THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
Following are the goals of this KIP:
- Provide appropriate configuration parameters to manage maximum memory usage during down-conversion on the broker.
- Reduce overall footprint of the down-conversion process, both in terms of memory usage and the time for which the required memory is held.
As we cap the memory usage, we’d inadvertently affect the throughput and latency characteristics. Lesser the amount of memory available for down-conversion, fewer messages can batched together in a single reply to the consumer. As fewer messages can be batched together, the consumer would require more round-trips to consume the same number of messages. We need a design that minimizes any impact on throughput and latency characteristics.
...
We will introduce a message chunking approach to reduce overall memory consumption during down-conversion. The idea is to lazily and incrementally down-convert messages "chunks" in a batched fashion, and send the result out to the consumer as soon as the chunk is ready. The broker continuously down-converts chunks of messages and sends them out, until it has exhausted all messages contained in the FetchResponse, or has reached some predetermined threshold. This way, we use a small, fixed deterministic amount of memory per FetchResponse.
...
The idea with the chunking approach is to tackle both of these inefficiencies. We want to make the allocation predictable, both in terms of amount of memory allocated as well as the amount of time for which the memory is kept referenced. The diagram below shows what down-conversion would look like with the chunking approach. The consumer still sees a single FetchResponse which is actually being sent out in a "streaming" fashion from the broker.
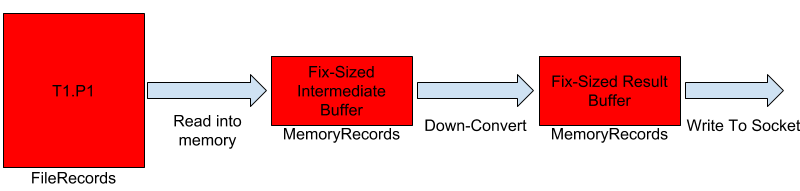 We
We
have two fix-sized, preallocated buffers for each FetchResponse. The network thread does the followingThe down-conversion process works as follows:
- Read a set of messages message batches from the particular log segment into the intermediate bufferinto memory.
- Down-convert all the message batches messages that were read into the result buffer.
- Write the result buffer to the underlying socket.
- Repeat till we have sent out all the messages, or have reached some a pre-determined threshold.
With this approach, we need temporary memory for to allocate a fixed amount of memory per response for the two fix-sized buffershold a batch of down-converted messages till they are completely sent out. We will limit the amount of memory required by limiting how many message batches are down-converted at a given point in time. A subtle difference also is the fact that we have managed to delay the memory allocation and the actual process of down-conversion till the network thread is actually ready to send out the results. Specifically, we can perform down-conversion when Records.writeTo is called.
...
Messages that require lazy down-conversion are encapsulated in a new class called LazyDownConvertedRecords. LazyDownConvertedRecords#writeTo will provide implementation for down-converting messages in chunks, and writing them to the underlying socket.
At a high level, LazyDownConvertRecords looks like the following:
| Code Block |
|---|
public class LazyDownConvertRecords implements Records {
/**
* Reference to records that will be "lazily" down-converted. Typically FileRecords.
*/
private final Records records;
/**
* Magic value to which above records need to be converted to.
*/
private final byte toMagic;
/**
* The starting offset of records.
*/
private final long firstOffset;
/**
* A "batch" of converted records.
*/
private ConvertedRecords<? extends Records> convertedRecords = null;
// Implementation for all methods in Records interface...
} |
Determining Total Response Size
...
This can be done by accepting an additional parameter doLazyConversion in KafkaApis#handleFetchRequest#convertedPartitionData which returns FetchResponse.PartitionData containing either LazyDownConvertedRecords or MemoryRecords depending on whether we want to delay down-conversion or not.
Sizing Intermediate and Result Buffers
Initially, the intermediate and result buffer will be sized as small as possible, with possibility to grow if the allocation is not sufficient to hold a single message batch.
...
Determining number of batches to down-convert
A limit will be placed on the size of messages down-converted at a given point in time (what forms a "chunk"). A chunk is formed by reading a maximum of 16kB of messages. We only add full message batches to the chunk. Note that we might have to exceed the 16kB limit if the first batch we are trying to read is larger than that.
...
Pros
- Fixed and deterministic memory usage for each down-conversion response.
- Significantly reduced duration for which down-converted messages are kept referenced in JVM heap.
- No change required to existing clients.
...