THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
This page is meant as a template for writing a KIP. To create a KIP choose Tools->Copy on this page and modify with your content and replace the heading with the next KIP number and a description of your issue. Replace anything in italics with your own description.
Status
Current state: Under Discussion
Discussion thread: here [Change the link from the KIP proposal email archive to your own email thread]
JIRA: here [Change the link from KAFKA-1 to your own ticket]
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
Consumer lag is a useful metric to monitor how many records are queued to be processed. We can look at individual lag per partition or we may aggregate metrics. For example, we may want to monitor what the maximum lag of any particular partition in our consumer subscription so we can identify hot partitions, caused by an insufficient producing partitioning strategy. We may want to monitor a sum of lag across all partitions so we have a sense as to our total backlog of messages to consume. Lag in offsets is useful when you have a good understanding of your messages and processing characteristics, but it doesn’t tell us how far behind in time we are. This is known as wait time in queueing theory, or more informally it’s referred to as latency.
The latency of a message can be defined as the difference between when that message was first produced to when the message is received by a consumer. The latency of records in a partition correlates with lag, but a larger lag doesn’t necessarily mean a larger latency. For example, a topic consumed by two separate application consumer groups A and B may have similar lag, but different latency per partition. Application A is a consumer which performs CPU intensive business logic on each message it receives. It’s distributed across many consumer group members to handle the load quickly enough, but since its processing time is slower, it takes longer to process each message per partition. Meanwhile, Application B is a consumer which performs a simple ETL operation to land streaming data in another system, such as HDFS. It may have similar lag to Application A, but because it has a faster processing time its latency per partition is significantly less.
If the Kafka Consumer reported a latency metric it would be easier to build Service Level Agreements (SLAs) based on non-functional requirements of the streaming system. For example, the system must never have a latency of greater than 10 minutes. This SLA could be used in monitoring alerts or as input to automatic scaling solutions.
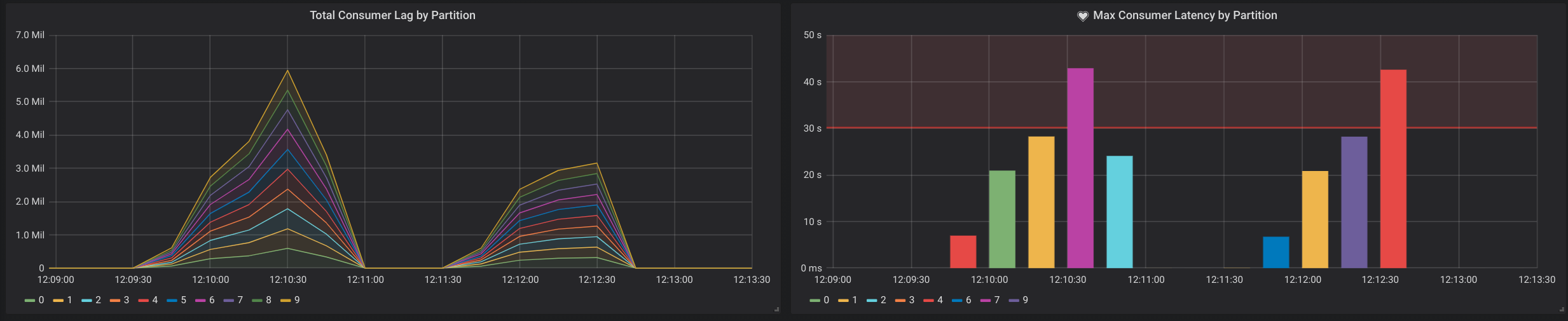
As an example, below is a screenshot of a Grafana dashboard with a panel for measuring the sum of consumer lag per partition on the LHS and a panel for measuring the top partition with the highest latency on the RHS. The latency panel also defines an alert that is triggered when latency exceeds 30 seconds over a 5 minute window.
Public Interfaces
Define new latency metrics under the Consumer Fetch Metrics metrics group.
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{client-id}"Attribute Name | Description |
records-latency-max | The maximum latency of any partition in this sample window for this client |
kafka.consumer:type=consumer-fetch-manager-metrics,partition="{partition}",topic="{topic}",client-id="{client-id}"Attribute Name | Description |
records-latency | The latest latency of the partition |
records-latency-max | The max latency of the partition |
records-latency-avg | The average latency of the partition |
Define a new optional Consumer property.
Name | Description | Type | Valid Values | Importance |
latency.time.class | Latency time class that implements | class | low |
Define an interface the user can implement to provide current wall clock time for latency.
public interface LatencyTime extends Configurable, Closeable {
/**
* Get wall clock time given a provided topic and partition. Return wall clock time as a
* UNIX epoch time in milliseconds of type long.
*/
public long getWallClockTime(TopicPartition tp);
/**
* This is called when the latency time implementation is closed
*/
public void close();
}
Proposed Changes
Report latency metrics in the Kafka Consumer at the client (max latency) and partition level, similar to how consumer lag is currently reported.
Since Kafka 0.10.0 the Kafka Producer will by default add a value for the timestamp property of a ProducerRecord unless it’s otherwise provided by the user. The default value is the current wallclock time represented as a unix epoch long in milliseconds returned by the Java Standard Library call to System.getCurrentMillis(). In the general case where we assume records are produced and consumed in the same timezone, the same network, and on machines with active clock synchronization services, then the latency may be calculated by taking the difference of current wall clock time with the timestamp from a fetched record.
To accommodate use cases where the user needs more control over the clock used to determine wall clock time (i.e. when the produced records are in a different timezone, or have their timestamps overridden) the user can configure a custom implementation of the interface org.apache.kafka.clients.consumer.LatencyTime to return the correct time for the latency calculation. This would be a class name configuration type provided by the user using consumer properties (ConfigDef.Type.CLASS).
The implementation to calculate latency would be very similar to how records-lag is implemented in Fetcher.fetchRecords and the FetchManagerRegistry. The latency metrics would be calculated once each poll for all partitions of records returned. The start timestamp will be extracted from the last record of each partition that is returned. To retrieve the current wall clock time it would use either a LatencyTime class implementation configured by the user, or the default implementation which returns System.getCurrentMillis(). The latency would be calculated by taking the difference of the wall clock time and the provided record start timestamp. The latency would be recorded by the client and partition sensors for the records-latency metric.
Compatibility, Deprecation, and Migration Plan
N/A
Rejected Alternatives
Use a Consumer Interceptor
An alternative solution to implementing this metric in the Kafka Consumer itself would be to implement it in a Consumer Interceptor and publish it as a library to the general Kafka community. This would require the library author to recreate a metrics implementation because the metrics system of the consumer cannot be reused. The simplest way would be to instantiate a new instance of org.apache.kafka.common.metrics.Metrics and configure it in a similar manner as the consumer configures its own internal instance. This would create a duplication of metrics configuration that could be avoided if it were implemented directly in the consumer.
Another reason the interceptor is not ideal is that some Kafka streaming integrations do not allow the user to configure interceptors, or otherwise restrict configuration properties passed to an underlying Kafka consumer. For example, the Spark Kafka integration will explicitly throw an exception when the user attempts to define interceptor.classes in the Kafka Consumer properties.
interceptor.classes: Kafka source always read keys and values as byte arrays. It’s not safe to use ConsumerInterceptor as it may break the query.
I have implemented this solution using a Consumer Interceptor and can share it if there’s interest.