THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
| Excerpt |
|---|
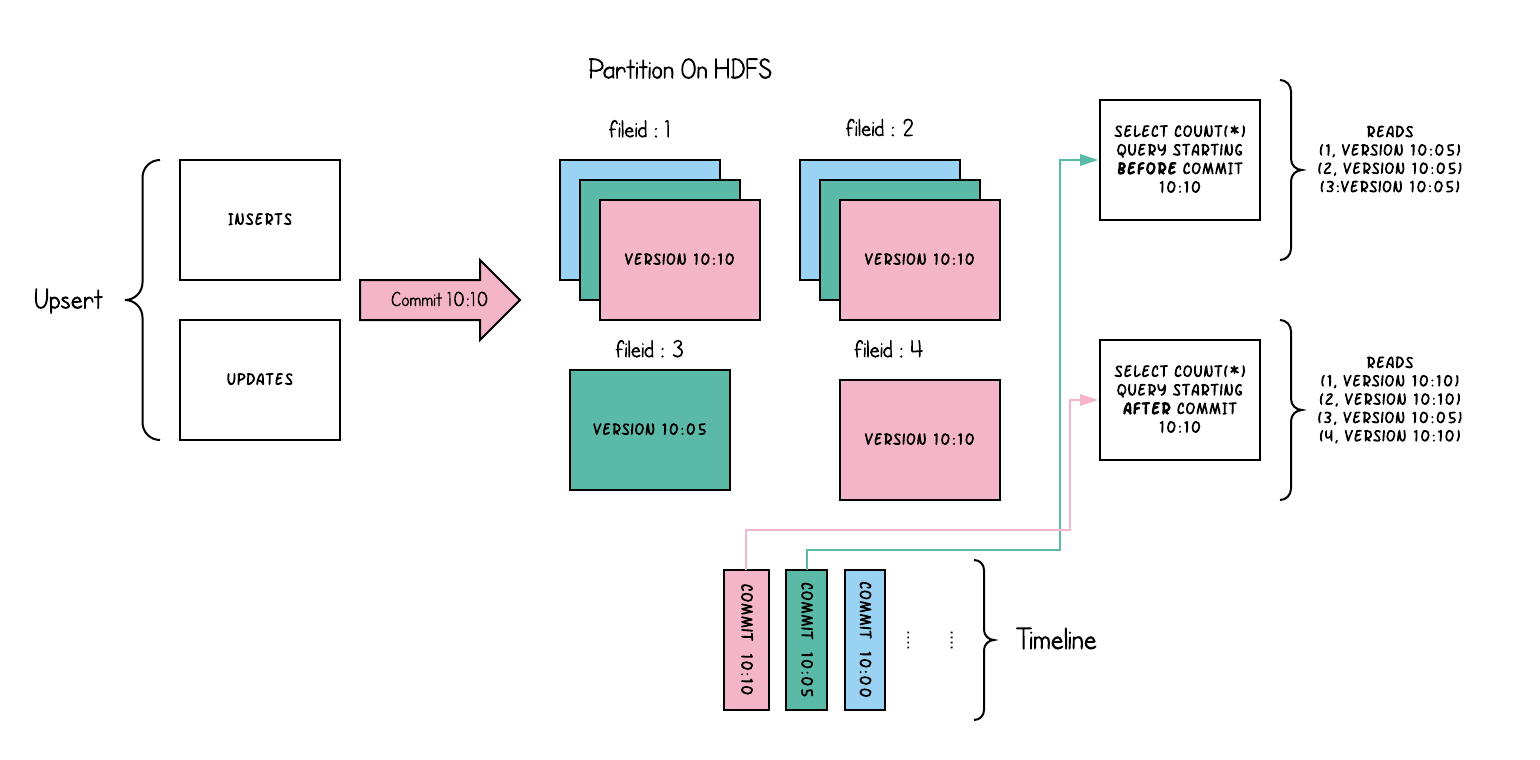
A def~table-type where a def~table's def~commits are fully merged into def~table during a def~write-operation. This can be seen as "imperative ingestion", "compaction" of the happens right away. No def~log-files are written and def~file-slices contain only def~base-file. (e.g a single parquet file constitutes one file slice) The Spark DAG for this storage, is relatively simpler. The key goal here is to group the tagged Hudi record RDD, into a series of updates and inserts, by using a partitioner. To achieve the goals of maintaining file sizes, we first sample the input to obtain a workload profile that understands the spread of inserts vs updates, their distribution among the partitions etc. With this information, we bin-pack the records such that
Any remaining records after that, are again packed into new file id groups, again meeting the size requirements. |