THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
| Table of Contents |
|---|
This page is meant as a template for writing a KIP. To create a KIP choose Tools->Copy on this page and modify with your content and replace the heading with the next KIP number and a description of your issue. Replace anything in italics with your own description.
Status
Current state: [One of "Under Discussion", "Accepted", "Rejected"]
Discussion thread: here
JIRA: here
Released: <Kafka Version>
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
...
Describe the problems you are trying to solve.
Public Interfaces
Briefly list any new interfaces that will be introduced as part of this proposal or any existing interfaces that will be removed or changed. The purpose of this section is to concisely call out the public contract that will come along with this feature.
A public interface is any change to the following:
Binary log format
The network protocol and api behavior
Any class in the public packages under clientsConfiguration, especially client configuration
org/apache/kafka/common/serialization
org/apache/kafka/common
org/apache/kafka/common/errors
org/apache/kafka/clients/producer
org/apache/kafka/clients/consumer (eventually, once stable)
Monitoring
Command line tools and arguments
- Anything else that will likely break existing users in some way when they upgrade
Proposed Changes
Describe the new thing you want to do in appropriate detail. This may be fairly extensive and have large subsections of its own. Or it may be a few sentences. Use judgement based on the scope of the change.
Compatibility, Deprecation, and Migration Plan
- What impact (if any) will there be on existing users?
- If we are changing behavior how will we phase out the older behavior?
- If we need special migration tools, describe them here.
- When will we remove the existing behavior?
Test Plan
Describe in few sentences how the KIP will be tested. We are mostly interested in system tests (since unit-tests are specific to implementation details). How will we know that the implementation works as expected? How will we know nothing broke?
Rejected Alternatives
...
Many stream processing applications need to maintain state across a period of time. Online services, for example, like to understand the behaviour of a typical user. In order to understand this behaviour, the interactions a user has with their website, or streaming service, are grouped together into sessions.
Sessions usually represent some period of user activity separated by a defined gap of inactivity. As events are processed they may create new sessions or be merged into existing sessions. Any sessions that are merged will usually extend the time window the session covers. Thus, session windows are dynamic in nature, i.e, they don’t fit into fixed and aligned time windows, but rather are varying-sized time windows that can't be pre-computed and are driven by timestamps of the data.
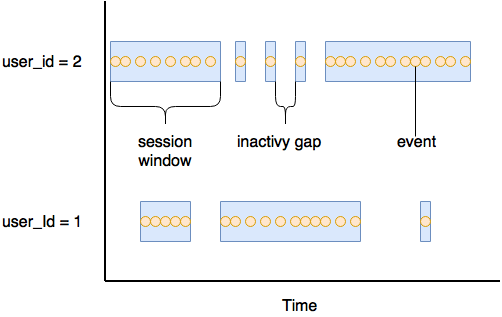
Proposed Changes
We will provide a way for developers using the DSL to specify that they want an aggregation to be aggregated into SessionWindows. Three overloaded methods will be added to KGroupedStream:
| Code Block | ||
|---|---|---|
| ||
KTable<Windowed<K>, V> reduce(final Reducer<V> reducer,
final SessionWindows sessionWindows,
final String storeName);
<T> KTable<Windowed<K>, T> aggregate(final Initializer<T> initializer,
final Aggregator<K, V, T> aggregator,
final SessionMerger<K, T> sessionMerger,
final SessionWindows sessionWindows,
final Serde<T> aggValueSerde,
final String storeName);
KTable<Windowed<K>, Long> count(final SessionWindows sessionWindows, final String storeName); |
A typical aggregation might look like:
| Code Block |
|---|
stream.groupByKey().aggregate(initializer,
aggregator,
merger,
SessionWindows.inactivityGap(FIVE_MINUTES)
.until(ONE_HOUR),
aggregateValueSerde,
“session-store”); |
The above statement will aggregate the results into SessionWindows with an inactivity gap of five minutes. The Sessions will be retained for one hour from when they have closed, during which they will accept input from late-arriving records that would be considered as falling into a particular session.
In order to process SessionWindows we’ll need to add a new Processor. This will be responsible for creating sessions, merging existing sessions into sessions with larger windows, and producing aggregates from a session’s values.
On each incoming record the process method will:
Find any existing sessions that fall within the inactivity gap, i,e., sessionStore.fetch(userKey, timestamp - gap, timestamp + gap).
Merge any existing sessions into a new larger session using the SessionMerger to merge the aggregates of the existing sessions.
Aggregate the value record being processed with the merged session.
Remove any merged sessions from the SessionStore
Store the new merged session in the SessionStore.
We will leverage the work done in KIP-63 for forwarding the aggregated result of a SessionWindow. That is, the aggregates will be de-duplicated in the cache and only be forwarded downstream on commit, flush, or evict. This is inline with how all existing aggregations work in Kafka Streams.
Late arriving data
Late arriving data is mostly treated the same as non-late arriving data, i.e., it can create a new session or be merged into an existing one. The only difference is that if the data has arrived after the retention period, defined by SessionWindows.until(..), it will be silently dropped.
SessionWindows
We propose to add a new class SessionWindows. SessionWindows will be able to be used with new overloaded operations on KGroupedStream, i.e, aggregate(…), count(..), reduce(…). A SessionWindows will have a defined gap, that represents the period of inactivity. It will also provide a method to specify how long the data in the SessionWindow is maintained for, i.e., to allow for late arriving data.
SessionStore
We propose to add a new type of StateStore, SessionStore. A SessionStore, is a segmented store, similar to a WindowStore, but the segments are indexed by session end time. We index by end time so that we can expire (remove) the Segments containing sessions where session endTime < stream-time - retention-period.
The records in the SessionStore will be stored by a SessionKey. The SessionKey is a composite of the record key, window start, and window end times. The start and end times of the SessionKey are driven by the data. If the Session only has a single value then start == end. The segment a Session is stored in is determined by SessionKey.end. Fetch requests against the SessionStore use both the SessionKey.start and Session.end to find sessions to merge.
Each Segment is for a particular interval of time. To work out which Segment a session belongs in we simply divide SessionKey.end by the Segment interval. The Segment interval is calculated as Math.max(retentionPeriod / (numSegments - 1), MIN_SEGMENT_INTERVAL).
For example, given a segment interval of 1000:
| SessionKey End | Segment Index |
|---|---|
| 0 | 0 |
| 500 | 0 |
| 1000 | 1 |
| 2000 | 2 |
Put
As session aggregates arrive, i.e., on put, the implementation of SessionStore will:
use SessionKey.end to get or create the Segment to store the aggregate in
If the Segment is non-null, we add the aggregate to the segment.
If the Segment was null, this signals that the record is late and has arrived after the retention period. This record is dropped.
Fetch
When SessionStore.fetch(..) is called we find all the session aggregates for the record key where SessionKey.end >= earliestEndTime && SessionKey.start <= latestStartTime. In order to do this:
Find the Segments to search by getting all Segments starting from earliestEndTime
Define the range query as:
from = (record-key, end=earliestEndTime, start=0)
to = (record-key, end=Long.MAX_VALUE, start=Long.MAX_VALUE)
Provide a condition on the iterator such that it stops once a record with start > latestStartTime is found.
For example, if for an arbitrary record key we had the following sessions in the store:
| Session Start | Session End |
|---|---|
| 0 | 99 |
| 101 | 200 |
| 201 | 300 |
| 301 | 400 |
When we query the store with earliestEndTime = 150, latestStartTime = 300 we would retrieve sessions starting at 101 and 201.
Public Interfaces
| Code Block | ||
|---|---|---|
| ||
public class SessionWindows {
/**
* Create a new SessionWindows with the specified inactivityGap
*
* @param inactivityGap
* @return
*/
public static SessionWindows inactivityGap(final long inactivityGap)
/**
* Set the window maintain duration in milliseconds of streams time.
* This retention time is a guaranteed <i>lower bound</i> for how long
* a window will be maintained.
*
* @return itself
*/
public SessionWindows until(long durationMs)
} |
| Code Block | ||||
|---|---|---|---|---|
| ||||
/**
* The interface for merging aggregate values for {@link SessionWindows} with the given key
*
* @param <K> key type
* @param <T> aggregate value type
*/
public interface SessionMerger<K, T> {
/**
* Compute a new aggregate from the key and two aggregates
*
* @param aggKey the key of the record
* @param aggOne the first aggregate
* @param aggTwo the second aggregate
* @return the new aggregate value
*/
T apply(K aggKey, T aggOne, T aggTwo);
}
|
| Code Block | ||||
|---|---|---|---|---|
| ||||
/**
* Interface for storing the aggregated values of sessions
* @param <K> type of the record keys
* @param <AGG> type of the aggregated values
*/
public interface SessionStore<K, AGG> extends StateStore {
/**
* Fetch any aggregated session values with the matching key and where the
* session’s end time is >= earliestEndTime, i.e, the oldest session to
* merge with, and the session’s start time is <= latestStartTime, i.e,
* the newest session to merge with.
*/
KeyValueIterator<SessionKey<K>, AGG> fetch(final K key, final long earliestEndTime, final long latestStartTime);
/**
* Remove the aggregated value for the session with the matching SessionKey
*/
void remove(final SessionKey<K> sessionKey);
/**
* Write the aggregated result for the given SessionKey
*/
void put(final SessionKey<K> key, AGG result);
}
|
| Code Block | ||||
|---|---|---|---|---|
| ||||
/**
* Represents the key for a Session Window
*/
public class SessionKey<K> {
// record key
private final K key;
// session start time
private final long start;
// session end time
private final long end;
} |
Compatibility, Deprecation, and Migration Plan
None required as we are introducing new APIs only
Test Plan
The majority of this feature can be tested with unit tests, however we will write integration and/or system tests to cover the end-to-end scenarios.
Rejected Alternatives
Using the KeyValueStore to store the sessions. It would result in excessive IOs as we’d need to store a List per sessionId. So every lookup for a given sessionId would need to fetch and deserialize the list. Also, punctuate would need to retrieve every session every time it runs in order to determine those that need to be aggregated and forwarded.
Keeping the list of values in the store. Whilst this would result in us being able to use the existing Windows based API methods on KGroupedStream, it could result in excessive IO operations and possibly excessive storage use.
- Using punctuate to perform the aggregations and forward downstream. This would result in potentially fewer records being forwarded downstream as they would only be forwarded when a session is ‘closed’. However, it doesn’t align with the current approach in Kafka Streams, i.e., to use the cache for de-duplication and forward on commit, flush, or eviction (KIP-63). Further, punctuate currently depends on stream time and is will not be called in the absence of records.