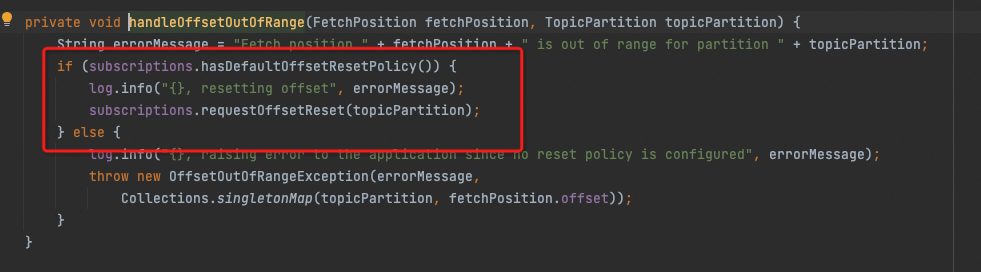
For example, if the Specified offset of topic1-1 is set to 10, when new partition-1 is discovered with offsets range of [0, 5], all messages in the range of [0, 5] will be consumed. When new partition-1 is discovered with offsets range of [0, 15], then consumption will begin from offset 10. If partition-2 has no specified offset, when new partition-2 is discovered with offsets range of [0, 15], all messages in the range of [0, 15] will be consumed.
Using "Earliest" ensures that the same behavior of consuming offsets for new partitions is maintained.
The specified offset strategy only affects existing partitions and can start from a certain point in middle of offset range . It should not be used for new partitions.
TimestampOffsetsInitializer
Next, let's take a look at what happens in the current TimestampOffsetsInitializer. If the timestamp is too late, it will fail to hit the new partition’s message. In this case, the offset will be set to the latest offset (see TimestampOffsetsInitializer#getPartitionOffsets).
It would be difficult to estimate the time if the new partition uses timestamps. If we set the new partition as a timestamp during startup:
- For the new partitions before this timestamp, they will be immediately adopted using the latest offset once discovered, instead of waiting until the timestamp. It also depends on how many messages are written between partition creation and discovery, which is very unpredictable and unreasonable.
- For the new partitions created after this timestamp, it will be equivalent to the earliest.(For continuous streaming jobs, this is more common.)
For example, if the timestamp is set to tomorrow at 7:00, partitions created before 7:00 tomorrow will be consumed from the latest offset of discovered moment, while partitions created after 7:00 tomorrow will be consumed from the earliest offset.
The timestamp strategy only affects existing partitions and can start from a certain point in middle of time range. It should not be used for new partitions.
Conclusion
All these problems can be reproducible in the current version. The reason why they haven't been exposed is probably because users usually set the existing specified offset or timestamp, so it appears as earliest in production.
After analyzing the above, using EARLIEST is the most reasonable option.
All these problems can be reproducible in the current version. The reason why they haven't been exposed is probably because users usually set the existing specified offset or timestamp, so it appears as earliest in production.
All these problems can be reproducible in the current version. The reason why they haven't been exposed is probably because users usually set the existing specified offset or timestamp, so it appears as earliest in production.
All these problems can be reproducible in the current version. The reason why they haven't been exposed is probably because users usually set the existing specified offset or timestamp, so it appears as earliest in production.