THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
To be Reviewed By:
Authors: Alberto Bustamante Reyes (alberto.bustamante.reyes@est.tech)
Status: Draft | Discussion | Active | Dropped | Superseded Development
Superseded by: N/A
Related: N/A
...
There is a problem with Geode WAN replication when GW receivers are configured with the same hostname-for-senders and port on all servers. The reason for such a setup is deploying Geode cluster on a Kubernetes cluster where all GW receivers are reachable from the outside world on the same VIP and port. Other kinds of configuration (different hostname and/or different port for each GW receiver) are not cheap from OAM operation & maintenance and resources perspective in cloud native environments and also limit some important use-cases (like scaling).
...
Example, using "cluster-1" and "cluster-2", both with one locator and two servers. :
|
If one server is stopped on "cluster-2", both senders in "cluster-1" are disconnected:
...
And some minutes later, all connections are lost:
|
Checking the logs again, we can see new logs from the ClientHealthMonitor:
...
|
Now ClientHealthMonitor is closing connections in server-1, but in this time it does not seem to be related to a ping problem:
...
root@server-1:/# grep ClientHealthMonitor server-1/server-1.log
[info 2020/03/10 14:02:34.275 GMT <main> tid=0x1] ClientHealthMonitorThread maximum allowed time between pings: 60000
[warn 2020/03/10 14:15:30.846 GMT <ServerConnection on port 32000 Thread 4> tid=0x4a] ClientHealthMonitor: Unregistering client with member id identity(172.17.0.4(server-0:69)<v1>:41000,connection=1 due to: The connection has been reset while reading the header
Anti-Goals
N/A
Solution
Gw sender failover
Solution consists on refactoring some maps on LocatorLoadSnapshot class. They use ServerLocation objects as key, this has to change due to it will not be unique for each server. We changed the maps to use InternalDistributedMember objects as key for the map entries. The ServerLocation information is not lost, as it is contained in the entry value for all the maps.
The same refactoring is done in EndPointManager, as it holds a map of endpoints that also uses ServerLocation objects as key.
Check this commit for a draft of the proposed solution: https://github.com/apache/geode/pull/4824/commits/b180869c73095e7a810ba2e1c92e243a0220e888
Gw sender pings not reaching gw receivers
When PingTask are run by LiveServerPinger, they call PingOp.execute(ExecutablePool pool, ServerLocation server). PingOp only uses hostname and ip (ServerLocation) to get the connection to send the ping message. As all receivers are sharing the same host and port, it is not guaranteed that the connection is really pointing to the server we want to connect to.
Solution consists on the modification of the ping messages to include info about the server they want to reach. If the messages are received by other server, they can be sent to the proper server.
Other alternative is the addition of a retry mechanism to PingOp to be able to discard a connection if the endpoint of that connection is not the server we want to connect to. We have added a new method PingOp.execute(Executable pool, Endpoint endpoint) to solve this. In this way, if the connection obtained is not pointing to the required Endpoint, it can be discarded an ask for a new one.
Other alternatives to the retry mechanism that we have not explored could be:
- Add the option for deactivating the ping mechanism for gw sender/gw receivers communication
- Send the ping using just existing connections, not creating new ones.
Changes and Additions to Public Interfaces
N/A
Performance Impact
When getting the connection to execute the ping, some retries could happen until the right connection is obtained so this operation will take longer, but we do not think it will impact performance.
Backwards Compatibility and Upgrade Path
N/A
Anti-Goals
What is outside the scope of what the proposal is trying to solve?
Solution
Gw sender failover
We have implemented a solution for this issue in the following commit: https://github.com/apache/geode/pull/4713/commits/f896f04df291246d420cab88b660fc9736fca49b
There is just one test failing (testExecuteOp from ConnectionPoolImplJUnitTest) that causes integration test and stress test tasks to fail. The tests works locally, only fails in concourse.
Solution consists on refactoring some maps on LocatorLoadSnapshot class. They use ServerLocation objects as key, this has to change due to it will not be unique for each server. We changed the maps to use InternalDistributedMember objects as key for the map entries. The ServerLocation information is not lost, as it is contained in the entry value for all the maps.
The same refactoring is done in EndPointManager, as it holds a map of endpoints that also uses ServerLocation objects as key.
Gw sender pings not reaching gw receivers
We think the reason behind the issue of the pings is the way they are created. When a new server connection is established, a new PingTask is created and will be in charge of running the PingOp:
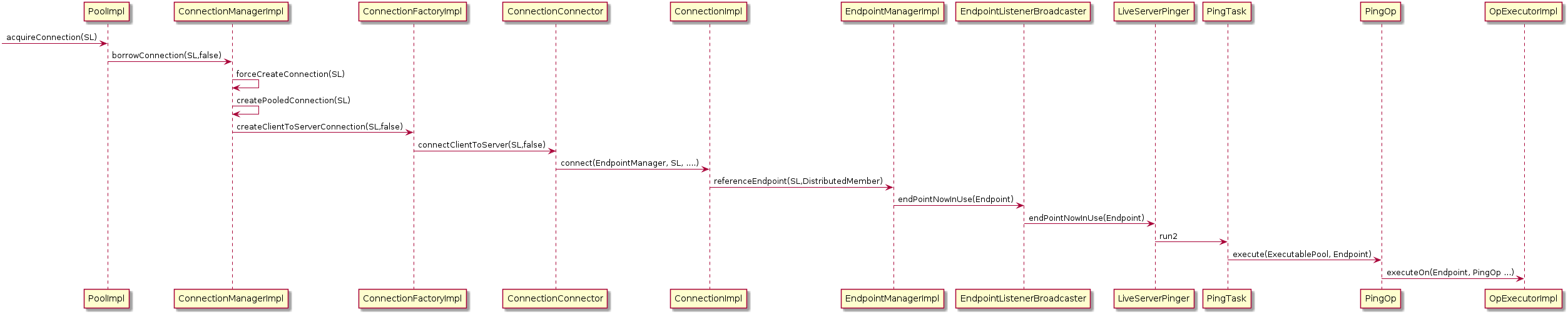
and
Changes and Additions to Public Interfaces
If you are proposing to add or modify public interfaces, those changes should be outlined here in detail.
Performance Impact
Do you anticipate the proposed changes to impact performance in any way? Are there plans to measure and/or mitigate the impact?
Backwards Compatibility and Upgrade Path
Will the regular rolling upgrade process work with these changes?
How do the proposed changes impact backwards-compatibility? Are message or file formats changing?
Is there a need for a deprecation process to provide an upgrade path to users who will need to adjust their applications?
Prior Art
After checking with the dev mailing list, we received the suggestion to configure serverAffinity in Kubernetes to solve the issue with the pings. We tried but
FAQ
Answers to questions you’ve commonly been asked after requesting comments for this proposal.
Errata
, but that option broke the failover of gw senders when a gw receiver is down.
FAQ
TBD
Errata
N/AWhat are minor adjustments that had to be made to the proposal since it was approved?