THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum (Accepted)
Status
Current state: Under DiscussionAccepted
Discussion thread: here
JIRA:
| Jira | ||||||
|---|---|---|---|---|---|---|
|
...
Note that this protocol assumes something like the Kafka v2 log message format. It is not compatible with older formats because records do not include the leader epoch information that is needed for log reconciliation. We have intentionally avoided any make no assumption about the representation of the physical log and its semantics. This format and minimal assumptions about it's logical structure. This makes it usable both for internal metadata replication and (eventually) partition data replication.
...
quorum.voters: This is a connection map which contains the IDs of the voters and their respective endpoint. We use the following format for each voter in the list{broker-id}@{broker-host):{broker-port}. For example, `quorum.voters=1@kafka-1:9092, 2@kafka-2:9092, 3@kafka-3:9092`.quorum.fetch.timeout.ms:Maximum time without a successful fetch from the current leader before a new election is started.quorum.election.timeout.ms:Maximum time without collected a majority of votes during the candidate state before a new election is retried.quorum.election.backoff.max.ms:Maximum exponential backoff time (based on the number if retries) after an election timeout, before a new election is triggered.quorum.request.timeout.ms:Maximum time before a pending request is considered failed and the connection is dropped.quorum.retry.backoff.ms:Initial delay between request retries. This config and the one below is used for retriable request errors or lost connectivity and are different from the election.backoff configs above.quorum.retry.backoff.max.ms: Max delay between requests. Backoff will increase exponentially beginning fromquorum.retry.backoff.ms(the same as in KIP-580).broker.id: The existing broker id config shall be used as the voter id in the Raft quorum.
...
Records are uniquely defined by their offset in the log and the epoch of the leader that appended the record. The key and value schemas will be defined by the controller in a separate KIP; here we treat them as arbitrary byte arrays. However, we do require the ability to append "control records" to the log which are reserved only for use within the Raft quorum (e.g. this enables quorum reassignment).
Kafka's current The v2 message format version supports everything we need, so we will assume thathas all the assumed/required properties already.
Quorum State
We use a separate file to store the current state of the quorum. This is both for convenience and correctness. It helps us to initialize the quorum state after a restart, but we also need it in order to know which broker we have voted for in a given election. The Raft protocol does not allow voters to change their votes, so we have to preserve this state across restarts. Below is the schema for this quorum-state file.
...
Note one key difference of this internal topic compared with other topics is that we should always enforce fsync upon appending to local log to guarantee Raft algorithm correctness, i.e. we are dropping group flushing for this topic. In practice, we could still optimize the fsync latency in the following way: 1) the client requests to the leader are expected to have multiple entries, 2) the fetch response from the leader can contain multiple entries, and 3) the leader can actually defer fsync until it knows "quorum.size majority - 1" has get to a certain entry offset. We will discuss a bit more about these in the following sectionsleave this potential optimization as a future work out of the scope of this KIP design.
Other log-related metadata such as log start offset, recovery point, HWM, etc are still stored in the existing checkpoint file just like any other Kafka topic partitions.
Additionally, we make use of the current meta.properties file, which caches the value from broker.id in the configuration as well as the discovered clusterId. As is the case today, the configured broker.id does not match the cached value, then the broker will refuse to start. If we connect to a cluster with a different clusterId, then the broker will receive a fatal error and shutdown.
...
The key functionalities of any consensus protocol are leader election and data replication. The protocol for these two functionalities consists of 5 four core RPCs:
- Vote: Sent by a voter to initiate an election.
- BeginQuorumEpoch: Used by a new leader to inform the voters of its status.
- EndQuorumEpoch: Used by a leader to gracefully step down and allow a new election.
- Fetch: Sent by voters and observers to the leader in order to replicate the log.
...
- DescribeQuorum: Administrative API to list the replication state (i.e. lag) of the voters. More of the details can also be found in KIP-642: Dynamic quorum reassignment#DescribeQuorum.
Before getting into the details of these APIs, there are a few common attributes worth mentioning upfront:
...
Leader Progress Timeout
In the traditional push-based model, when a leader is disconnected from the quorum due to network partition, it will start a new election to learn the active quorum or form a new one immediately. In the pull-based model, however, say a new leader has been elected with a new epoch and everyone has learned about it except the old leader (e.g. that leader was not in the voters anymore and hence not receiving the BeginQuorumEpoch as well), then that old leader would not be notified by anyone about the new leader / epoch and become a pure "zombie leader", as there is no regular heartbeats being pushed from leader to the follower. This could lead to stale information being served to the observers and clients inside the cluster.
To resolve this issue, we will piggy-back on the "quorum.fetch.timeout.ms" config, such that if the leader did not receive Fetch requests from a majority of the quorum for that amount of time, it would begin a new election and start sending VoteRequest to voter nodes in the cluster to understand the latest quorum. If it couldn't connect to any known voter, the old leader shall keep starting new elections and bump the epoch. And if the returned response includes a newer epoch leader, this zombie leader would step down and becomes a follower. Note that the node will remain a candidate until it finds that it has been supplanted by another voter, or win the election eventually.
As we know from the Raft literature, this approach could generate disruptive voters when network partitions happen on the leader. The partitioned leader will keep increasing its epoch, and when it eventually reconnects to the quorum, it could win the election with a very large epoch number, thus reducing the quorum availability due to extra restoration time. Considering this scenario is rare, we would like to address it in a follow-up KIP.
...
Request Schema
| Code Block |
|---|
{
"apiKey": 51N,
"type": "request",
"name": "BeginQuorumEpochRequest",
"validVersions": "0",
"fields": [
{ "name": "ClusterId", "type": "string", "versions": "0+", "nullableVersions": "0+", "default": "null"},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The ID of the newly elected leader"},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The epoch of the newly elected leader"}
]}
]}
]
} |
...
The EndQuorumEpochRequest will be sent to all voters in the quorum. Inside each request, leader will define the list of preferred successors sorted by each voter's current replicated offset in descending order. Based on the priority of the preferred successors, each voter will choose the corresponding delayed election time so that the most up-to-date voter has a higher chance to be elected. If the node's priority is highest, it will become candidate immediately instead of waiting for next polland not wait for the election timeout. For a successor with priority N > 0, the next election timeout will be computed as:
...
Extra condition on commitment: The Raft protocol requires the leader to only commit entries from any previous epoch if the same leader has already successfully replicated an entry from the current epoch. Kafka's ISR replication protocol suffers from a similar problem and handles it by not advancing the high watermark until the leader is able to write a message with its own epoch. The diagram below taken from the Raft dissertation illustrates the scenario:

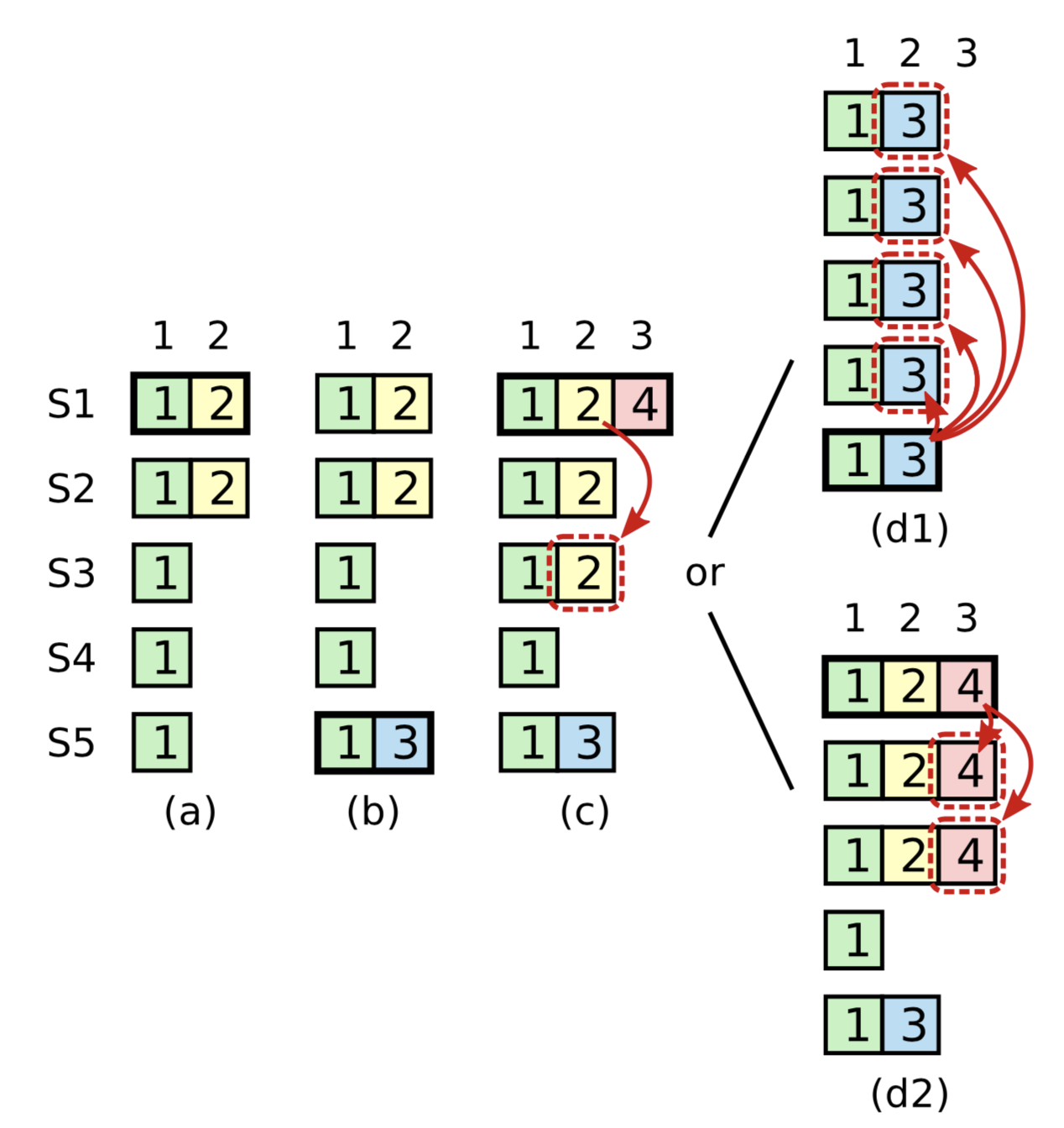
The problem concerns the conditions for commitment and leader election. In this diagram, S1 is the initial leader and writes "2," but fails to commit it to all replicas. The leadership moves to S5 which writes "3," but also fails to commit it. Leadership then returns to S1 which proceeds to attempt to commit "2." Although "2" is successfully written to a majority of the nodes, the risk is that S5 could still become leader, which would lead to the truncation of "2" even though it is present on a majority of nodes.
...
| Code Block |
|---|
{
"apiKey": 1,
"type": "request",
"name": "FetchRequest",
"validVersions": "0-12",
"flexibleVersions": "12+",
"fields": [
// ---------- Start new field ----------
{ "name": "ClusterId", "type": "string", "versions" "12+", "nullableVersions": "12+", "default": "null", "taggedVersions": "12+", "tag": 10,
"about": "The clusterId if known. This is used to validate metadata fetches prior to broker registration." },
// ---------- End new field ----------
{ "name": "ReplicaId", "type": "int32", "versions": "0+",
"about": "The broker ID of the follower, of -1 if this request is from a consumer." },
{ "name": "MaxWaitTimeMs", "type": "int32", "versions": "0+",
"about": "The maximum time in milliseconds to wait for the response." },
{ "name": "MinBytes", "type": "int32", "versions": "0+",
"about": "The minimum bytes to accumulate in the response." },
{ "name": "MaxBytes", "type": "int32", "versions": "3+", "default": "0x7fffffff", "ignorable": true,
"about": "The maximum bytes to fetch. See KIP-74 for cases where this limit may not be honored." },
{ "name": "IsolationLevel", "type": "int8", "versions": "4+", "default": "0", "ignorable": false,
"about": "This setting controls the visibility of transactional records. Using READ_UNCOMMITTED (isolation_level = 0) makes all records visible. With READ_COMMITTED (isolation_level = 1), non-transactional and COMMITTED transactional records are visible. To be more concrete, READ_COMMITTED returns all data from offsets smaller than the current LSO (last stable offset), and enables the inclusion of the list of aborted transactions in the result, which allows consumers to discard ABORTED transactional records" },
{ "name": "SessionId", "type": "int32", "versions": "7+", "default": "0", "ignorable": false,
"about": "The fetch session ID." },
{ "name": "SessionEpoch", "type": "int32", "versions": "7+", "default": "-1", "ignorable": false,
"about": "The fetch session epoch, which is used for ordering requests in a session" },
{ "name": "Topics", "type": "[]FetchableTopic", "versions": "0+",
"about": "The topics to fetch.", "fields": [
{ "name": "Name", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The name of the topic to fetch." },
{ "name": "FetchPartitions", "type": "[]FetchPartition", "versions": "0+",
"about": "The partitions to fetch.", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "CurrentLeaderEpoch", "type": "int32", "versions": "9+", "default": "-1", "ignorable": true,
"about": "The current leader epoch of the partition." },
{ "name": "FetchOffset", "type": "int64", "versions": "0+",
"about": "The message offset." },
// ---------- Start new field ----------
{ "name": "FetchEpochLastFetchedEpoch", "type": "int32", "versions": "12+", "default": "-1", "taggedVersions": "12+", "tag": 20,
"about": "The epoch of the last replicated record"},
// ---------- End new field ----------
{ "name": "LogStartOffset", "type": "int64", "versions": "5+", "default": "-1", "ignorable": false,
"about": "The earliest available offset of the follower replica. The field is only used when the request is sent by the follower."},
{ "name": "MaxBytes", "type": "int32", "versions": "0+",
"about": "The maximum bytes to fetch from this partition. See KIP-74 for cases where this limit may not be honored." }
]}
]},
{ "name": "Forgotten", "type": "[]ForgottenTopic", "versions": "7+", "ignorable": false,
"about": "In an incremental fetch request, the partitions to remove.", "fields": [
{ "name": "Name", "type": "string", "versions": "7+", "entityType": "topicName",
"about": "The partition name." },
{ "name": "ForgottenPartitionIndexes", "type": "[]int32", "versions": "7+",
"about": "The partitions indexes to forget." }
]},
{ "name": "RackId", "type": "string", "versions": "11+", "default": "", "ignorable": true,
"about": "Rack ID of the consumer making this request"}
]
} |
...
| Code Block |
|---|
{
"apiKey": 1,
"type": "response",
"name": "FetchResponse",
"validVersions": "0-12",
"flexibleVersions": "12+",
"fields": [
{ "name": "ThrottleTimeMs", "type": "int32", "versions": "1+", "ignorable": true,
"about": "The duration in milliseconds for which the request was throttled due to a quota violation, or zero if the request did not violate any quota." },
{ "name": "ErrorCode", "type": "int16", "versions": "7+", "ignorable": false,
"about": "The top level response error code." },
{ "name": "SessionId", "type": "int32", "versions": "7+", "default": "0", "ignorable": false,
"about": "The fetch session ID, or 0 if this is not part of a fetch session." },
{ "name": "Topics", "type": "[]FetchableTopicResponse", "versions": "0+",
"about": "The response topics.", "fields": [
{ "name": "Name", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]FetchablePartitionResponse", "versions": "0+",
"about": "The topic partitions.", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "ErrorCode", "type": "int16", "versions": "0+",
"about": "The error code, or 0 if there was no fetch error." },
{ "name": "HighWatermark", "type": "int64", "versions": "0+",
"about": "The current high water mark." },
{ "name": "LastStableOffset", "type": "int64", "versions": "4+", "default": "-1", "ignorable": true,
"about": "The last stable offset (or LSO) of the partition. This is the last offset such that the state of all transactional records prior to this offset have been decided (ABORTED or COMMITTED)" },
{ "name": "LogStartOffset", "type": "int64", "versions": "5+", "default": "-1", "ignorable": true,
"about": "The current log start offset." },
// ---------- Start new field ----------
{ "name": "NextOffsetAndEpochDivergingEpoch", "type": "OffsetAndEpochEpochEndOffset",
"versions": "12+", "taggedVersions": "12+", "tag": 0, "fields": [
{ "nameabout": "NextFetchOffset", "type": "int64", "versions": "0+",
"about": "If set, this is the offset that the follower should truncate to"}In case divergence is detected based on the `LastFetchedEpoch` and `FetchOffset` in the request, this field indicates the largest epoch and its end offset such that subsequent records are known to diverge",
{ "namefields": "NextFetchOffsetEpoch", "[
{ "name": "Epoch", "type": "int32", "versions": "012+", "default": "-1" },
{ "aboutname": "EndOffset"The epoch of the next offset in case the follower needs to truncate"}, , "type": "int64", "versions": "12+", "default": "-1" }
]},
{ "name": "CurrentLeader", "type": "LeaderIdAndEpoch",
"versions": "12+", "taggedVersions": "12+", "tag": 1, fields": [
{ "name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The ID of the current leader or -1 if the leader is unknown."},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The latest known leader epoch"}
]},
// ---------- End new field ----------
{ "name": "Aborted", "type": "[]AbortedTransaction", "versions": "4+", "nullableVersions": "4+", "ignorable": false,
"about": "The aborted transactions.", "fields": [
{ "name": "ProducerId", "type": "int64", "versions": "4+", "entityType": "producerId",
"about": "The producer id associated with the aborted transaction." },
{ "name": "FirstOffset", "type": "int64", "versions": "4+",
"about": "The first offset in the aborted transaction." }
]},
{ "name": "PreferredReadReplica", "type": "int32", "versions": "11+", "ignorable": true,
"about": "The preferred read replica for the consumer to use on its next fetch request"},
{ "name": "Records", "type": "bytes", "versions": "0+", "nullableVersions": "0+",
"about": "The record data." }
]}
]}
]
} |
...
- Check that the clusterId if not null matches the cached value in
meta.properties. - First ensure that the leader epoch from the request is the same as the locally cached value. If not, reject this request with either the FENCED_LEADER_EPOCH or UNKNOWN_LEADER_EPOCH error.
- If the leader epoch is smaller, then eventually this leader's BeginQuorumEpoch would reach the voter and that voter would update the epoch.
- If the leader epoch is larger, then eventually the receiver would learn about the new epoch anyways. Actually this case should not happen since, unlike the normal partition replication protocol, leaders are always the first to discover that they have been elected.
- Check that the epoch on the
FetchOffset's FetchEpochareLastFetchedEpochis consistent with the leader's log. Specifically we check thatFetchOffsetis less than or equal to the end offset ofFetchEpoch. If not, return OUT_OF_RANGE and encode the nextFetchOffsetas the last offset of the The leader assumes that theLastFetchedEpochis the epoch of the offset prior toFetchOffset. FetchOffsetis expected to be in the range of offsets with an epoch ofLastFetchedEpochor it is the start offset of the next epoch in the log. If not, return a empty response (no records included in the response) and set theDivergingEpochto the largest epoch which is less than or equal to the fetcher's epochLastFetchedEpoch. This is a heuristic of truncating an optimization to truncation to let the voter follower truncate as much as possible to get to the starting - divergence point with fewer Fetch round-trips: if . For example, If the fetcher's last epoch is X which does not match the epoch of that the offset prior to the fetching offset, then it means that all the records of with epoch X on that voter the follower may have diverged and hence could be truncated, then returning the next offset of largest epoch Y (< X) is reasonable. - If the request is from a voter not an observer, the leader can possibly advance the high-watermark. As stated above, we only advance the high-watermark if the current leader has replicated at least one entry to majority of quorum to its current epoch. Otherwise, the high watermark is set to the maximum offset which has been replicated to a majority of the voters.
...
- If the response contains FENCED_LEADER_EPOCH error code, check the
leaderIdfrom the response. If it is defined, then update thequorum-statefile and become a "follower" (may or may not have voting power) of that leader. Otherwise, retry to theFetchrequest again against one of the remaining voters at random; in the mean time it may receive BeginQuorumEpoch request which would also update the new epoch / leader as well. - If the response contains OUT_OF_RANGE error code, truncate its local log to the encoded nextFetchOffset, and then resend the
FetchRecordrequest.has the fieldDivergingEpochset, then truncate from the log all of the offsets greater than or equal toDivergingEpoch.EndOffsetand truncate any offset with an epoch greater thanDivergingEpoch.EndOffset.
Note that followers will have to check any records received for the presence of control records. Specifically a follower/observer must check for voter assignment messages which could change its role.
...
The DescribeQuorum API is used by the admin client to show the status of the quorum. This includes showing the progress of a quorum reassignment and viewing the lag of followers and observers.Note that this API must be sent to the leader, which is the only node that would have lag information for all of the voters.
Request Schema
| Code Block |
|---|
{
"apiKey": N,
"type": "request",
"name": "DescribeQuorumRequest",
"validVersions": "0",
"flexibleVersions": "0+",
"fields": [
{ { "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ { "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ { "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ { "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." }
]
}]
}
]
} |
Response Schema
| Code Block |
|---|
{
"apiKey": N,
"type": "response",
"name": "DescribeQuorumResponse",
"validVersions": "0",
"flexibleVersions": "0+",
"fields": [
{ { "name": "ErrorCode", "type": "int16", "versions": "0+",
"about": "The top level error code."},
{ { "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ { "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ { "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ { "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ { "name": "ErrorCode", "type": "int16", "versions": "0+"},
{ { "name": "LeaderId", "type": "int32", "versions": "0+",
"about": "The ID of the current leader or -1 if the leader is unknown."},
{ { "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The latest known leader epoch"},
{ { "name": "HighWatermark", "type": "int64", "versions": "0+"},
{ { "name": "CurrentVoters", "type": "[]ReplicaState", "versions": "0+" },
{ { "name": "TargetVotersObservers", "type": "[]ReplicaState", "versions": "0+" },
{ "name": "Observers", "type": "[]ReplicaState", }
]}
]}],
"commonStructs": [
{ "name": "ReplicaState", "versions": "0+", "fields": }
]}
]}],
"commonStructs": [
{ "name": "ReplicaState", "versions": "0+", "fields": [
{ "name": "ReplicaId", [
{ "name": "ReplicaId", "type": "int32", "versions": "0+"},
{ { "name": "LogEndOffset", "type": "int64", "versions": "0+",
"about": "The last known log end offset of the follower or -1 if it is unknown"}
]}
]
} |
DescribeQuorum Request Handling
This request is always sent to the leader node. We expect AdminClient to use the Metadata API in order to discover the current leader. Upon receiving the request, a node will do the following:
- First check whether the node is the leader. If not, then return an error to let the client retry with Metadata. If the current leader is known to the receiving node, then include the
LeaderIdandLeaderEpochin the response. - Build the response using current assignment information and cached state about replication progress.
...
- If the response indicates that the intended node is not the current leader, then check the response to see if the
LeaderIdhas been set. If so, then attempt to retry the request with the new leader. - If the current leader is not defined in the response (which could be the case if there is an election in progress), then backoff and retry with
Metadata. - Otherwise the response can be returned to the application, or the request eventually times out.
...
There will be two options available with -- describe :
describe --describe status: a short summary of the quorum status and the other provides detailed information about the status of replication.describe --describereplication: provides detailed information about the status of replication
...
| Code Block |
|---|
> bin/kafka-metadata-quorum.sh describe --describestatus LeaderId: 0 LeaderEpoch: ClusterId: SomeClusterId LeaderId: 0 LeaderEpoch: 15 HighWatermark: 234130 MaxFollowerLag: 34 MaxFollowerLagTimeMs: 15 CurrentVoters: [0, 1, 2] > bin/kafka-metadata-quorum.sh describe --describe replication ReplicaId LogEndOffset Lag LagTimeMs Status 0 234134 0 0 Leader 1 234130 4 10 Follower 2 234100 34 15 Follower 3 234124 10 12 Observer 4 234130 4 15 Observer |
...
Here’s a list of proposed metrics for this new protocol:
NAME | TAGS | TYPE | NOTE | ||||||
CurrentLeadercurrent-leader | type=raft-manager | dynamic gauge | -1 means UNKNOWN | ||||||
|---|---|---|---|---|---|---|---|---|---|
CurrentEpochcurrent-epoch | type=raft-manager | dynamic gauge | 0 means UNKNOWN | ||||||
CurrentVotecurrent-vote | type=raft-manager | dynamic gauge | -1 means not voted for anyone | ||||||
LogEndOffsetlog-end-offset | type=raft-manager | dynamic gauge | |||||||
LogEndEpochlog-end-epoch | type=raft-manager | dynamic gauge | |||||||
BootTimestamphigh-watermark | type=raft-manager | dynamic gauge | |||||||
Statecurrent-state | type=raft-manager | dynamic enum | possible values: "leader", "follower", "candidate", "observer" | ||||||
NumQuorumVotersnumber-unknown-voter-connections | type=raft-manager | dynamic gauge | number of cached voter connectionsunknown voters whose connection information is not cached; would never be larger than quorum-size | ||||||
ElectionLatencyMax/Avgelection-latency-max/avg | type=raft-manager | dynamic gauge | measured on each voter as windowed sum / avg, start when becoming a candidate and end on learned or become the new leader | ||||||
ReplicationLatencyMax/Avgcommit-latency-max/avg | type=raft-manager | dynamic gauge | measured on leader as windowed sum / avg, start when appending the record and end on hwm advanced beyond | ||||||
InboundRequestPerSecfetch-records-rate | type=raft-manager, source-broker-id=[broker-id] | windowed rate | one per source | apply to follower and observer only | |||||
append-records-rateOutboundRequestPerSec | type=raft-manager, destination-broker-id=[broker-id] | windowed rate | one per destination | InboundChannelSize | type=raft-manager | windowed average | OutboundChannelSize | type=raft-manager | windowed average |
FetchRecordsPerSec | type=raft-manager | windowed rate | apply to follower and observer only | ||||||
AppendRecordsPerSec | type=raft-manager | windowed rate | apply to leader only | ||||||
ErrorResponsePerSec | type=raft-manager, destination-broker-id=[broker-id] | windowed rate | one per destination | ||||||
TotalTimeMs | type=raft-manager, request=[request-type] | windowed average | one per inbound request type | ||||||
InboundQueueTimeMs | type=raft-manager, request=[request-type] | windowed average | one per inbound request type | ||||||
HandleTimeMs | type=raft-manager, request=[request-type] | windowed average | one per inbound request type | ||||||
OutboundQueueTimeMs | type=raft-manager, request=[request-type] | windowed average | one per inbound request type | ||||||
windowed rate | apply to leader only | ||||||||
poll-idle-ratio-avgAvgIdlePercent | type=raft-manager | windowed average |
...