THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
Once the group members have been stabilized by the completion of phase 1, the active leader has the option to must propagate additional state to the other members in the group members. This is used in the new consumer protocol to set partition assignments. Just like the JoinGroup phase, this synchronization acts as a barrier which all members must acknowledge by sending their own SyncGroup requestsSimilar to phase 1, all members send SyncGroup requests to the coordinator. Once group state has been provided by the leader, the coordinator forwards each member's state respectively in the SyncGroup response. The message format is provided below:
| Code Block |
|---|
SyncGroupRequest => GroupId GroupGenerationId MemberId
GroupId => String
GroupGenerationId => int32
SyncErrorCode => int16
GroupState => [MemberId MemberState]
MemberId => String
MemberState => bytes
SyncGroupResponse => ErrorCode GroupGenerationId MemberState
ErrorCode => int16
GroupGenerationIdMemberState => int32
MemberState => bytes |
The leader sets member states in the GroupState field. For followers, this array must be empty. Once the coordinator has received the group state from the leader, and all members have sent their SyncGroup requests, the coordinator unpacks the group state and responds with it can unpack each member's respective state and send it in the MemberState field of the SyncGroup response.
Failure Cases: There are several failure cases to consider in this phase of the protocol:
- The leader can fail prior to performing an expected synchronization. In this case, the session timeout of the leader will expire and the coordinator will mark it dead and force all members to rejoin the group, which will result in new leader being elected.
- The leader's synchronization procedure can fail. For example, if the leader cannot parse one member's metadata, then the state synchronization should generally fail. Since this is most likely a non-recoverable error, there must be some way to propagate the error to all members of the group. The SyncGroup request contains an error field which is used for this purpose. All members will send SyncGroup requests as before, only this time once all members have joined, the error code will be forwarded in the SyncGroup response. The client can then propagate the error to the user.
- Followers can fail to join the synchronization barrier. If a follower fails to send an expected SyncGroup, then the member's sessionId will expire which will force members to rejoin.
- New members can join during synchronization. If a new member sends a JoinGroup during this phase, then the synchronization round will fail with an error indicating that rejoining the group is necessary.
A couple additional points are worth noting in this phase:
...
Coordinator State Machine
The coordinator maintains a state machine for each group with the following states:
- Down: There are no active members and group state has been cleaned up.
- Initialize: In this state, the coordinator reads group data from Zookeeper (or some other storage) in order to transition groups from failed coordinators. Any heartbeat or join group requests are returned with an error indicating that the coordinator is not ready yet.
- Stable: In this state, the coordinator either has an active generation or has no members and is awaiting the first JoinGroup. Heartbeats are accepted from members in this state and are used to keep group members active or to indicate that they need to join the group.
- Joining: The coordinator has received a JoinGroup request from at least one member and is awaiting JoinGroup requests from the rest of the group. Heartbeats or SyncGroup requests in this state return an error indicating that a rebalance is in progress.
- AwaitingSync: The join group phase has completed (i.e. all expected members of the group have sent JoinGroup requests) and the coordinator is awaiting group state from the leader. Unexpected coordinator requests return an error indicating that a rebalance is in progress.
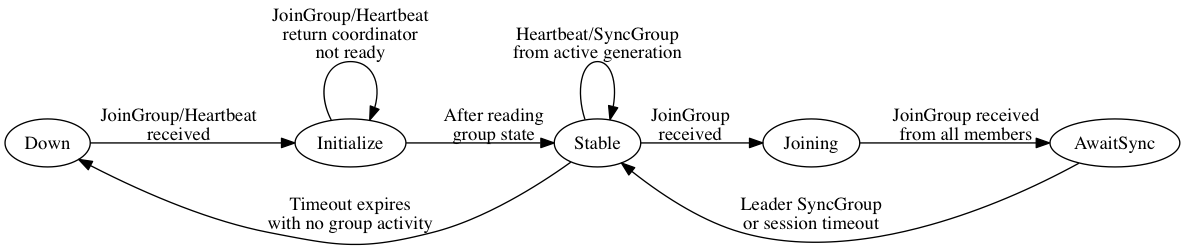
Note that the generation is incremented on successful completion of the first phase (Joining). Before this phase completes, the old generation has an opportunity to do any necessary cleanup work (such as commit offsets in the case of the new consumer). Upon transition to the AwaitSync state, the coordinator begins a timer for each member according to their respective session timeouts. If the timeout expires for any member, then the coordinator must trigger a rebalance.
The group leader is responsible for synchronizing state for the group upon completion of the Joining state. If the leader's session timeout expires before the coordinator has received the leader's SyncGroup, then the generation becomes invalid and the members must rejoin. It is also possible for the leader to transmit an error in the SyncGroup request. In this case also, the generation becomes invalid and the error can be propagated to the other members of the group.
Note that the transition from AwaitSync to Stable occurs only when the leader's SyncGroup has been received. It is possible that the SyncGroup from followers may therefore arrive either in the AwaitSync state or in the Stable state. If the former, then the coordinator will park the request until the SyncGroup from the leader has been received (or its timeout has expired). If the latter, then the coordinator can respond to the SyncGroup request immediately using the leader's synchronized state. Clearly this requires the coordinator to store this state at least for the duration of the max session timeout in the group. It is also be possible that the member fails before collecting its state: in this case, the member's session timeout will expire and the group will rebalance.
Consumer Embedded Protocol
Above we outlined the generalized JoinGroup protocol that the consumer will use. Next we show how we will implement consumer semantics on top of this protocol. Other use cases for the join group protocol would be implemented similarly.
The two phases of the group protocol correspond to subscription and assignment for the new consumer. Each member of the group submits their subscription as member metadata. The leader of the group collects the subscriptions of the group using DescribeGroup and all subscription in its JoinGroup response and sends the assignment as member state in SyncGroup. There are several advantages to having a single assignor:
- Since the leader makes the assignment for the full group, it is the single source of truth for the metadata used in its decision making. This avoids the need to synchronize metadata among all members that is required in a multi-assignor approach.
- The leader of the group can enforce its own policy for controlling the rate of rebalancing. It doesn't have to rebalance after every metadata change, but can "batch" changes together to reduce the impact of metadata churn.
- Once the members of the group are stable, rebalances should only require the SyncGroup round, which requires just a single round trip to the broker for all members.
- The leader is the only member that needs to receive the metadata from all members of the group. This reduces the overhead of the protocol.
The two items that must be defined to use the join group protocol is the format of the member metadata provided in JoinGroup, and the member state provided in SyncGroup. Group members provide their subscription as a String an array of strings in the member metadata of the JoinGroup JoinGroup request. This subscription can either be a comma-separated list of topics or a regular expression expressions (TODO: do we need distinguisher field to tell the difference? how about regex compatibility?). Partition assignments are provided as an array of topics and partitions in the SyncGroup phase. Each consumer provides a list of the assignment strategies that they support. When the group's leader collects the subscriptions from all members, it must find an assignment strategy which all members support. If none can be found, then the SyncGroup phase will fail with an error as described above.
| Code Block |
|---|
MemberMetadata => Version Subscription AssignmentStrategies Version => int16 Subscription => [String] AssignmentStrategies => [String] MemberState => Version Assignment Version => int16 Assignment => [Topic Partitions] Topic => String Partitions => [int32] |
Protocol: Briefly, this is how the protocol works for the consumer.
- Members JoinGroup with their respective subscriptions.
- Once joined, the leader uses DescribeGroup to collect member subscriptions and set the group's assignment in SyncGroup.
- All members SyncGroup to find their assignment.
- Once created, there are two cases which can trigger reassignment:
- Topic metadata changes which have no impact on subscriptions cause resync. The leader computes the new assignment and sends SyncGroup.
- Membership or subscription changes cause rejoin.
Rolling Upgrades: To support rolling upgrades without downtime, there are two cases to consider:
- Changes affecting subscription: the protocol directly supports differing subscriptions, so there is no need for special handling. Members will only be assigned partitions compatible with their subscription.
- Assignment strategy changes: to support a change to the assignment strategy, new versions must enable support both for the old assignment strategy and the new one. When the group leader collects the metadata for the group, it will only choose an assignment strategy which is compatible with all members. Once all members are updated, the leader will choose strategy in the order listed.
Handling Coordinator Failures: This proposal largely shares the coordinator failure cases and recovery mechanism from the initial protocol documented in Kafka 0.9 Consumer Rewrite Design. The recovery process depends on whether group state is persisted (e.g. in Zookeeper). With no persistence, then group members will generally have to rejoin the group when the new coordinator becomes active. Below, we assume persistence and show how failures are treated at the various stages of the protocol.
- All members send JoinGroup.
- Generation metadata is persisted.
- All members send SyncGroup.
- Sync metadata is persisted.
Coordinator failures at these steps are handled in the following ways:
- If the coordinator fails before all members have joined the group or before group metadata has been persisted, then all members will resend their JoinGroup requests once the new coordinator is stable.
- The coordinator may fail after group metadata has been persisted, but before all members of the group have received a response to their JoinGroup requests. The problem here is that once the new coordinator is stable, the leader may try to immediately synchronize while other members are still trying to join. However, when the coordinator receives a JoinGroup request from any member, it must abort any active synchronization and force all members to rejoin.
- If the coordinator fails before a pending synchronization has been persisted, then all members will re-initiate the SyncGroup once the new coordinator is ready.
- If the coordinator fails after the metadata has been persisted, but before all members have received the SyncGroup response, then those members will initiate SyncGroup upon failover. Assuming synchronized state is persisted, then the coordinator can return that member's state immediately without forcing other members to resync. If it is not persisted, then a full group resync is required.
Other Interesting Cases:
- Leader Failures: The leader of each group is responsible for initiating group synchronization when topic metadata changes. A leader failure is detected by the coordinator through the expiration of its session timeout. The coordinator will respond by forcing all members to rejoin, which will allow a new leader to be elected.
- Assignment Failure: As mentioned above, there are several ways that the synchronization/assignment phase can fail. Generally, they are handled by having group members rejoin the group. The most interesting case is when the leader encounters an unrecoverable error when it computes the group's assignment. This could happen, for example, if group members don't agree on the assignment strategy to use. In this case, the assignment failure is forwarded to the broker which can then propagate it to awaiting members.
- Subscription Change: If a member changes its subscription, then it must force the group to be recreated by sending a JoinGroup request to the coordinator. This will cause the coordinator to reply to the other member's heartbeats with an error indicating that rejoin is needed, which will cause them to also send JoinGroup requests.
- Topic Metadata Change: The leader is responsible for detecting topic metadata changes which affect the group's subscription. When it finds a change, it can immediately compute the new assignment and initiate a SyncGroup with the coordinator.
KafkaConsumer API
Although the protocol is slightly more complex for the KafkaConsumer implementation, most of the details are hidden from users. Below we show the basic assignment interface that would be exposed in KafkaConsumer. The partition assigner is generic to allow for custom metadata. For simple versions, the generic type would probably be Void.
| Code Block |
|---|
class ConsumerMetadata<T> {
String consumerId;
List<String> subscribedTopics;
T metadata;
}
interface PartitionAssigner<T> extends Configurable {
/**
* Derive the metadata to be used for the local member by this assigner. This could
* come from configuration or it could be derived dynamically (e.g. for host information
* such as the hostname or number of cpus).
* @return The metadata
*/
public T metadata();
/**
* Assign partitions for this consumer.
* @param consumerId The consumer id of this consumer
* @param partitionsPerTopic The count of partitions for each subscribed topic
* @param consumers Metadata for consumers in the current generation
*/
Map<String, List<TopicPartition>> assign(String consumerId,
Map<String, Integer> partitionsPerTopic,
List<ConsumerMetadata<T>> consumers);
} |
TODO:
To support client-side assignment, we'd have to make the following changes:
- Migrate existing assignment strategies from the broker to the client. Since the assignment interface is nearly the same, this should be straightforward.
- Modify client/server for the new join group protocol. Since we're not really changing the protocol (just the information that is passed through it), this should also be straightforward.
- Remove offset validation from the consumer coordinator. Just a couple lines to remove for this.
- Add support for assignment versioning (if we decide we need it). Depending on what we do, may or may not be trivial.