THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
BytePS is a high-performance, cross-framework architecture for distributed training. In various hardware settings, it has shown performance advantages compared with Horovod+NCCL. In addition, it supports asynchronous training that Horovod (and all other all-reduce based distributed framework) cannot support. It works for MXNet, TensorFlow and PyTorch, and can run on TCP and RDMA network. The code repository is at https://github.com/bytedance/byteps.
BytePS implementation is a close relative to MXNet. It largely reuses ps-lite and MXNet kvstore_dist_server implementation for network communication and summing up gradients. However, it also adds its own optimization, which is not backward compatible with upstream MXNet’s ps-lite and kvstore implementation.
Consequently, to use MXNet+BytePS, although users are free to choose any MXNet versions as MXNet workers, they have to use a dedicated MXNet version (provided by BytePS team) as BytePS servers. This often causes confusion because sometimes users have to install two versions of MXNet to use MXNet+BytePS.
Hence, the BytePS team proposes to integrate the changes BytePS made to ps-lite and kvstore_dist_server into upstream MXNet. Ideally, upstream MXNet can work as BytePS servers directly.
BytePS now relies on ps-lite as its third party communication library.
Value proposition
Below are the benefits of this proposed integration.
...
Therefore, we plan to make the following code changes to adapt to existing MXNet and ps-lite repositories:
MXNet KVstoreImplement a new subclass of the KVstoreDistServer class, and provide a knob (e.g., an environment variable) for MXNet users to switch between vanilla KVstoreDistServer and BytePS-KVstoreDistServer. The major modifications would be in “incubator-mxnet/src/kvstore/kvstore_dist_server.h” file.- ps-lite
- Implement two subclasses of the Van class for BytePS-TCP and BytePS-RDMA, respectively. In fact, existing ps-lite already incorporates ZMQVan and IBVerbsVan. We can follow their approaches similarly and add two more subclasses, i.e., BytepsTcpVan and BytepsRdmaVan. We plan to add two header files for these two subclasses, respectively. At run-time, we can determine the actual Van implementation via environment variables or other methods.
- To facilitate high performance RDMA, we also need to add several new fields for the protobuf data format of ps-lite. However, the change is incremental and will not affect the original ps-lite.
...
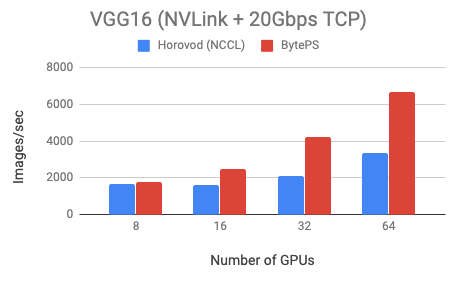
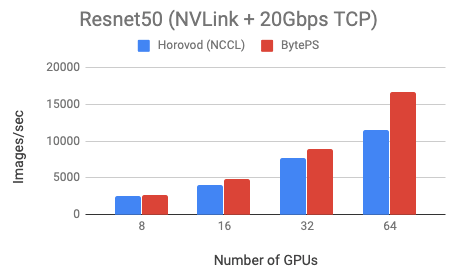
BytePS outperforms Horovod (NCCL) by 44% for Resnet50, and 100% for VGG16.


RDMA Network Benchmark
...
We use Tesla V100 32GB GPUs and set batch size equal to 64 per GPU. Each machine has 8 V100 GPUs with NVLink-enabled. Machines are inter-connected with 100 Gbps RoCEv2 network.
BytePS outperforms Horovod (carefully tuned) by 16% in this case, both with RDMA enabled.
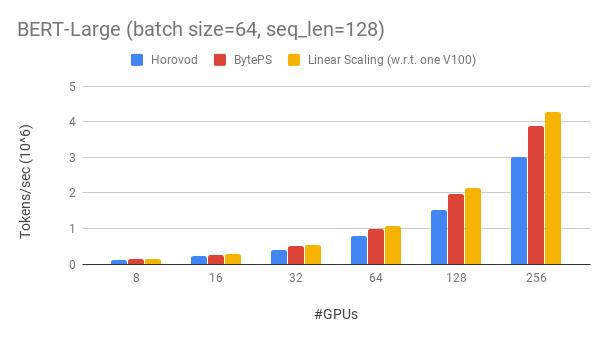
achieves ~90% scaling efficiency for BERT-large with 256 GPUs. As a comparison, Horovod+NCCL has only ~70% scaling efficiency even after expert parameter tunning.

Limitation
BytePS currently has the following limitations:
...
- You only use one GPU. There is no communication for single GPU training, so BytePS does not give you any benefit.
- Your distributed training already achieves (near-)linear scaling. That means your task is not bottlenecked by communication (but by computation instead). BytePS only optimizes the communication.
The rationale of BytePS
This page explains why BytePS outperforms Horovod (and other existing Allreduce or PS based frameworks) in details: https://github.com/bytedance/byteps/blob/master/docs/rationale.md
Contact
For the above, "we" stand for the BytePS team. The primary developers of BytePS team now are Yibo Zhu, Yimin Jiang and Chang Lan. They can be reached via the following email address. We also thank other developers as well.
...